 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision and Language Navigation in the Real World via Online Visual Language Mapping
Oct 16, 2023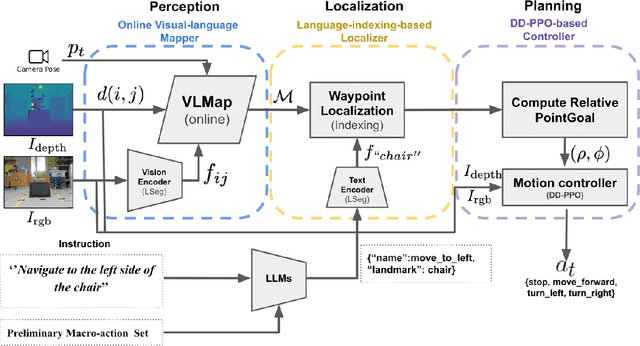


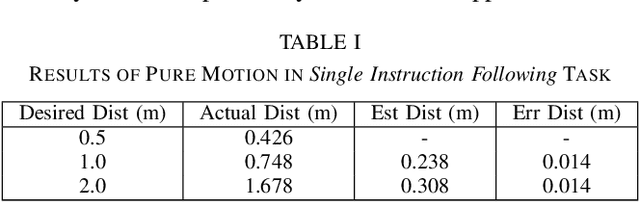
Navigating in unseen environments is crucial for mobile robots. Enhancing them with the ability to follow instructions in natural language will further improve navigation efficiency in unseen cases. However, state-of-the-art (SOTA) vision-and-language navigation (VLN) methods are mainly evaluated in simulation, neglecting the complex and noisy real world. Directly transferring SOTA navigation policies trained in simulation to the real world is challenging due to the visual domain gap and the absence of prior knowledge about unseen environments. In this work, we propose a novel navigation framework to address the VLN task in the real world. Utilizing the powerful foundation models, the proposed framework includes four key components: (1) an LLMs-based instruction parser that converts the language instruction into a sequence of pre-defined macro-action descriptions, (2) an online visual-language mapper that builds a real-time visual-language map to maintain a spatial and semantic understanding of the unseen environment, (3) a language indexing-based localizer that grounds each macro-action description into a waypoint location on the map, and (4) a DD-PPO-based local controller that predicts the action. We evaluate the proposed pipeline on an Interbotix LoCoBot WX250 in an unseen lab environment. Without any fine-tuning, our pipeline significantly outperforms the SOTA VLN baseline in the real world.
Hierarchical Robot Navigation in Novel Environments using Rough 2-D Maps
Jun 07, 2021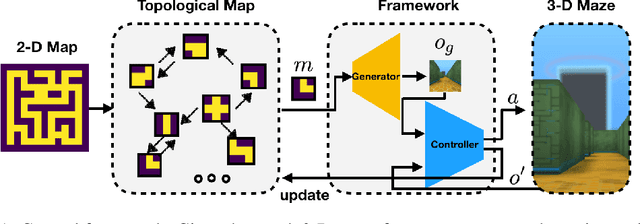

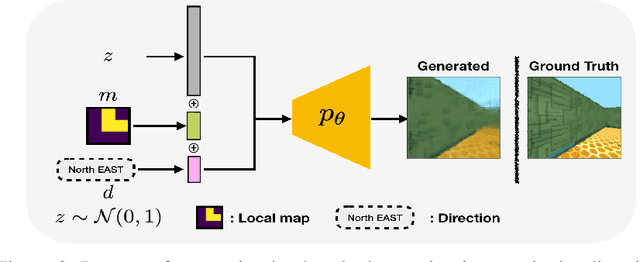
In robot navigation, generalizing quickly to unseen environments is essential. Hierarchical methods inspired by human navigation have been proposed, typically consisting of a high-level landmark proposer and a low-level controller. However, these methods either require precise high-level information to be given in advance or need to construct such guidance from extensive interaction with the environment. In this work, we propose an approach that leverages a rough 2-D map of the environment to navigate in novel environments without requiring further learning. In particular, we introduce a dynamic topological map that can be initialized from the rough 2-D map along with a high-level planning approach for proposing reachable 2-D map patches of the intermediate landmarks between the start and goal locations. To use proposed 2-D patches, we train a deep generative model to generate intermediate landmarks in observation space which are used as subgoals by low-level goal-conditioned reinforcement learning. Importantly, because the low-level controller is only trained with local behaviors (e.g. go across the intersection, turn left at a corner) on existing environments, this framework allows us to generalize to novel environments given only a rough 2-D map, without requiring further learning. Experimental results demonstrate the effectiveness of the proposed framework in both seen and novel environments.