 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision and Language Navigation in the Real World via Online Visual Language Mapping
Paper and Code
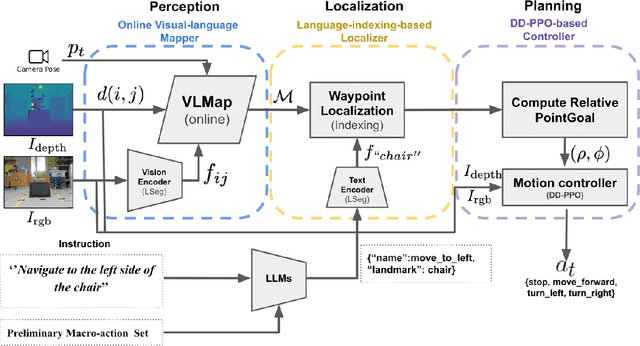


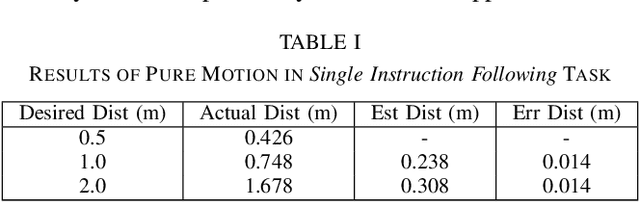
Navigating in unseen environments is crucial for mobile robots. Enhancing them with the ability to follow instructions in natural language will further improve navigation efficiency in unseen cases. However, state-of-the-art (SOTA) vision-and-language navigation (VLN) methods are mainly evaluated in simulation, neglecting the complex and noisy real world. Directly transferring SOTA navigation policies trained in simulation to the real world is challenging due to the visual domain gap and the absence of prior knowledge about unseen environments. In this work, we propose a novel navigation framework to address the VLN task in the real world. Utilizing the powerful foundation models, the proposed framework includes four key components: (1) an LLMs-based instruction parser that converts the language instruction into a sequence of pre-defined macro-action descriptions, (2) an online visual-language mapper that builds a real-time visual-language map to maintain a spatial and semantic understanding of the unseen environment, (3) a language indexing-based localizer that grounds each macro-action description into a waypoint location on the map, and (4) a DD-PPO-based local controller that predicts the action. We evaluate the proposed pipeline on an Interbotix LoCoBot WX250 in an unseen lab environment. Without any fine-tuning, our pipeline significantly outperforms the SOTA VLN baseline in the real world.