 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARO: Large Language Model Supervised Robotics Text2Skill Autonomous Learning
Mar 23, 2024



Robotics learning highly relies on human expertise and efforts, such as demonstrations, design of reward functions in reinforcement learning, performance evaluation using human feedback, etc. However, reliance on human assistance can lead to expensive learning costs and make skill learning difficult to scale. In this work, we introduce the Large Language Model Supervised Robotics Text2Skill Autonomous Learning (ARO) framework, which aims to replace human participation in the robot skill learning process with large-scale language models that incorporate reward function design and performance evaluation. We provide evidence that our approach enables fully autonomous robot skill learning, capable of completing partial tasks without human intervention. Furthermore, we also analyze the limitations of this approach in task understanding and optimization stability.
Super-Resolving Compressed Video in Coding Chain
Mar 26, 2021
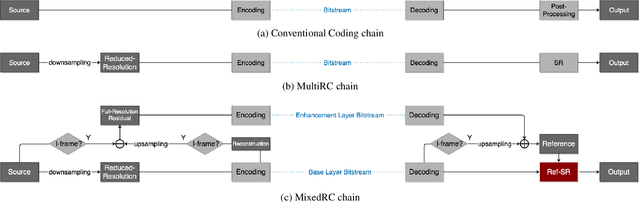

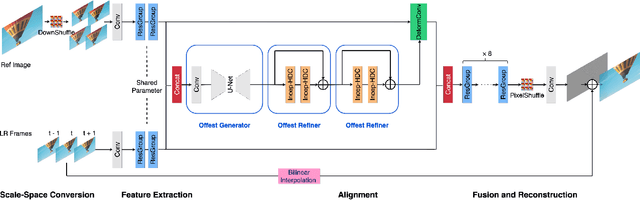
Scaling and lossy coding are widely used in video transmission and storage. Previous methods for enhancing the resolution of such videos often ignore the inherent interference between resolution loss and compression artifacts, which compromises perceptual video quality. To address this problem, we present a mixed-resolution coding framework, which cooperates with a reference-based DCNN. In this novel coding chain, the reference-based DCNN learns the direct mapping from low-resolution (LR) compressed video to their high-resolution (HR) clean version at the decoder side. We further improve reconstruction quality by devising an efficient deformable alignment module with receptive field block to handle various motion distances and introducing a disentangled loss that helps networks distinguish the artifact patterns from texture. Extensive experiments demonstrate the effectiveness of proposed innovations by comparing with state-of-the-art single image, video and reference-based restoration methods.