 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLagrangian Motion Fields for Long-term Motion Generation
Sep 03, 2024



Long-term motion generation is a challenging task that requires producing coherent and realistic sequences over extended durations. Current methods primarily rely on framewise motion representations, which capture only static spatial details and overlook temporal dynamics. This approach leads to significant redundancy across the temporal dimension, complicating the generation of effective long-term motion. To overcome these limitations, we introduce the novel concept of Lagrangian Motion Fields, specifically designed for long-term motion generation. By treating each joint as a Lagrangian particle with uniform velocity over short intervals, our approach condenses motion representations into a series of "supermotions" (analogous to superpixels). This method seamlessly integrates static spatial information with interpretable temporal dynamics, transcending the limitations of existing network architectures and motion sequence content types. Our solution is versatile and lightweight, eliminating the need for neural network preprocessing. Our approach excels in tasks such as long-term music-to-dance generation and text-to-motion generation, offering enhanced efficiency, superior generation quality, and greater diversity compared to existing methods. Additionally, the adaptability of Lagrangian Motion Fields extends to applications like infinite motion looping and fine-grained controlled motion generation, highlighting its broad utility. Video demonstrations are available at \url{https://plyfager.github.io/LaMoG}.
Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation
Apr 01, 2024
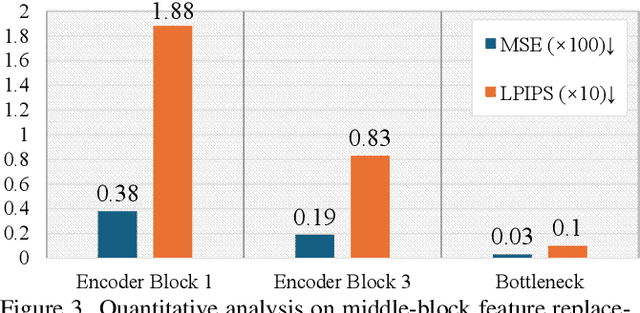
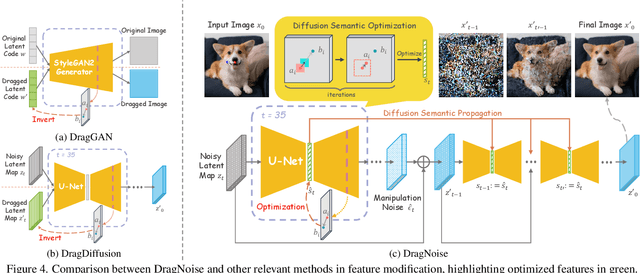

Point-based interactive editing serves as an essential tool to complement the controllability of existing generative models. A concurrent work, DragDiffusion, updates the diffusion latent map in response to user inputs, causing global latent map alterations. This results in imprecise preservation of the original content and unsuccessful editing due to gradient vanishing. In contrast, we present DragNoise, offering robust and accelerated editing without retracing the latent map. The core rationale of DragNoise lies in utilizing the predicted noise output of each U-Net as a semantic editor. This approach is grounded in two critical observations: firstly, the bottleneck features of U-Net inherently possess semantically rich features ideal for interactive editing; secondly, high-level semantics, established early in the denoising process, show minimal variation in subsequent stages. Leveraging these insights, DragNoise edits diffusion semantics in a single denoising step and efficiently propagates these changes, ensuring stability and efficiency in diffusion editing. Comparative experiments reveal that DragNoise achieves superior control and semantic retention, reducing the optimization time by over 50% compared to DragDiffusion. Our codes are available at https://github.com/haofengl/DragNoise.