 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Learning from Demonstrations by Learning from Experience
Paper and Code
Nov 16, 2021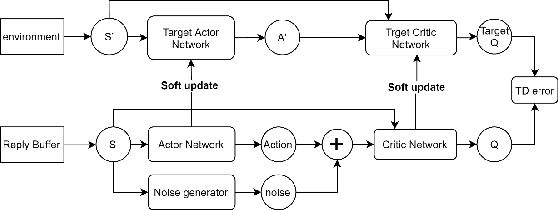
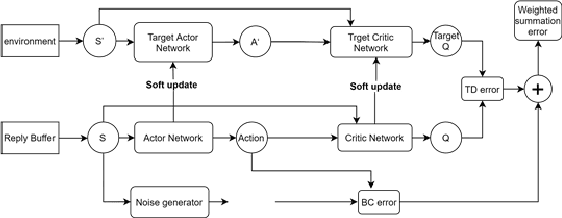
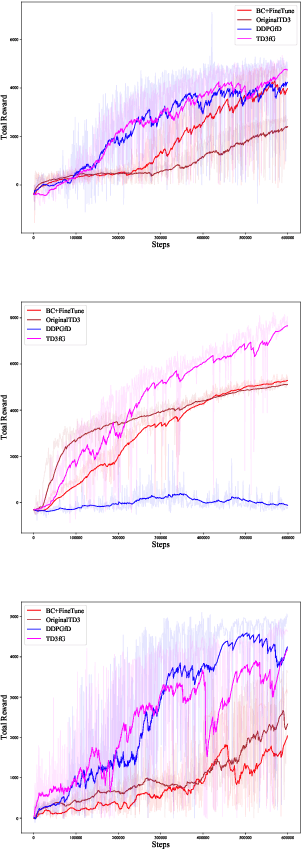
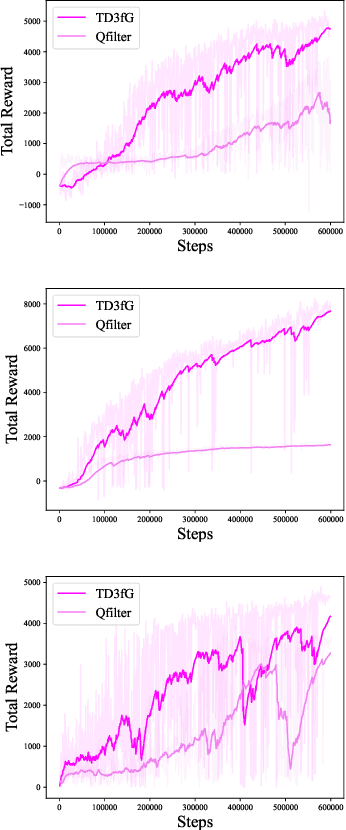
How to make imitation learning more general when demonstrations are relatively limited has been a persistent problem in reinforcement learning (RL). Poor demonstrations lead to narrow and biased date distribution, non-Markovian human expert demonstration makes it difficult for the agent to learn, and over-reliance on sub-optimal trajectories can make it hard for the agent to improve its performance. To solve these problems we propose a new algorithm named TD3fG that can smoothly transition from learning from experts to learning from experience. Our algorithm achieves good performance in the MUJOCO environment with limited and sub-optimal demonstrations. We use behavior cloning to train the network as a reference action generator and utilize it in terms of both loss function and exploration noise. This innovation can help agents extract a priori knowledge from demonstrations while reducing the detrimental effects of the poor Markovian properties of the demonstrations. It has a better performance compared to the BC+ fine-tuning and DDPGfD approach, especially when the demonstrations are relatively limited. We call our method TD3fG meaning TD3 from a generator.