 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Step by Step: Chain-of-Gesture Prompting for Error Detection in Robotic Surgical Videos
Jun 27, 2024



Despite significant advancements in robotic systems and surgical data science, ensuring safe and optimal execution in robot-assisted minimally invasive surgery (RMIS) remains a complex challenge. Current surgical error detection methods involve two parts: identifying surgical gestures and then detecting errors within each gesture clip. These methods seldom consider the rich contextual and semantic information inherent in surgical videos, limiting their performance due to reliance on accurate gesture identification. Motivated by the chain-of-thought prompting in natural language processing, this letter presents a novel and real-time end-to-end error detection framework, Chain-of-Thought (COG) prompting, leveraging contextual information from surgical videos. This encompasses two reasoning modules designed to mimic the decision-making processes of expert surgeons. Concretely, we first design a Gestural-Visual Reasoning module, which utilizes transformer and attention architectures for gesture prompting, while the second, a Multi-Scale Temporal Reasoning module, employs a multi-stage temporal convolutional network with both slow and fast paths for temporal information extraction. We extensively validate our method on the public benchmark RMIS dataset JIGSAWS. Our method encapsulates the reasoning processes inherent to surgical activities enabling it to outperform the state-of-the-art by 4.6% in F1 score, 4.6% in Accuracy, and 5.9% in Jaccard index while processing each frame in 6.69 milliseconds on average, demonstrating the great potential of our approach in enhancing the safety and efficacy of RMIS procedures and surgical education. The code will be available.
LDP-Net: An Unsupervised Pansharpening Network Based on Learnable Degradation Processes
Nov 24, 2021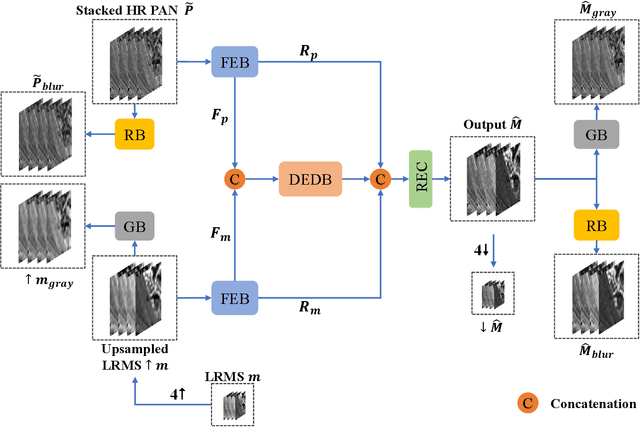
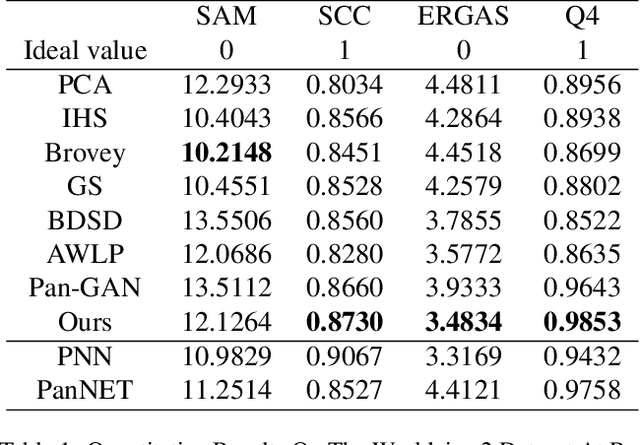
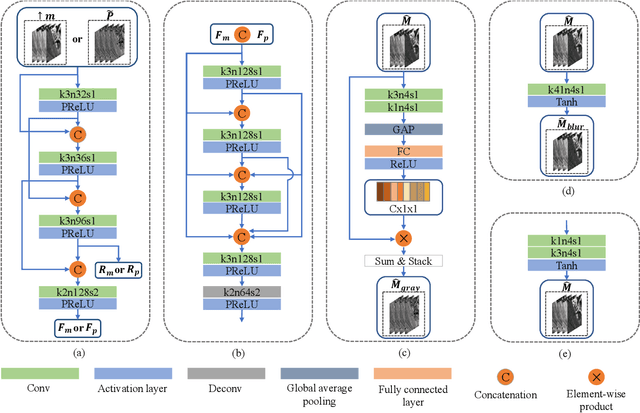
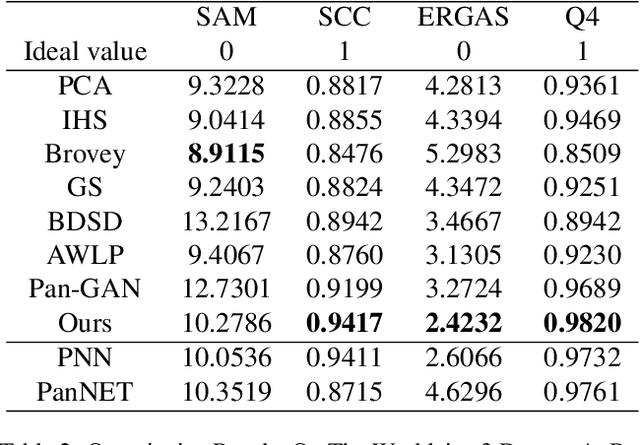
Pansharpening in remote sensing image aims at acquiring a high-resolution multispectral (HRMS) image directly by fusing a low-resolution multispectral (LRMS) image with a panchromatic (PAN) image. The main concern is how to effectively combine the rich spectral information of LRMS image with the abundant spatial information of PAN image. Recently, many methods based on deep learning have been proposed for the pansharpening task. However, these methods usually has two main drawbacks: 1) requiring HRMS for supervised learning; and 2) simply ignoring the latent relation between the MS and PAN image and fusing them directly. To solve these problems, we propose a novel unsupervised network based on learnable degradation processes, dubbed as LDP-Net. A reblurring block and a graying block are designed to learn the corresponding degradation processes, respectively. In addition, a novel hybrid loss function is proposed to constrain both spatial and spectral consistency between the pansharpened image and the PAN and LRMS images at different resolutions. Experiments on Worldview2 and Worldview3 images demonstrate that our proposed LDP-Net can fuse PAN and LRMS images effectively without the help of HRMS samples, achieving promising performance in terms of both qualitative visual effects and quantitative metrics.