 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe-DA: Contrastive Regression for Unsupervised Domain Adaptation in Surgical Skill Assessment
Mar 31, 2026Vision-based surgical skill assessment (SSA) enables objective and scalable evaluation of operative performance. Progress in this field is constrained by the high cost and time demands for manual annotation of quantitative skill scores, as well as the poor generalization of existing regression models to new surgical tasks and environments. Meanwhile, appreciable volumes of unlabeled video data are now available, motivating the development of unsupervised domain adaptation (UDA) methods for SSA. We introduce the first benchmark for UDA in SSA regression, spanning four datasets across dry-lab and clinical settings as well as open and robotic surgery. We evaluate eight representative models under challenging domain shifts and propose CoRe-DA, a novel contrastive regression-based adaptation framework. Our method learns domain-invariant representations through relative-score supervision and target-domain self-training. Comprehensive experiments across two UDA settings show that CoRe-DA is superior to state-of-the-art methods, achieving Spearman Correlation Coefficients of 0.46 and 0.41 on dry-lab and clinical target datasets, respectively, without using any labeled target data for training. Overall, CoRe-DA enables scalable SSA with reliable cross-domain generalization, where existing methods underperform. Our code and datasets will be released at https://github.com/anastadimi/CoRe-DA.
Exploring Pre-training Across Domains for Few-Shot Surgical Skill Assessment
Sep 11, 2025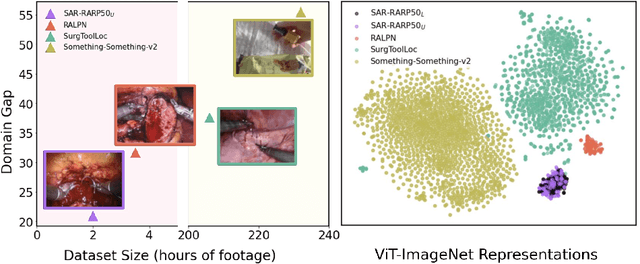

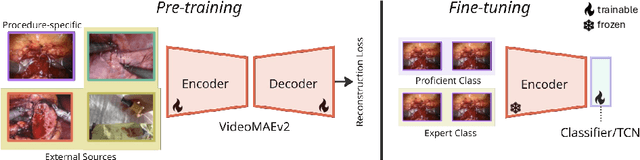
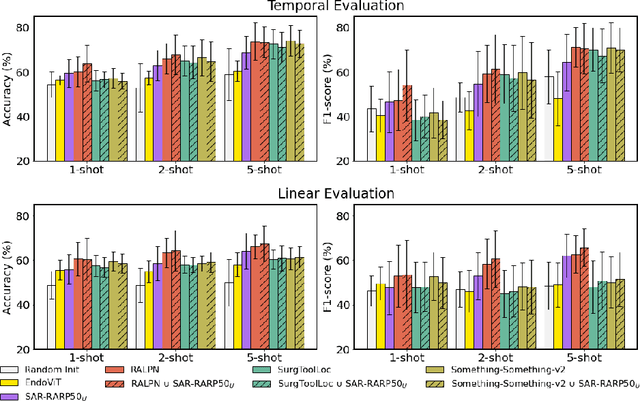
Automated surgical skill assessment (SSA) is a central task in surgical computer vision. Developing robust SSA models is challenging due to the scarcity of skill annotations, which are time-consuming to produce and require expert consensus. Few-shot learning (FSL) offers a scalable alternative enabling model development with minimal supervision, though its success critically depends on effective pre-training. While widely studied for several surgical downstream tasks, pre-training has remained largely unexplored in SSA. In this work, we formulate SSA as a few-shot task and investigate how self-supervised pre-training strategies affect downstream few-shot SSA performance. We annotate a publicly available robotic surgery dataset with Objective Structured Assessment of Technical Skill (OSATS) scores, and evaluate various pre-training sources across three few-shot settings. We quantify domain similarity and analyze how domain gap and the inclusion of procedure-specific data into pre-training influence transferability. Our results show that small but domain-relevant datasets can outperform large scale, less aligned ones, achieving accuracies of 60.16%, 66.03%, and 73.65% in the 1-, 2-, and 5-shot settings, respectively. Moreover, incorporating procedure-specific data into pre-training with a domain-relevant external dataset significantly boosts downstream performance, with an average gain of +1.22% in accuracy and +2.28% in F1-score; however, applying the same strategy with less similar but large-scale sources can instead lead to performance degradation. Code and models are available at https://github.com/anastadimi/ssa-fsl.
SegCol Challenge: Semantic Segmentation for Tools and Fold Edges in Colonoscopy data
Dec 20, 2024

Colorectal cancer (CRC) remains a leading cause of cancer-related deaths worldwide, with polyp removal being an effective early screening method. However, navigating the colon for thorough polyp detection poses significant challenges. To advance camera navigation in colonoscopy, we propose the Semantic Segmentation for Tools and Fold Edges in Colonoscopy (SegCol) Challenge. This challenge introduces a dataset from the EndoMapper repository, featuring manually annotated, pixel-level semantic labels for colon folds and endoscopic tools across selected frames from 96 colonoscopy videos. By providing fold edges as anatomical landmarks and depth discontinuity information from both fold and tool labels, the dataset is aimed to improve depth perception and localization methods. Hosted as part of the Endovis Challenge at MICCAI 2024, SegCol aims to drive innovation in colonoscopy navigation systems. Details are available at https://www.synapse.org/Synapse:syn54124209/wiki/626563, and code resources at https://github.com/surgical-vision/segcol_challenge .
HUP-3D: A 3D multi-view synthetic dataset for assisted-egocentric hand-ultrasound pose estimation
Jul 12, 2024



We present HUP-3D, a 3D multi-view multi-modal synthetic dataset for hand-ultrasound (US) probe pose estimation in the context of obstetric ultrasound. Egocentric markerless 3D joint pose estimation has potential applications in mixed reality based medical education. The ability to understand hand and probe movements programmatically opens the door to tailored guidance and mentoring applications. Our dataset consists of over 31k sets of RGB, depth and segmentation mask frames, including pose related ground truth data, with a strong emphasis on image diversity and complexity. Adopting a camera viewpoint-based sphere concept allows us to capture a variety of views and generate multiple hand grasp poses using a pre-trained network. Additionally, our approach includes a software-based image rendering concept, enhancing diversity with various hand and arm textures, lighting conditions, and background images. Furthermore, we validated our proposed dataset with state-of-the-art learning models and we obtained the lowest hand-object keypoint errors. The dataset and other details are provided with the supplementary material. The source code of our grasp generation and rendering pipeline will be made publicly available.
Federated Active Learning for Target Domain Generalisation
Dec 04, 2023In this paper, we introduce Active Learning framework in Federated Learning for Target Domain Generalisation, harnessing the strength from both learning paradigms. Our framework, FEDALV, composed of Active Learning (AL) and Federated Domain Generalisation (FDG), enables generalisation of an image classification model trained from limited source domain client's data without sharing images to an unseen target domain. To this end, our FDG, FEDA, consists of two optimisation updates during training, one at the client and another at the server level. For the client, the introduced losses aim to reduce feature complexity and condition alignment, while in the server, the regularisation limits free energy biases between source and target obtained by the global model. The remaining component of FEDAL is AL with variable budgets, which queries the server to retrieve and sample the most informative local data for the targeted client. We performed multiple experiments on FDG w/ and w/o AL and compared with both conventional FDG baselines and Federated Active Learning baselines. Our extensive quantitative experiments demonstrate the superiority of our method in accuracy and efficiency compared to the multiple contemporary methods. FEDALV manages to obtain the performance of the full training target accuracy while sampling as little as 5% of the source client's data.
MoBYv2AL: Self-supervised Active Learning for Image Classification
Jan 04, 2023Active learning(AL) has recently gained popularity for deep learning(DL) models. This is due to efficient and informative sampling, especially when the learner requires large-scale labelled datasets. Commonly, the sampling and training happen in stages while more batches are added. One main bottleneck in this strategy is the narrow representation learned by the model that affects the overall AL selection. We present MoBYv2AL, a novel self-supervised active learning framework for image classification. Our contribution lies in lifting MoBY, one of the most successful self-supervised learning algorithms, to the AL pipeline. Thus, we add the downstream task-aware objective function and optimize it jointly with contrastive loss. Further, we derive a data-distribution selection function from labelling the new examples. Finally, we test and study our pipeline robustness and performance for image classification tasks. We successfully achieved state-of-the-art results when compared to recent AL methods. Code available: https://github.com/razvancaramalau/MoBYv2AL
Visual Transformer for Task-aware Active Learning
Jun 07, 2021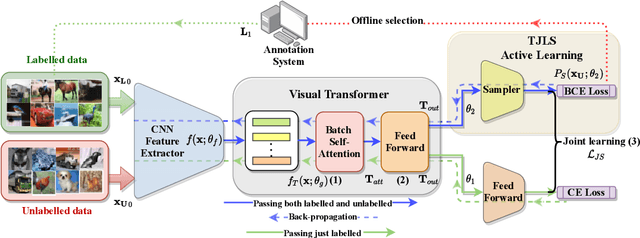

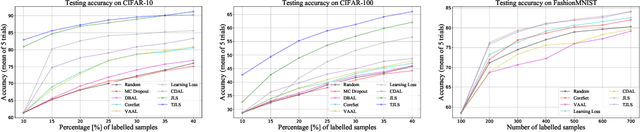
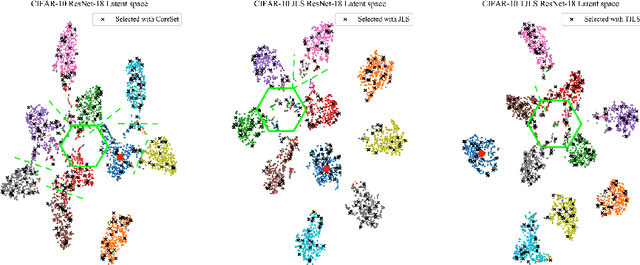
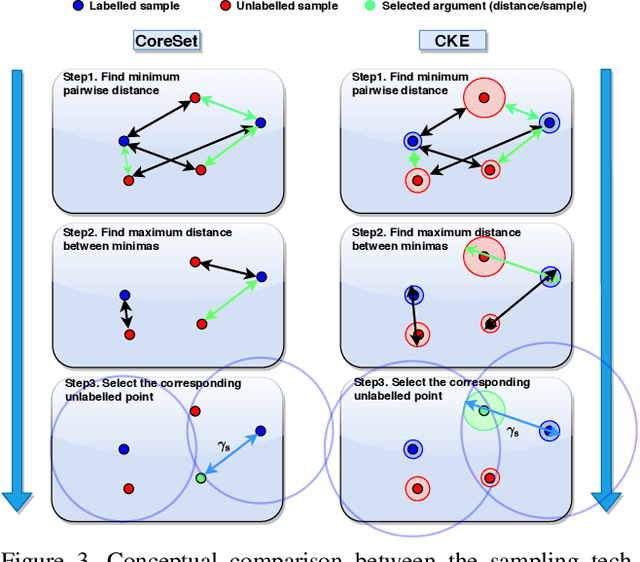
Pool-based sampling in active learning (AL) represents a key framework for an-notating informative data when dealing with deep learning models. In this paper, we present a novel pipeline for pool-based Active Learning. Unlike most previous works, our method exploits accessible unlabelled examples during training to estimate their co-relation with the labelled examples. Another contribution of this paper is to adapt Visual Transformer as a sampler in the AL pipeline. Visual Transformer models non-local visual concept dependency between labelled and unlabelled examples, which is crucial to identifying the influencing unlabelled examples. Also, compared to existing methods where the learner and the sampler are trained in a multi-stage manner, we propose to train them in a task-aware jointly manner which enables transforming the latent space into two separate tasks: one that classifies the labelled examples; the other that distinguishes the labelling direction. We evaluated our work on four different challenging benchmarks of classification and detection tasks viz. CIFAR10, CIFAR100,FashionMNIST, RaFD, and Pascal VOC 2007. Our extensive empirical and qualitative evaluations demonstrate the superiority of our method compared to the existing methods. Code available: https://github.com/razvancaramalau/Visual-Transformer-for-Task-aware-Active-Learning
Active Learning for Bayesian 3D Hand Pose Estimation
Oct 01, 2020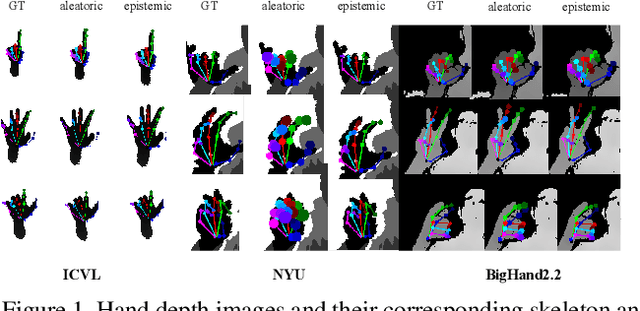


We propose a Bayesian approximation to a deep learning architecture for 3D hand pose estimation. Through this framework, we explore and analyse the two types of uncertainties that are influenced either by data or by the learning capability. Furthermore, we draw comparisons against the standard estimator over three popular benchmarks. The first contribution lies in outperforming the baseline while in the second part we address the active learning application. We also show that with a newly proposed acquisition function, our Bayesian 3D hand pose estimator obtains lowest errors with the least amount of data. The underlying code is publicly available at https://github.com/razvancaramalau/al_bhpe.
Sequential Graph Convolutional Network for Active Learning
Jun 18, 2020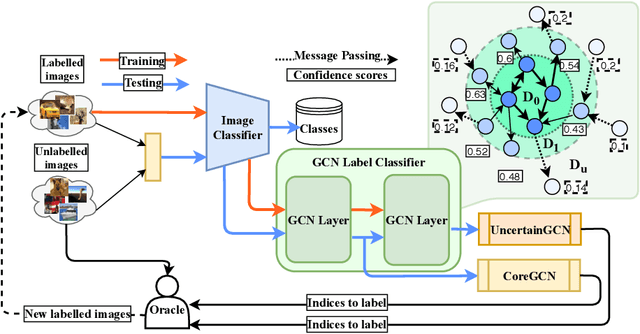

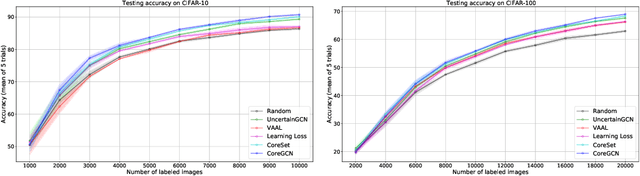
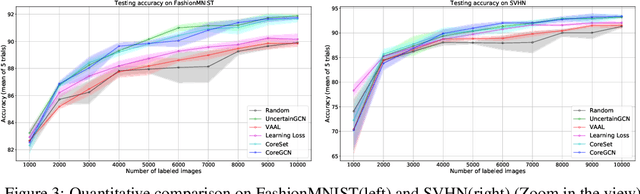
We propose a novel generic sequential Graph Convolution Network (GCN) training for Active Learning. Each of the unlabelled and labelled examples is represented through a pre-trained learner as nodes of a graph and their similarities as edges. With the available few labelled examples as seed annotations, the parameters of the Graphs are optimised to minimise the binary cross-entropy loss to identify labelled vs unlabelled. Based on the confidence score of the nodes in the graph we sub-sample unlabelled examples to annotate where inherited uncertainties correlate. With the newly annotated examples along with the existing ones, the parameters of the graph are optimised to minimise the modified objective. We evaluated our method on four publicly available image classification benchmarks. Our method outperforms several competitive baselines and existing arts. The implementations of this paper can be found here: https://github.com/razvancaramalau/Sequential-GCN-for-Active-Learning