 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can rate news outlet credibility
Paper and Code
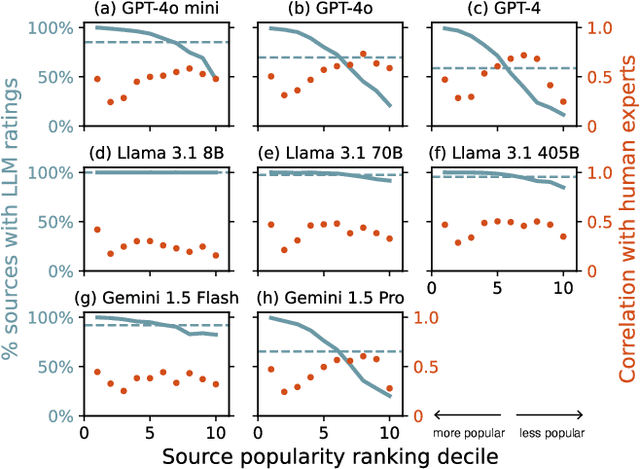
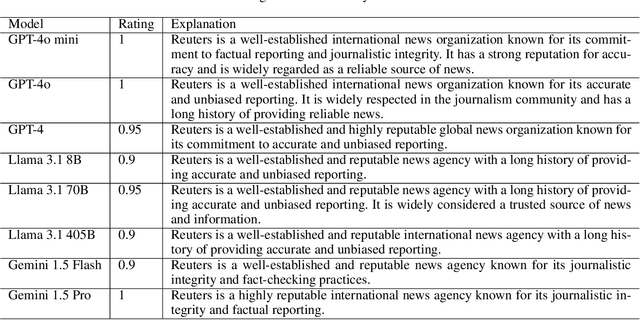
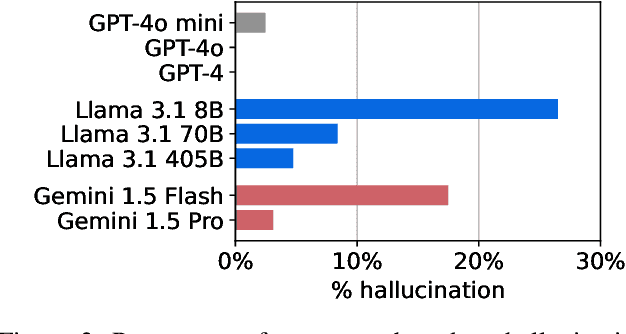

Although large language models (LLMs) have shown exceptional performance in various natural language processing tasks, they are prone to hallucinations. State-of-the-art chatbots, such as the new Bing, attempt to mitigate this issue by gathering information directly from the internet to ground their answers. In this setting, the capacity to distinguish trustworthy sources is critical for providing appropriate accuracy contexts to users. Here we assess whether ChatGPT, a prominent LLM, can evaluate the credibility of news outlets. With appropriate instructions, ChatGPT can provide ratings for a diverse set of news outlets, including those in non-English languages and satirical sources, along with contextual explanations. Our results show that these ratings correlate with those from human experts (Spearmam's $\rho=0.54, p<0.001$). These findings suggest that LLMs could be an affordable reference for credibility ratings in fact-checking applications. Future LLMs should enhance their alignment with human expert judgments of source credibility to improve information accuracy.