 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks
Paper and Code

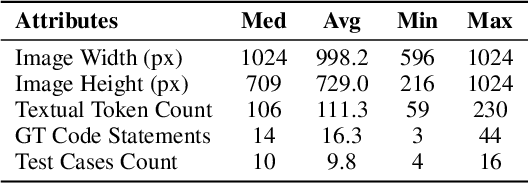

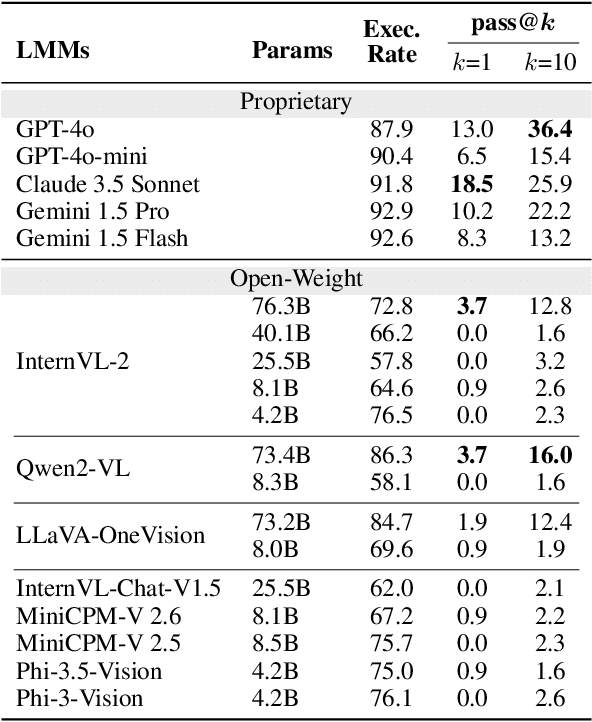
Coding tasks have been valuable for evaluating Large Language Models (LLMs), as they demand the comprehension of high-level instructions, complex reasoning, and the implementation of functional programs -- core capabilities for advancing Artificial General Intelligence. Despite the progress in Large Multimodal Models (LMMs), which extend LLMs with visual perception and understanding capabilities, there remains a notable lack of coding benchmarks that rigorously assess these models, particularly in tasks that emphasize visual reasoning. To address this gap, we introduce HumanEval-V, a novel and lightweight benchmark specifically designed to evaluate LMMs' visual understanding and reasoning capabilities through code generation. HumanEval-V includes 108 carefully crafted, entry-level Python coding tasks derived from platforms like CodeForces and Stack Overflow. Each task is adapted by modifying the context and algorithmic patterns of the original problems, with visual elements redrawn to ensure distinction from the source, preventing potential data leakage. LMMs are required to complete the code solution based on the provided visual context and a predefined Python function signature outlining the task requirements. Every task is equipped with meticulously handcrafted test cases to ensure a thorough and reliable evaluation of model-generated solutions. We evaluate 19 state-of-the-art LMMs using HumanEval-V, uncovering significant challenges. Proprietary models like GPT-4o achieve only 13% pass@1 and 36.4% pass@10, while open-weight models with 70B parameters score below 4% pass@1. Ablation studies further reveal the limitations of current LMMs in vision reasoning and coding capabilities. These results underscore key areas for future research to enhance LMMs' capabilities. We have open-sourced our code and benchmark at https://github.com/HumanEval-V/HumanEval-V-Benchmark.