 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearner-Tailored Program Repair: A Solution Generator with Iterative Edit-Driven Retrieval Enhancement
Jan 13, 2026With the development of large language models (LLMs) in the field of programming, intelligent programming coaching systems have gained widespread attention. However, most research focuses on repairing the buggy code of programming learners without providing the underlying causes of the bugs. To address this gap, we introduce a novel task, namely \textbf{LPR} (\textbf{L}earner-Tailored \textbf{P}rogram \textbf{R}epair). We then propose a novel and effective framework, \textbf{\textsc{\MethodName{}}} (\textbf{L}earner-Tailored \textbf{S}olution \textbf{G}enerator), to enhance program repair while offering the bug descriptions for the buggy code. In the first stage, we utilize a repair solution retrieval framework to construct a solution retrieval database and then employ an edit-driven code retrieval approach to retrieve valuable solutions, guiding LLMs in identifying and fixing the bugs in buggy code. In the second stage, we propose a solution-guided program repair method, which fixes the code and provides explanations under the guidance of retrieval solutions. Moreover, we propose an Iterative Retrieval Enhancement method that utilizes evaluation results of the generated code to iteratively optimize the retrieval direction and explore more suitable repair strategies, improving performance in practical programming coaching scenarios. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our framework for the newly proposed LPR task.
Less is More: Adaptive Program Repair with Bug Localization and Preference Learning
Mar 09, 2025Automated Program Repair (APR) is a task to automatically generate patches for the buggy code. However, most research focuses on generating correct patches while ignoring the consistency between the fixed code and the original buggy code. How to conduct adaptive bug fixing and generate patches with minimal modifications have seldom been investigated. To bridge this gap, we first introduce a novel task, namely AdaPR (Adaptive Program Repair). We then propose a two-stage approach AdaPatcher (Adaptive Patch Generator) to enhance program repair while maintaining the consistency. In the first stage, we utilize a Bug Locator with self-debug learning to accurately pinpoint bug locations. In the second stage, we train a Program Modifier to ensure consistency between the post-modified fixed code and the pre-modified buggy code. The Program Modifier is enhanced with a location-aware repair learning strategy to generate patches based on identified buggy lines, a hybrid training strategy for selective reference and an adaptive preference learning to prioritize fewer changes. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our two-stage framework for the newly proposed AdaPR task.
MPCODER: Multi-user Personalized Code Generator with Explicit and Implicit Style Representation Learning
Jun 25, 2024


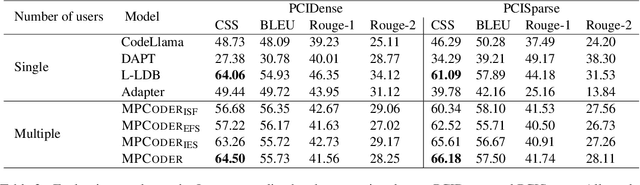
Large Language Models (LLMs) have demonstrated great potential for assisting developers in their daily development. However, most research focuses on generating correct code, how to use LLMs to generate personalized code has seldom been investigated. To bridge this gap, we proposed MPCoder (Multi-user Personalized Code Generator) to generate personalized code for multiple users. To better learn coding style features, we utilize explicit coding style residual learning to capture the syntax code style standards and implicit style learning to capture the semantic code style conventions. We train a multi-user style adapter to better differentiate the implicit feature representations of different users through contrastive learning, ultimately enabling personalized code generation for multiple users. We further propose a novel evaluation metric for estimating similarities between codes of different coding styles. The experimental results show the effectiveness of our approach for this novel task.