 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-Modal Contrastive Losses with Applications to Social Media Data in Trimodal Space
Paper and Code
Mar 18, 2024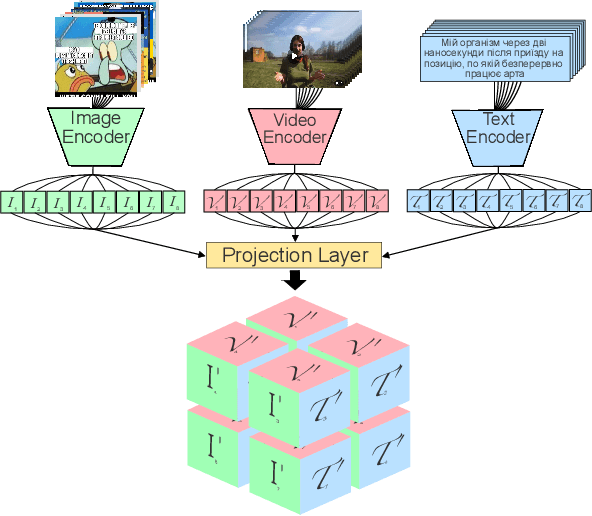

The social media landscape of conflict dynamics has grown increasingly multi-modal. Recent advancements in model architectures such as CLIP have enabled researchers to begin studying the interplay between the modalities of text and images in a shared latent space. However, CLIP models fail to handle situations on social media when modalities present in a post expand above two. Social media dynamics often require understanding the interplay between not only text and images, but video as well. In this paper we explore an extension of the contrastive loss function to allow for any number of modalities, and demonstrate its usefulness in trimodal spaces on social media. By extending CLIP into three dimensions we can further aide understanding social media landscapes where all three modalities are present (an increasingly common situation). We use a newly collected public data set of Telegram posts containing all three modalities to train, and then demonstrate the usefulness of, a trimodal model in two OSINT scenarios: classifying a social media artifact post as either pro-Russian or pro-Ukrainian and identifying which account a given artifact originated from. While trimodal CLIP models have been explored before (though not on social media data), we also display a novel quadmodal CLIP model. This model can learn the interplay between text, image, video, and audio. We demonstrate new state-of-the-art baseline results on retrieval for quadmodel models moving forward.