 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Information from Observations with Uncertainty and Novelty
Jan 16, 2025

A machine learning tasks from observations must encounter and process uncertainty and novelty, especially when it is expected to maintain performance when observing new information and to choose the best fitting hypothesis to the currently observed information. In this context, some key questions arise: what is information, how much information did the observations provide, how much information is required to identify the data-generating process, how many observations remain to get that information, and how does a predictor determine that it has observed novel information? This paper strengthens existing answers to these questions by formalizing the notion of "identifiable information" that arises from the language used to express the relationship between distinct states. Model identifiability and sample complexity are defined via computation of an indicator function over a set of hypotheses. Their properties and asymptotic statistics are described for data-generating processes ranging from deterministic processes to ergodic stationary stochastic processes. This connects the notion of identifying information in finite steps with asymptotic statistics and PAC-learning. The indicator function's computation naturally formalizes novel information and its identification from observations with respect to a hypothesis set. We also proved that computable PAC-Bayes learners' sample complexity distribution is determined by its moments in terms of the the prior probability distribution over a fixed finite hypothesis set.
Human Activity Recognition in an Open World
Dec 23, 2022
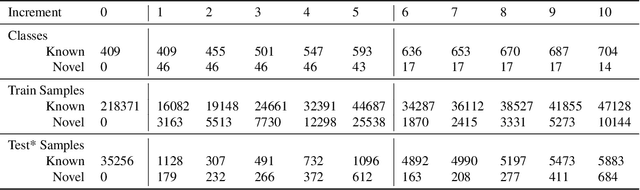

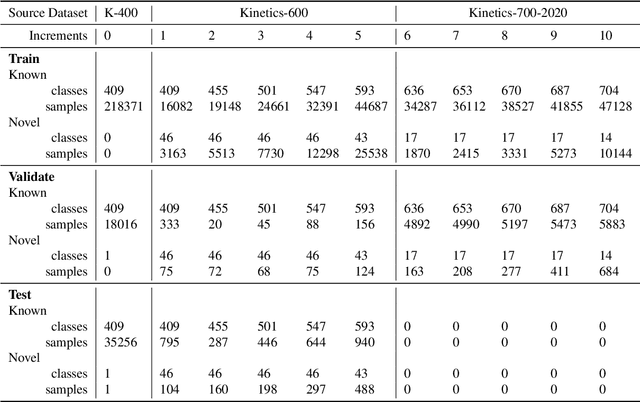
Managing novelty in perception-based human activity recognition (HAR) is critical in realistic settings to improve task performance over time and ensure solution generalization outside of prior seen samples. Novelty manifests in HAR as unseen samples, activities, objects, environments, and sensor changes, among other ways. Novelty may be task-relevant, such as a new class or new features, or task-irrelevant resulting in nuisance novelty, such as never before seen noise, blur, or distorted video recordings. To perform HAR optimally, algorithmic solutions must be tolerant to nuisance novelty, and learn over time in the face of novelty. This paper 1) formalizes the definition of novelty in HAR building upon the prior definition of novelty in classification tasks, 2) proposes an incremental open world learning (OWL) protocol and applies it to the Kinetics datasets to generate a new benchmark KOWL-718, 3) analyzes the performance of current state-of-the-art HAR models when novelty is introduced over time, 4) provides a containerized and packaged pipeline for reproducing the OWL protocol and for modifying for any future updates to Kinetics. The experimental analysis includes an ablation study of how the different models perform under various conditions as annotated by Kinetics-AVA. The protocol as an algorithm for reproducing experiments using the KOWL-718 benchmark will be publicly released with code and containers at https://github.com/prijatelj/human-activity-recognition-in-an-open-world. The code may be used to analyze different annotations and subsets of the Kinetics datasets in an incremental open world fashion, as well as be extended as further updates to Kinetics are released.
Handwriting Recognition with Novelty
May 17, 2021
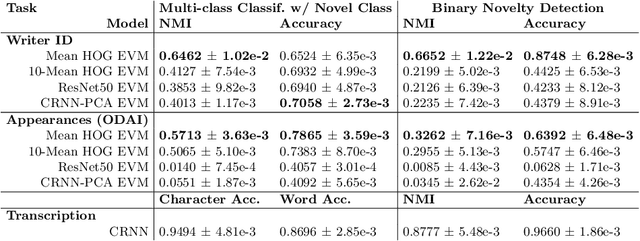

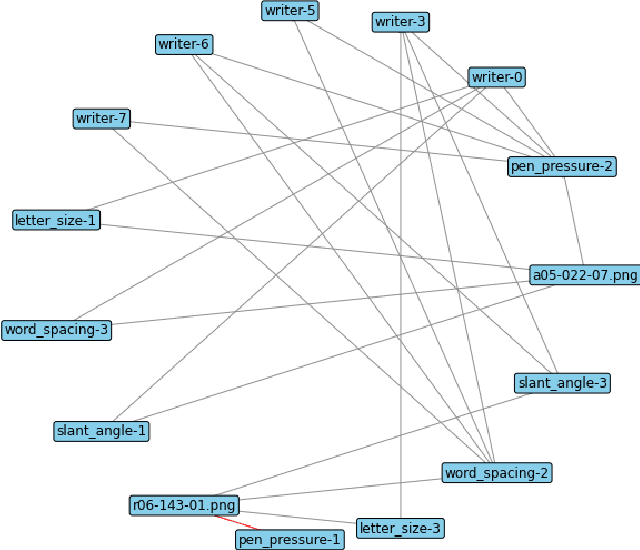
This paper introduces an agent-centric approach to handle novelty in the visual recognition domain of handwriting recognition (HWR). An ideal transcription agent would rival or surpass human perception, being able to recognize known and new characters in an image, and detect any stylistic changes that may occur within or across documents. A key confound is the presence of novelty, which has continued to stymie even the best machine learning-based algorithms for these tasks. In handwritten documents, novelty can be a change in writer, character attributes, writing attributes, or overall document appearance, among other things. Instead of looking at each aspect independently, we suggest that an integrated agent that can process known characters and novelties simultaneously is a better strategy. This paper formalizes the domain of handwriting recognition with novelty, describes a baseline agent, introduces an evaluation protocol with benchmark data, and provides experimentation to set the state-of-the-art. Results show feasibility for the agent-centric approach, but more work is needed to approach human-levels of reading ability, giving the HWR community a formal basis to build upon as they solve this challenging problem.
A Bayesian Evaluation Framework for Ground Truth-Free Visual Recognition Tasks
Jun 20, 2020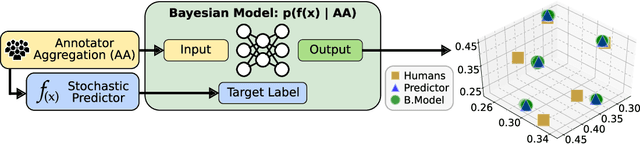

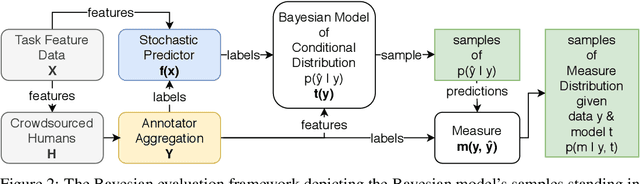

An interesting development in automatic visual recognition has been the emergence of tasks where it is not possible to assign ground truth labels to images, yet still feasible to collect annotations that reflect human judgements about them. Such tasks include subjective visual attribute assignment and the labeling of ambiguous scenes. Machine learning-based predictors for these tasks rely on supervised training that models the behavior of the annotators, e.g., what would the average person's judgement be for an image? A key open question for this type of work, especially for applications where inconsistency with human behavior can lead to ethical lapses, is how to evaluate the uncertainty of trained predictors. Given that the real answer is unknowable, we are left with often noisy judgements from human annotators to work with. In order to account for the uncertainty that is present, we propose a relative Bayesian framework for evaluating predictors trained on such data. The framework specifies how to estimate a predictor's uncertainty due to the human labels by approximating a conditional distribution and producing a credible interval for the predictions and their measures of performance. The framework is successfully applied to four image classification tasks that use subjective human judgements: facial beauty assessment using the SCUT-FBP5500 dataset, social attribute assignment using data from TestMyBrain.org, apparent age estimation using data from the ChaLearn series of challenges, and ambiguous scene labeling using the LabelMe dataset.