 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntipatterns in Software Classification Taxonomies
Paper and Code

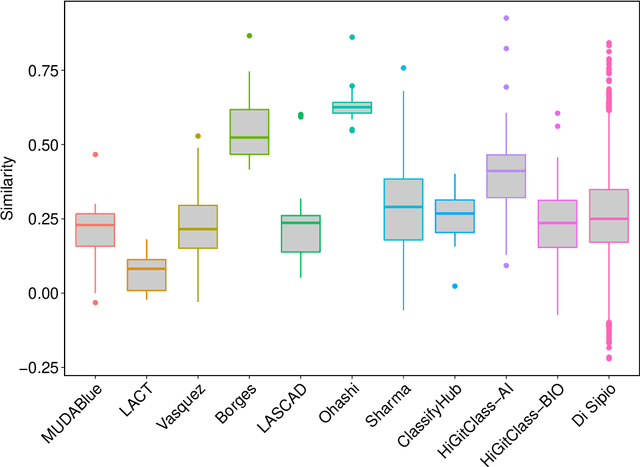
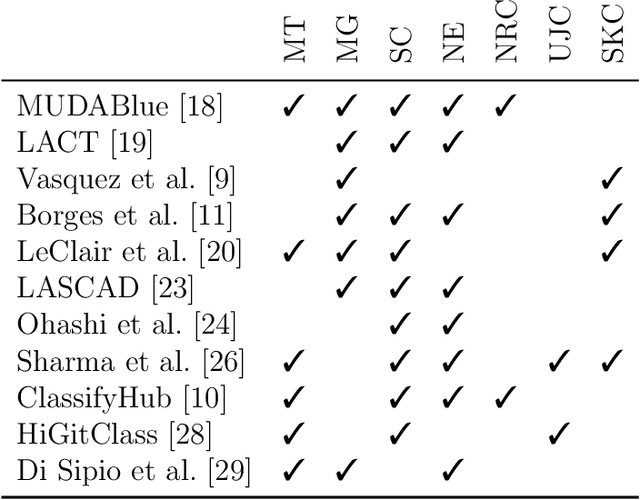
Empirical results in software engineering have long started to show that findings are unlikely to be applicable to all software systems, or any domain: results need to be evaluated in specified contexts, and limited to the type of systems that they were extracted from. This is a known issue, and requires the establishment of a classification of software types. This paper makes two contributions: the first is to evaluate the quality of the current software classifications landscape. The second is to perform a case study showing how to create a classification of software types using a curated set of software systems. Our contributions show that existing, and very likely even new, classification attempts are deemed to fail for one or more issues, that we named as the `antipatterns' of software classification tasks. We collected 7 of these antipatterns that emerge from both our case study, and the existing classifications. These antipatterns represent recurring issues in a classification, so we discuss practical ways to help researchers avoid these pitfalls. It becomes clear that classification attempts must also face the daunting task of formulating a taxonomy of software types, with the objective of establishing a hierarchy of categories in a classification.