 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitRanking: A Ranking of GitHub Topics for Software Classification using Active Sampling
May 19, 2022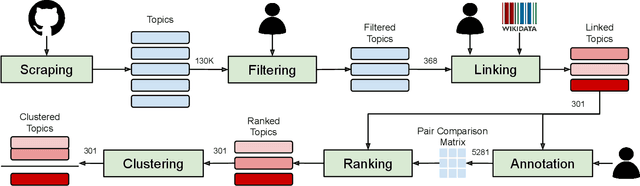
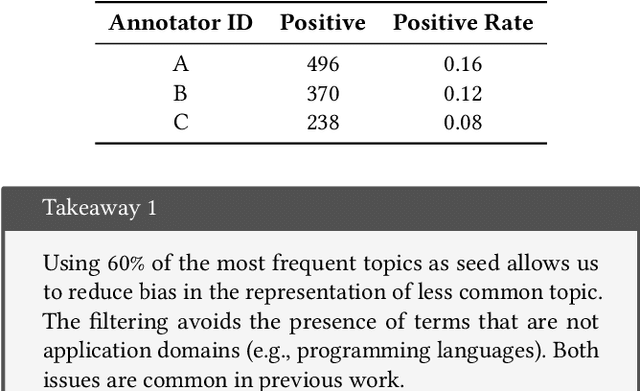


GitHub is the world's largest host of source code, with more than 150M repositories. However, most of these repositories are not labeled or inadequately so, making it harder for users to find relevant projects. There have been various proposals for software application domain classification over the past years. However, these approaches lack a well-defined taxonomy that is hierarchical, grounded in a knowledge base, and free of irrelevant terms. This work proposes GitRanking, a framework for creating a classification ranked into discrete levels based on how general or specific their meaning is. We collected 121K topics from GitHub and considered $60\%$ of the most frequent ones for the ranking. GitRanking 1) uses active sampling to ensure a minimal number of required annotations; and 2) links each topic to Wikidata, reducing ambiguities and improving the reusability of the taxonomy. Our results show that developers, when annotating their projects, avoid using terms with a high degree of specificity. This makes the finding and discovery of their projects more challenging for other users. Furthermore, we show that GitRanking can effectively rank terms according to their general or specific meaning. This ranking would be an essential asset for developers to build upon, allowing them to complement their annotations with more precise topics. Finally, we show that GitRanking is a dynamically extensible method: it can currently accept further terms to be ranked with a minimum number of annotations ($\sim$ 15). This paper is the first collective attempt to build a ground-up taxonomy of software domains.
Antipatterns in Software Classification Taxonomies
Apr 19, 2022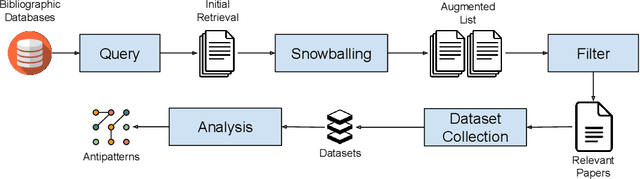

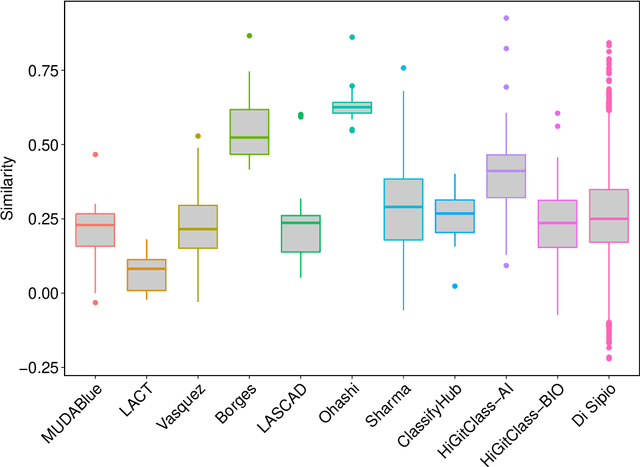
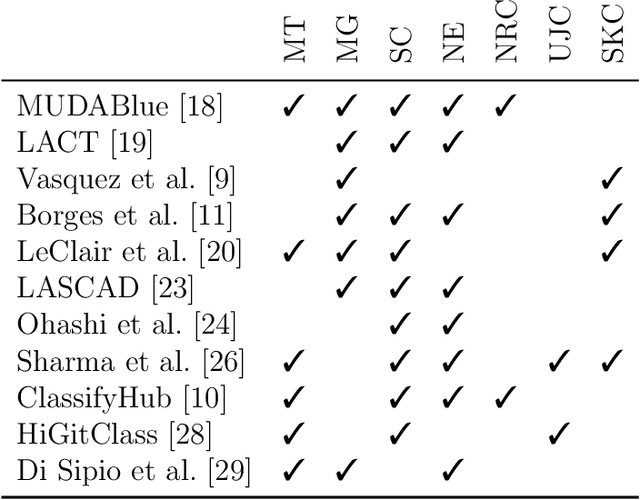
Empirical results in software engineering have long started to show that findings are unlikely to be applicable to all software systems, or any domain: results need to be evaluated in specified contexts, and limited to the type of systems that they were extracted from. This is a known issue, and requires the establishment of a classification of software types. This paper makes two contributions: the first is to evaluate the quality of the current software classifications landscape. The second is to perform a case study showing how to create a classification of software types using a curated set of software systems. Our contributions show that existing, and very likely even new, classification attempts are deemed to fail for one or more issues, that we named as the `antipatterns' of software classification tasks. We collected 7 of these antipatterns that emerge from both our case study, and the existing classifications. These antipatterns represent recurring issues in a classification, so we discuss practical ways to help researchers avoid these pitfalls. It becomes clear that classification attempts must also face the daunting task of formulating a taxonomy of software types, with the objective of establishing a hierarchy of categories in a classification.
LabelGit: A Dataset for Software Repositories Classification using Attributed Dependency Graphs
Mar 16, 2021

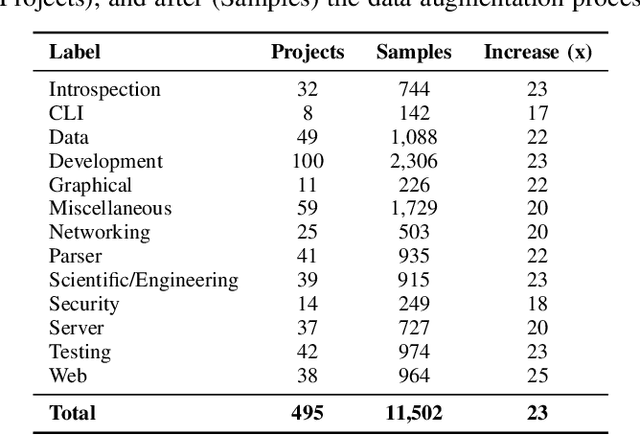
Software repository hosting services contain large amounts of open-source software, with GitHub hosting more than 100 million repositories, from new to established ones. Given this vast amount of projects, there is a pressing need for a search based on the software's content and features. However, even though GitHub offers various solutions to aid software discovery, most repositories do not have any labels, reducing the utility of search and topic-based analysis. Moreover, classifying software modules is also getting more importance given the increase in Component-Based Software Development. However, previous work focused on software classification using keyword-based approaches or proxies for the project (e.g., README), which is not always available. In this work, we create a new annotated dataset of GitHub Java projects called LabelGit. Our dataset uses direct information from the source code, like the dependency graph and source code neural representations from the identifiers. Using this dataset, we hope to aid the development of solutions that do not rely on proxies but use the entire source code to perform classification.
X-WikiRE: A Large, Multilingual Resource for Relation Extraction as Machine Comprehension
Aug 15, 2019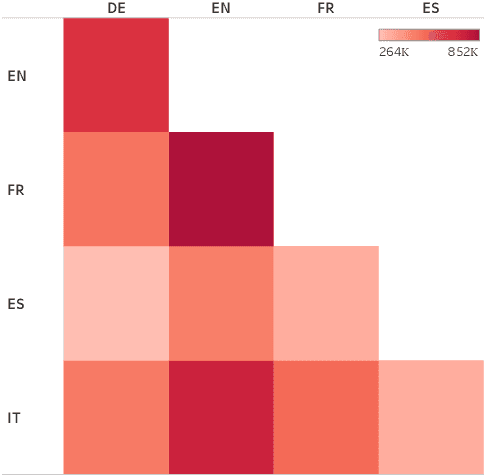

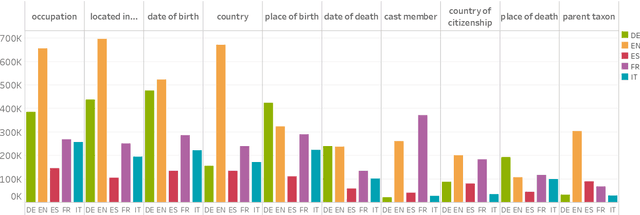
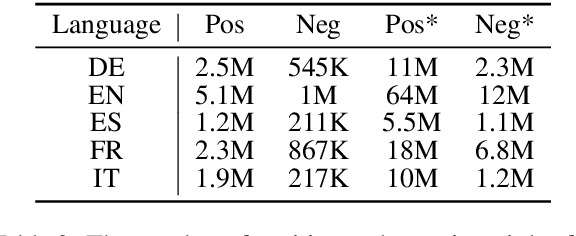
Although the vast majority of knowledge bases KBs are heavily biased towards English, Wikipedias do cover very different topics in different languages. Exploiting this, we introduce a new multilingual dataset (X-WikiRE), framing relation extraction as a multilingual machine reading problem. We show that by leveraging this resource it is possible to robustly transfer models cross-lingually and that multilingual support significantly improves (zero-shot) relation extraction, enabling the population of low-resourced KBs from their well-populated counterparts.