 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning and Data Augmentation for Detecting Self-Admitted Technical Debt
Oct 21, 2024Self-Admitted Technical Debt (SATD) refers to circumstances where developers use textual artifacts to explain why the existing implementation is not optimal. Past research in detecting SATD has focused on either identifying SATD (classifying SATD items as SATD or not) or categorizing SATD (labeling instances as SATD that pertain to requirement, design, code, test debt, etc.). However, the performance of these approaches remains suboptimal, particularly for specific types of SATD, such as test and requirement debt, primarily due to extremely imbalanced datasets. To address these challenges, we build on earlier research by utilizing BiLSTM architecture for the binary identification of SATD and BERT architecture for categorizing different types of SATD. Despite their effectiveness, both architectures struggle with imbalanced data. Therefore, we employ a large language model data augmentation strategy to mitigate this issue. Furthermore, we introduce a two-step approach to identify and categorize SATD across various datasets derived from different artifacts. Our contributions include providing a balanced dataset for future SATD researchers and demonstrating that our approach significantly improves SATD identification and categorization performance compared to baseline methods.
Automatically Estimating the Effort Required to Repay Self-Admitted Technical Debt
Sep 12, 2023Technical debt refers to the consequences of sub-optimal decisions made during software development that prioritize short-term benefits over long-term maintainability. Self-Admitted Technical Debt (SATD) is a specific form of technical debt, explicitly documented by developers within software artifacts such as source code comments and commit messages. As SATD can hinder software development and maintenance, it is crucial to address and prioritize it effectively. However, current methodologies lack the ability to automatically estimate the repayment effort of SATD based on its textual descriptions. To address this limitation, we propose a novel approach for automatically estimating SATD repayment effort, utilizing a comprehensive dataset comprising 341,740 SATD items from 2,568,728 commits across 1,060 Apache repositories. Our findings show that different types of SATD require varying levels of repayment effort, with code/design, requirement, and test debt demanding greater effort compared to non-SATD items, while documentation debt requires less. We introduce and evaluate machine learning methodologies, particularly BERT and TextCNN, which outperforms classic machine learning methods and the naive baseline in estimating repayment effort. Additionally, we summarize keywords associated with varying levels of repayment effort that occur during SATD repayment. Our contributions aim to enhance the prioritization of SATD repayment effort and resource allocation efficiency, ultimately benefiting software development and maintainability.
Automatically Identifying Relations Between Self-Admitted Technical Debt Across Different Sources
Mar 13, 2023Self-Admitted Technical Debt or SATD can be found in various sources, such as source code comments, commit messages, issue tracking systems, and pull requests. Previous research has established the existence of relations between SATD items in different sources; such relations can be useful for investigating and improving SATD management. However, there is currently a lack of approaches for automatically detecting these SATD relations. To address this, we proposed and evaluated approaches for automatically identifying SATD relations across different sources. Our findings show that our approach outperforms baseline approaches by a large margin, achieving an average F1-score of 0.829 in identifying relations between SATD items. Moreover, we explored the characteristics of SATD relations in 103 open-source projects and describe nine major cases in which related SATD is documented in a second source, and give a quantitative overview of 26 kinds of relations.
Automatic Identification of Self-Admitted Technical Debt from Different Sources
Feb 04, 2022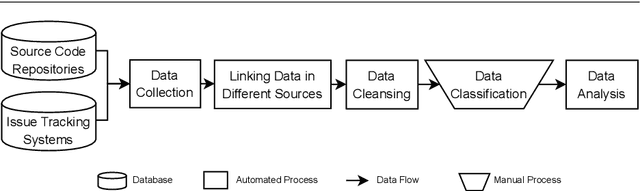

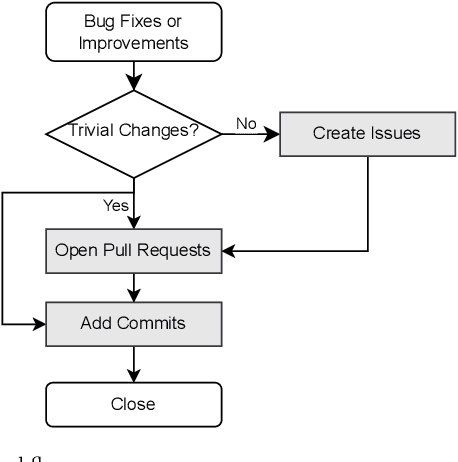
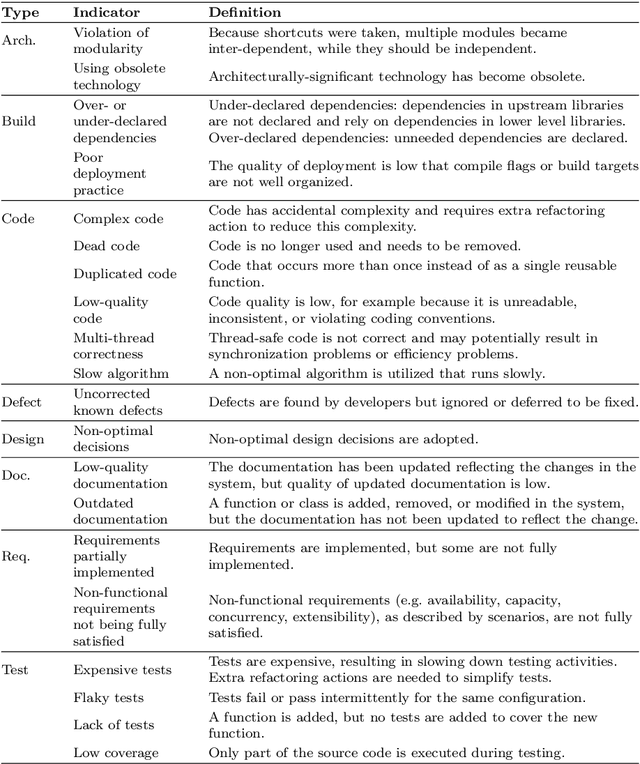
Technical debt is a metaphor describing the situation that long-term benefits (e.g., maintainability and evolvability of software) are traded for short-term goals. When technical debt is admitted explicitly by developers in software artifacts (e.g., code comments or issue tracking systems), it is termed as Self-Admitted Technical Debt or SATD. Technical debt could be admitted in different sources, such as source code comments, issue tracking systems, pull requests, and commit messages. However, there is no approach proposed for identifying SATD from different sources. Thus, in this paper, we propose an approach for automatically identifying SATD from different sources (i.e., source code comments, issue trackers, commit messages, and pull requests).
Identifying Self-Admitted Technical Debt in Issue Tracking Systems using Machine Learning
Feb 04, 2022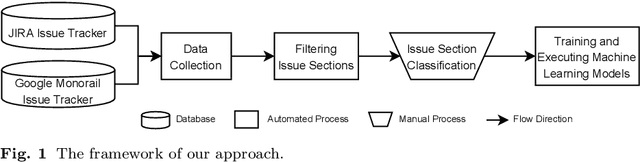



Technical debt is a metaphor indicating sub-optimal solutions implemented for short-term benefits by sacrificing the long-term maintainability and evolvability of software. A special type of technical debt is explicitly admitted by software engineers (e.g. using a TODO comment); this is called Self-Admitted Technical Debt or SATD. Most work on automatically identifying SATD focuses on source code comments. In addition to source code comments, issue tracking systems have shown to be another rich source of SATD, but there are no approaches specifically for automatically identifying SATD in issues. In this paper, we first create a training dataset by collecting and manually analyzing 4,200 issues (that break down to 23,180 sections of issues) from seven open-source projects (i.e., Camel, Chromium, Gerrit, Hadoop, HBase, Impala, and Thrift) using two popular issue tracking systems (i.e., Jira and Google Monorail). We then propose and optimize an approach for automatically identifying SATD in issue tracking systems using machine learning. Our findings indicate that: 1) our approach outperforms baseline approaches by a wide margin with regard to the F1-score; 2) transferring knowledge from suitable datasets can improve the predictive performance of our approach; 3) extracted SATD keywords are intuitive and potentially indicating types and indicators of SATD; 4) projects using different issue tracking systems have less common SATD keywords compared to projects using the same issue tracking system; 5) a small amount of training data is needed to achieve good accuracy.