 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Self-Admitted Technical Debt in Issue Tracking Systems using Machine Learning
Paper and Code
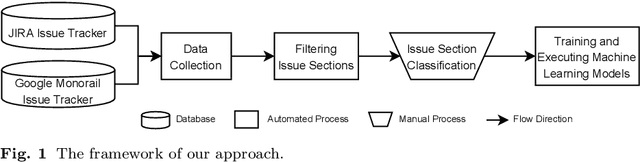



Technical debt is a metaphor indicating sub-optimal solutions implemented for short-term benefits by sacrificing the long-term maintainability and evolvability of software. A special type of technical debt is explicitly admitted by software engineers (e.g. using a TODO comment); this is called Self-Admitted Technical Debt or SATD. Most work on automatically identifying SATD focuses on source code comments. In addition to source code comments, issue tracking systems have shown to be another rich source of SATD, but there are no approaches specifically for automatically identifying SATD in issues. In this paper, we first create a training dataset by collecting and manually analyzing 4,200 issues (that break down to 23,180 sections of issues) from seven open-source projects (i.e., Camel, Chromium, Gerrit, Hadoop, HBase, Impala, and Thrift) using two popular issue tracking systems (i.e., Jira and Google Monorail). We then propose and optimize an approach for automatically identifying SATD in issue tracking systems using machine learning. Our findings indicate that: 1) our approach outperforms baseline approaches by a wide margin with regard to the F1-score; 2) transferring knowledge from suitable datasets can improve the predictive performance of our approach; 3) extracted SATD keywords are intuitive and potentially indicating types and indicators of SATD; 4) projects using different issue tracking systems have less common SATD keywords compared to projects using the same issue tracking system; 5) a small amount of training data is needed to achieve good accuracy.