 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODKE+: Ontology-Guided Open-Domain Knowledge Extraction with LLMs
Sep 04, 2025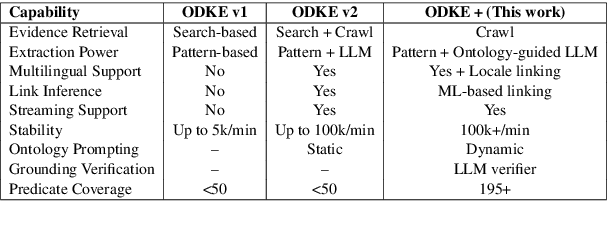
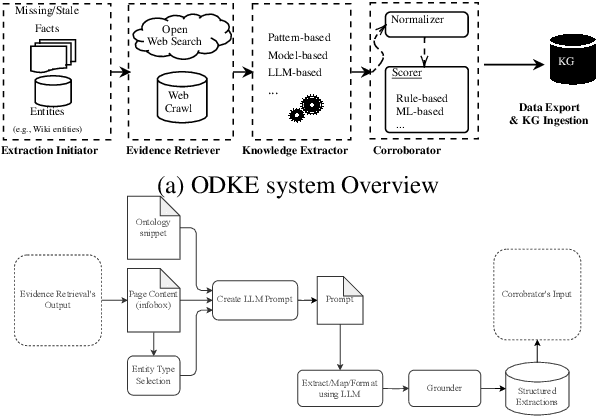
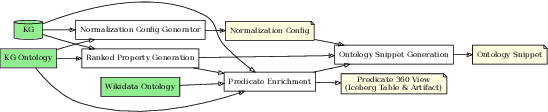

Knowledge graphs (KGs) are foundational to many AI applications, but maintaining their freshness and completeness remains costly. We present ODKE+, a production-grade system that automatically extracts and ingests millions of open-domain facts from web sources with high precision. ODKE+ combines modular components into a scalable pipeline: (1) the Extraction Initiator detects missing or stale facts, (2) the Evidence Retriever collects supporting documents, (3) hybrid Knowledge Extractors apply both pattern-based rules and ontology-guided prompting for large language models (LLMs), (4) a lightweight Grounder validates extracted facts using a second LLM, and (5) the Corroborator ranks and normalizes candidate facts for ingestion. ODKE+ dynamically generates ontology snippets tailored to each entity type to align extractions with schema constraints, enabling scalable, type-consistent fact extraction across 195 predicates. The system supports batch and streaming modes, processing over 9 million Wikipedia pages and ingesting 19 million high-confidence facts with 98.8% precision. ODKE+ significantly improves coverage over traditional methods, achieving up to 48% overlap with third-party KGs and reducing update lag by 50 days on average. Our deployment demonstrates that LLM-based extraction, grounded in ontological structure and verification workflows, can deliver trustworthiness, production-scale knowledge ingestion with broad real-world applicability. A recording of the system demonstration is included with the submission and is also available at https://youtu.be/UcnE3_GsTWs.
Automatically Estimating the Effort Required to Repay Self-Admitted Technical Debt
Sep 12, 2023Technical debt refers to the consequences of sub-optimal decisions made during software development that prioritize short-term benefits over long-term maintainability. Self-Admitted Technical Debt (SATD) is a specific form of technical debt, explicitly documented by developers within software artifacts such as source code comments and commit messages. As SATD can hinder software development and maintenance, it is crucial to address and prioritize it effectively. However, current methodologies lack the ability to automatically estimate the repayment effort of SATD based on its textual descriptions. To address this limitation, we propose a novel approach for automatically estimating SATD repayment effort, utilizing a comprehensive dataset comprising 341,740 SATD items from 2,568,728 commits across 1,060 Apache repositories. Our findings show that different types of SATD require varying levels of repayment effort, with code/design, requirement, and test debt demanding greater effort compared to non-SATD items, while documentation debt requires less. We introduce and evaluate machine learning methodologies, particularly BERT and TextCNN, which outperforms classic machine learning methods and the naive baseline in estimating repayment effort. Additionally, we summarize keywords associated with varying levels of repayment effort that occur during SATD repayment. Our contributions aim to enhance the prioritization of SATD repayment effort and resource allocation efficiency, ultimately benefiting software development and maintainability.
Automatically Identifying Relations Between Self-Admitted Technical Debt Across Different Sources
Mar 13, 2023Self-Admitted Technical Debt or SATD can be found in various sources, such as source code comments, commit messages, issue tracking systems, and pull requests. Previous research has established the existence of relations between SATD items in different sources; such relations can be useful for investigating and improving SATD management. However, there is currently a lack of approaches for automatically detecting these SATD relations. To address this, we proposed and evaluated approaches for automatically identifying SATD relations across different sources. Our findings show that our approach outperforms baseline approaches by a large margin, achieving an average F1-score of 0.829 in identifying relations between SATD items. Moreover, we explored the characteristics of SATD relations in 103 open-source projects and describe nine major cases in which related SATD is documented in a second source, and give a quantitative overview of 26 kinds of relations.
Saga: A Platform for Continuous Construction and Serving of Knowledge At Scale
Apr 15, 2022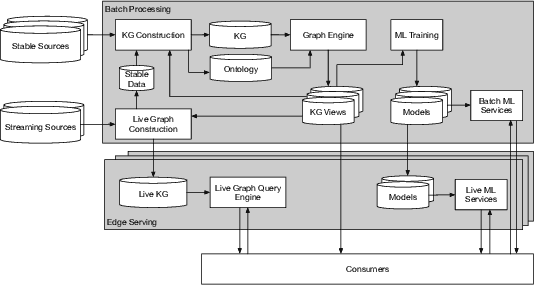
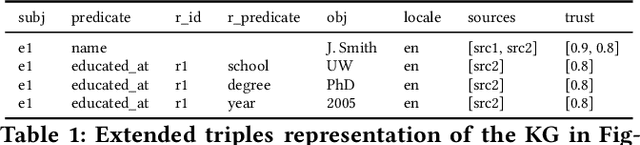
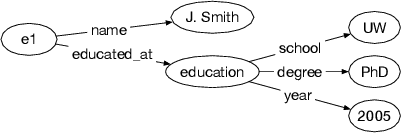
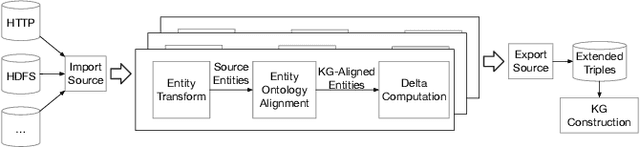
We introduce Saga, a next-generation knowledge construction and serving platform for powering knowledge-based applications at industrial scale. Saga follows a hybrid batch-incremental design to continuously integrate billions of facts about real-world entities and construct a central knowledge graph that supports multiple production use cases with diverse requirements around data freshness, accuracy, and availability. In this paper, we discuss the unique challenges associated with knowledge graph construction at industrial scale, and review the main components of Saga and how they address these challenges. Finally, we share lessons-learned from a wide array of production use cases powered by Saga.
Automatic Identification of Self-Admitted Technical Debt from Different Sources
Feb 04, 2022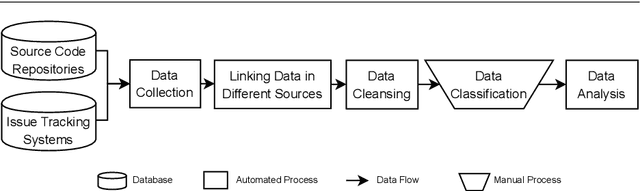

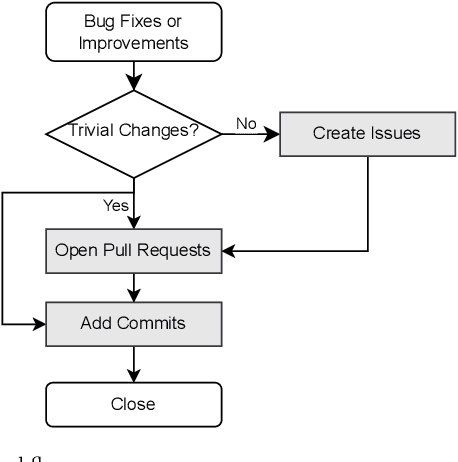
Technical debt is a metaphor describing the situation that long-term benefits (e.g., maintainability and evolvability of software) are traded for short-term goals. When technical debt is admitted explicitly by developers in software artifacts (e.g., code comments or issue tracking systems), it is termed as Self-Admitted Technical Debt or SATD. Technical debt could be admitted in different sources, such as source code comments, issue tracking systems, pull requests, and commit messages. However, there is no approach proposed for identifying SATD from different sources. Thus, in this paper, we propose an approach for automatically identifying SATD from different sources (i.e., source code comments, issue trackers, commit messages, and pull requests).
Identifying Self-Admitted Technical Debt in Issue Tracking Systems using Machine Learning
Feb 04, 2022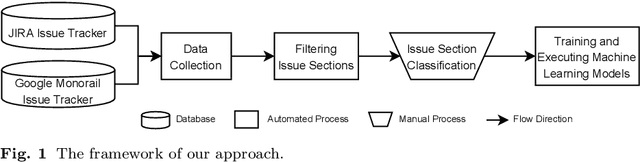



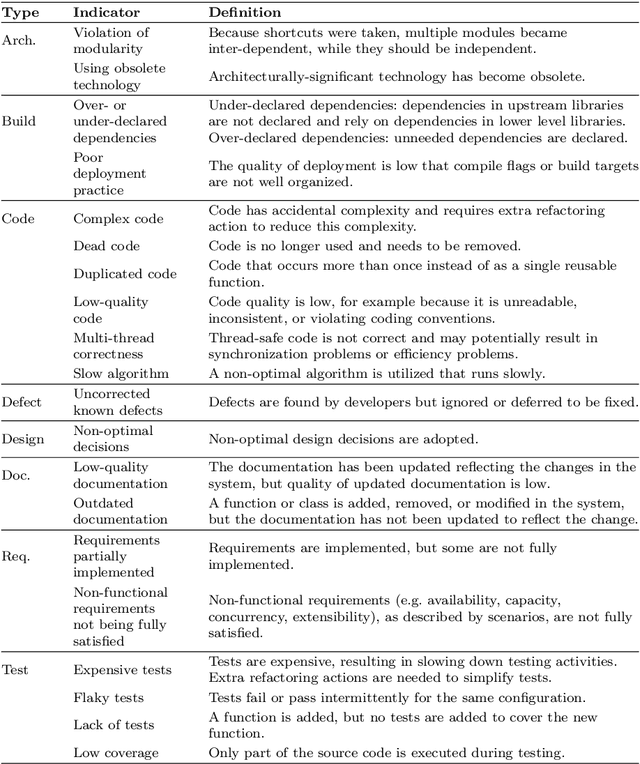
Technical debt is a metaphor indicating sub-optimal solutions implemented for short-term benefits by sacrificing the long-term maintainability and evolvability of software. A special type of technical debt is explicitly admitted by software engineers (e.g. using a TODO comment); this is called Self-Admitted Technical Debt or SATD. Most work on automatically identifying SATD focuses on source code comments. In addition to source code comments, issue tracking systems have shown to be another rich source of SATD, but there are no approaches specifically for automatically identifying SATD in issues. In this paper, we first create a training dataset by collecting and manually analyzing 4,200 issues (that break down to 23,180 sections of issues) from seven open-source projects (i.e., Camel, Chromium, Gerrit, Hadoop, HBase, Impala, and Thrift) using two popular issue tracking systems (i.e., Jira and Google Monorail). We then propose and optimize an approach for automatically identifying SATD in issue tracking systems using machine learning. Our findings indicate that: 1) our approach outperforms baseline approaches by a wide margin with regard to the F1-score; 2) transferring knowledge from suitable datasets can improve the predictive performance of our approach; 3) extracted SATD keywords are intuitive and potentially indicating types and indicators of SATD; 4) projects using different issue tracking systems have less common SATD keywords compared to projects using the same issue tracking system; 5) a small amount of training data is needed to achieve good accuracy.