 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAST-Probe: Recovering abstract syntax trees from hidden representations of pre-trained language models
Paper and Code
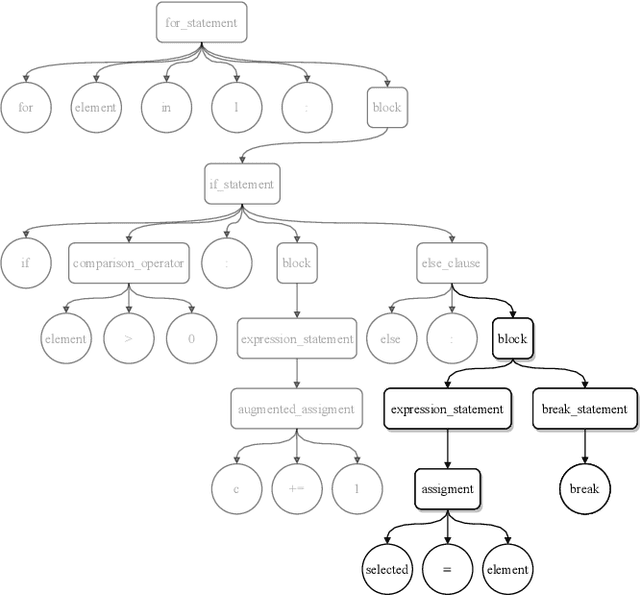
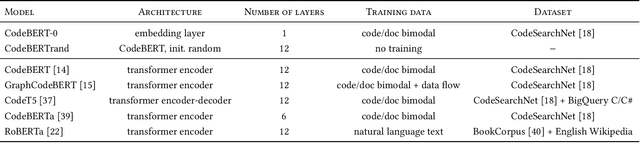
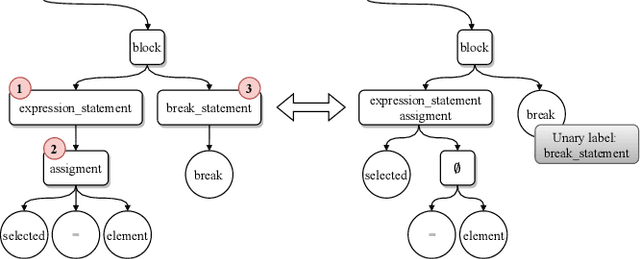
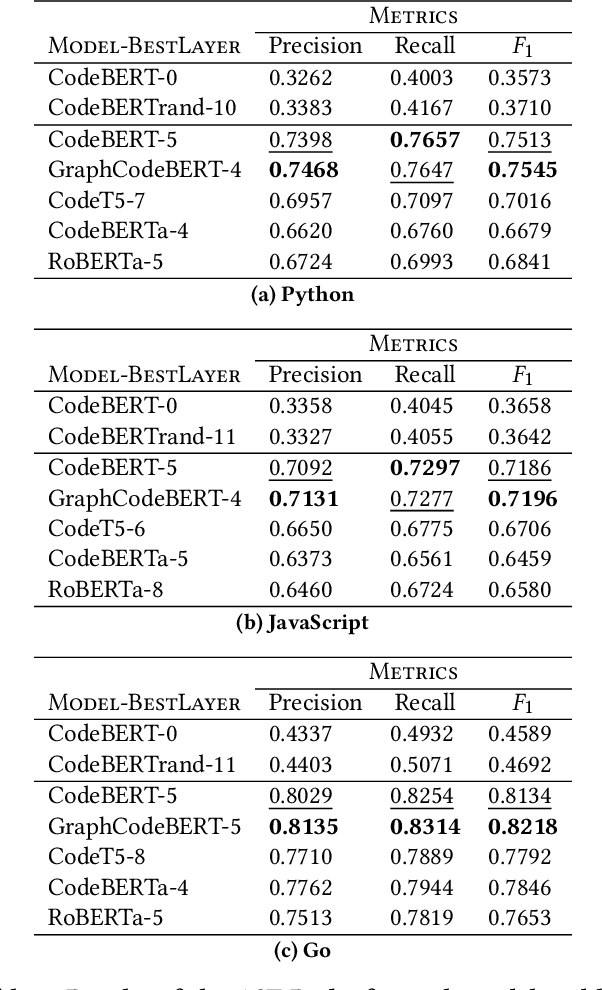
The objective of pre-trained language models is to learn contextual representations of textual data. Pre-trained language models have become mainstream in natural language processing and code modeling. Using probes, a technique to study the linguistic properties of hidden vector spaces, previous works have shown that these pre-trained language models encode simple linguistic properties in their hidden representations. However, none of the previous work assessed whether these models encode the whole grammatical structure of a programming language. In this paper, we prove the existence of a \textit{syntactic subspace}, lying in the hidden representations of pre-trained language models, which contain the syntactic information of the programming language. We show that this subspace can be extracted from the models' representations and define a novel probing method, the AST-Probe, that enables recovering the whole abstract syntax tree (AST) of an input code snippet. In our experimentations, we show that this syntactic subspace exists in five state-of-the-art pre-trained language models. In addition, we highlight that the middle layers of the models are the ones that encode most of the AST information. Finally, we estimate the optimal size of this syntactic subspace and show that its dimension is substantially lower than those of the models' representation spaces. This suggests that pre-trained language models use a small part of their representation spaces to encode syntactic information of the programming languages.