 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangepoint Analysis of Topic Proportions in Temporal Text Data
Paper and Code
Nov 29, 2021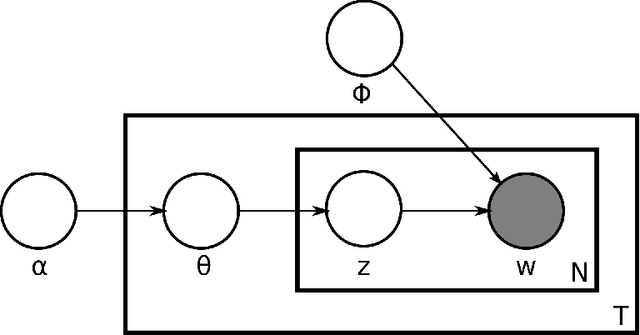
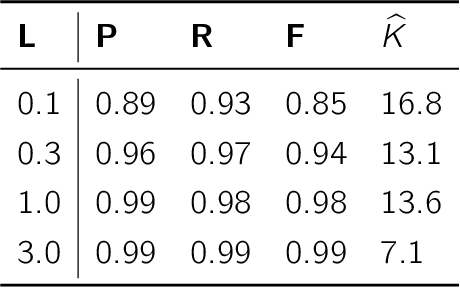
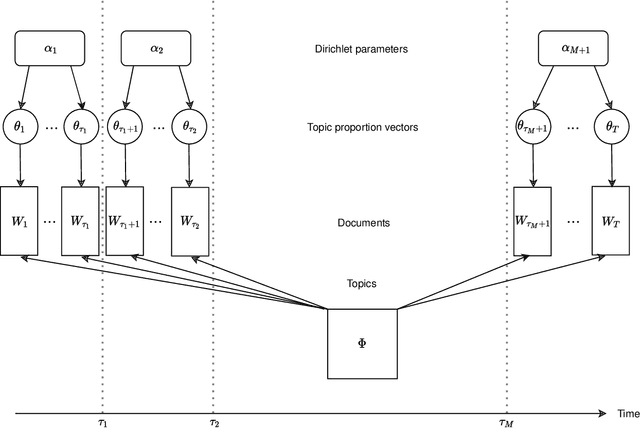
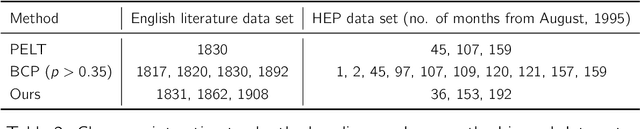
Changepoint analysis deals with unsupervised detection and/or estimation of time-points in time-series data, when the distribution generating the data changes. In this article, we consider \emph{offline} changepoint detection in the context of large scale textual data. We build a specialised temporal topic model with provisions for changepoints in the distribution of topic proportions. As full likelihood based inference in this model is computationally intractable, we develop a computationally tractable approximate inference procedure. More specifically, we use sample splitting to estimate topic polytopes first and then apply a likelihood ratio statistic together with a modified version of the wild binary segmentation algorithm of Fryzlewicz et al. (2014). Our methodology facilitates automated detection of structural changes in large corpora without the need of manual processing by domain experts. As changepoints under our model correspond to changes in topic structure, the estimated changepoints are often highly interpretable as marking the surge or decline in popularity of a fashionable topic. We apply our procedure on two large datasets: (i) a corpus of English literature from the period 1800-1922 (Underwoodet al., 2015); (ii) abstracts from the High Energy Physics arXiv repository (Clementet al., 2019). We obtain some historically well-known changepoints and discover some new ones.