 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Consensus to Disagreement: Multi-Teacher Distillation for Semi-Supervised Relation Extraction
Paper and Code
Dec 02, 2021


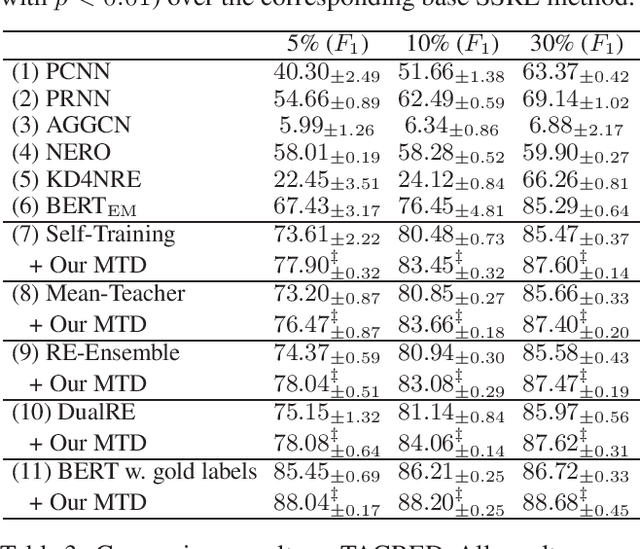
Lack of labeled data is a main obstacle in relation extraction. Semi-supervised relation extraction (SSRE) has been proven to be a promising way for this problem through annotating unlabeled samples as additional training data. Almost all prior researches along this line adopt multiple models to make the annotations more reliable by taking the intersection set of predicted results from these models. However, the difference set, which contains rich information about unlabeled data, has been long neglected by prior studies. In this paper, we propose to learn not only from the consensus but also the disagreement among different models in SSRE. To this end, we develop a simple and general multi-teacher distillation (MTD) framework, which can be easily integrated into any existing SSRE methods. Specifically, we first let the teachers correspond to the multiple models and select the samples in the intersection set of the last iteration in SSRE methods to augment labeled data as usual. We then transfer the class distributions for samples in the difference set as soft labels to guide the student. We finally perform prediction using the trained student model. Experimental results on two public datasets demonstrate that our framework significantly promotes the performance of the base SSRE methods with pretty low computational cost.