 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors
May 29, 2026LLM agents are evolving from conversational chatbots to operational tools in real-world workspaces. In local agentic harnesses, an LLM can read and write files, call tools, and reuse workspace state across sessions. While such capabilities enhance utility, they also expose a new attack surface for attackers. Attackers can embed a prompt injection within a file or tool output. Agents may read this hidden instruction, store it, and execute it later. In this multi-step trojan attack paradigm, no individual step appears malicious on its own, but these steps can collectively turn untrusted text into persistent control content. However, existing defenses often inspect each step in isolation. As a result, they can block a clear harmful action, but fail to detect the earlier write operation that plants the backdoor. To reveal this threat, we introduce ClawTrojan, a benchmark designed to identify multi-step trojan attacks in local agentic harnesses. In an OpenClaw-style simulated workspace with GPT-5.4, ClawTrojan reaches a 95.5% attack success rate (ASR), while existing single-turn prompt-injection attacks produce near-zero ASR on the same model. To address this threat, we propose DASGuard, which scans control-like text in sensitive local files, traces its origin, and removes control content that does not originate from a trusted source. Our results show that DASGuard achieves strong dynamic defense by combining runtime attack blocking with sanitized commits to the workspace.
SAM: State-Adaptive Memory for Long-Horizon Reasoning Agent
May 23, 2026Long-horizon agentic reasoning requires large language models to act over long interaction histories containing thoughts, tool calls, observations, and partial conclusions. The challenge is not merely that these histories grow long, but that information needed for the current decision may be scattered across distant steps and only become relevant later. Existing approaches address this difficulty by truncating the interaction history, compressing it into shorter surrogates, or retrieving selected parts of it for reuse, but they do not explicitly model how access to past interaction should adapt to the agent's evolving state. We instead cast long-horizon reasoning as a problem of state-adaptive memory. To this end, we propose State-Adaptive Memory~(SAM), a standalone framework that consolidates ongoing interaction into compact memory cues while preserving raw trajectory pages for intent-driven recall. These cues are not treated as replacements for history; rather, they serve as lightweight handles that allow the agent to reconstruct temporally distant information according to its current needs, without retraining the underlying backbone. We further optimize the memory module through expert-guided supervision and reinforcement learning, aligning it with trajectory-level utility. Across BrowseComp, BrowseComp-ZH, WideSearch, and HLE, SAM consistently outperforms strong baselines over diverse agent backbones. Our results suggest that explicit memory modeling provides a simple and effective foundation for long-horizon agentic reasoning.
MemSifter: Offloading LLM Memory Retrieval via Outcome-Driven Proxy Reasoning
Mar 03, 2026As Large Language Models (LLMs) are increasingly used for long-duration tasks, maintaining effective long-term memory has become a critical challenge. Current methods often face a trade-off between cost and accuracy. Simple storage methods often fail to retrieve relevant information, while complex indexing methods (such as memory graphs) require heavy computation and can cause information loss. Furthermore, relying on the working LLM to process all memories is computationally expensive and slow. To address these limitations, we propose MemSifter, a novel framework that offloads the memory retrieval process to a small-scale proxy model. Instead of increasing the burden on the primary working LLM, MemSifter uses a smaller model to reason about the task before retrieving the necessary information. This approach requires no heavy computation during the indexing phase and adds minimal overhead during inference. To optimize the proxy model, we introduce a memory-specific Reinforcement Learning (RL) training paradigm. We design a task-outcome-oriented reward based on the working LLM's actual performance in completing the task. The reward measures the actual contribution of retrieved memories by mutiple interactions with the working LLM, and discriminates retrieved rankings by stepped decreasing contributions. Additionally, we employ training techniques such as Curriculum Learning and Model Merging to improve performance. We evaluated MemSifter on eight LLM memory benchmarks, including Deep Research tasks. The results demonstrate that our method meets or exceeds the performance of existing state-of-the-art approaches in both retrieval accuracy and final task completion. MemSifter offers an efficient and scalable solution for long-term LLM memory. We have open-sourced the model weights, code, and training data to support further research.
Memory Matters More: Event-Centric Memory as a Logic Map for Agent Searching and Reasoning
Jan 08, 2026Large language models (LLMs) are increasingly deployed as intelligent agents that reason, plan, and interact with their environments. To effectively scale to long-horizon scenarios, a key capability for such agents is a memory mechanism that can retain, organize, and retrieve past experiences to support downstream decision-making. However, most existing approaches organize and store memories in a flat manner and rely on simple similarity-based retrieval techniques. Even when structured memory is introduced, existing methods often struggle to explicitly capture the logical relationships among experiences or memory units. Moreover, memory access is largely detached from the constructed structure and still depends on shallow semantic retrieval, preventing agents from reasoning logically over long-horizon dependencies. In this work, we propose CompassMem, an event-centric memory framework inspired by Event Segmentation Theory. CompassMem organizes memory as an Event Graph by incrementally segmenting experiences into events and linking them through explicit logical relations. This graph serves as a logic map, enabling agents to perform structured and goal-directed navigation over memory beyond superficial retrieval, progressively gathering valuable memories to support long-horizon reasoning. Experiments on LoCoMo and NarrativeQA demonstrate that CompassMem consistently improves both retrieval and reasoning performance across multiple backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
HierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches
Aug 11, 2025Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing deep search works are generally limited to a single knowledge source, either local or the Web. However, enterprises often require private deep search systems that can leverage search tools over both local and the Web corpus. Simply training an agent equipped with multiple search tools using flat reinforcement learning (RL) is a straightforward idea, but it has problems such as low training data efficiency and poor mastery of complex tools. To address the above issue, we propose a hierarchical agentic deep search framework, HierSearch, trained with hierarchical RL. At the low level, a local deep search agent and a Web deep search agent are trained to retrieve evidence from their corresponding domains. At the high level, a planner agent coordinates low-level agents and provides the final answer. Moreover, to prevent direct answer copying and error propagation, we design a knowledge refiner that filters out hallucinations and irrelevant evidence returned by low-level agents. Experiments show that HierSearch achieves better performance compared to flat RL, and outperforms various deep search and multi-source retrieval-augmented generation baselines in six benchmarks across general, finance, and medical domains.
OmniEval: An Omnidirectional and Automatic RAG Evaluation Benchmark in Financial Domain
Dec 17, 2024As a typical and practical application of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) techniques have gained extensive attention, particularly in vertical domains where LLMs may lack domain-specific knowledge. In this paper, we introduce an omnidirectional and automatic RAG benchmark, OmniEval, in the financial domain. Our benchmark is characterized by its multi-dimensional evaluation framework, including (1) a matrix-based RAG scenario evaluation system that categorizes queries into five task classes and 16 financial topics, leading to a structured assessment of diverse query scenarios; (2) a multi-dimensional evaluation data generation approach, which combines GPT-4-based automatic generation and human annotation, achieving an 87.47\% acceptance ratio in human evaluations on generated instances; (3) a multi-stage evaluation system that evaluates both retrieval and generation performance, result in a comprehensive evaluation on the RAG pipeline; and (4) robust evaluation metrics derived from rule-based and LLM-based ones, enhancing the reliability of assessments through manual annotations and supervised fine-tuning of an LLM evaluator. Our experiments demonstrate the comprehensiveness of OmniEval, which includes extensive test datasets and highlights the performance variations of RAG systems across diverse topics and tasks, revealing significant opportunities for RAG models to improve their capabilities in vertical domains. We open source the code of our benchmark in \href{https://github.com/RUC-NLPIR/OmniEval}{https://github.com/RUC-NLPIR/OmniEval}.
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
Nov 05, 2024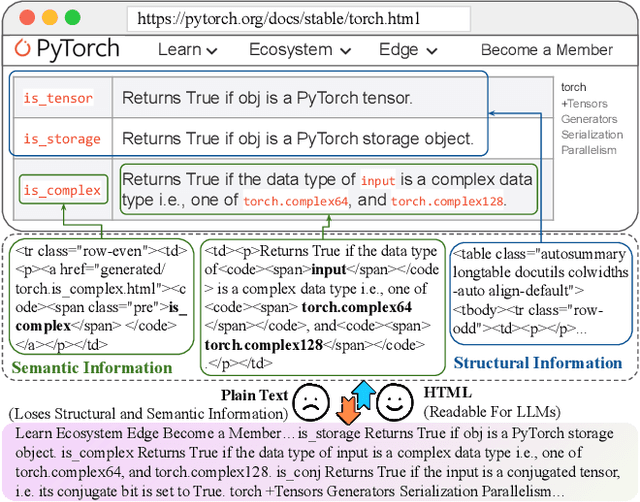
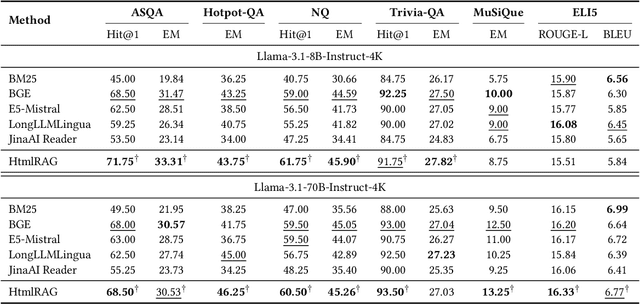
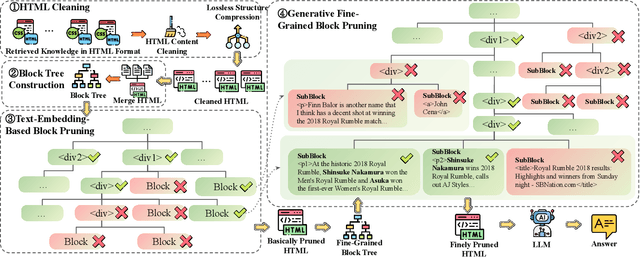
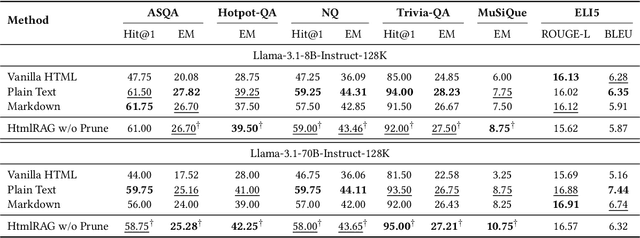
Retrieval-Augmented Generation (RAG) has been shown to improve knowledge capabilities and alleviate the hallucination problem of LLMs. The Web is a major source of external knowledge used in RAG systems, and many commercial systems such as ChatGPT and Perplexity have used Web search engines as their major retrieval systems. Typically, such RAG systems retrieve search results, download HTML sources of the results, and then extract plain texts from the HTML sources. Plain text documents or chunks are fed into the LLMs to augment the generation. However, much of the structural and semantic information inherent in HTML, such as headings and table structures, is lost during this plain-text-based RAG process. To alleviate this problem, we propose HtmlRAG, which uses HTML instead of plain text as the format of retrieved knowledge in RAG. We believe HTML is better than plain text in modeling knowledge in external documents, and most LLMs possess robust capacities to understand HTML. However, utilizing HTML presents new challenges. HTML contains additional content such as tags, JavaScript, and CSS specifications, which bring extra input tokens and noise to the RAG system. To address this issue, we propose HTML cleaning, compression, and pruning strategies, to shorten the HTML while minimizing the loss of information. Specifically, we design a two-step block-tree-based pruning method that prunes useless HTML blocks and keeps only the relevant part of the HTML. Experiments on six QA datasets confirm the superiority of using HTML in RAG systems.
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Feb 22, 2024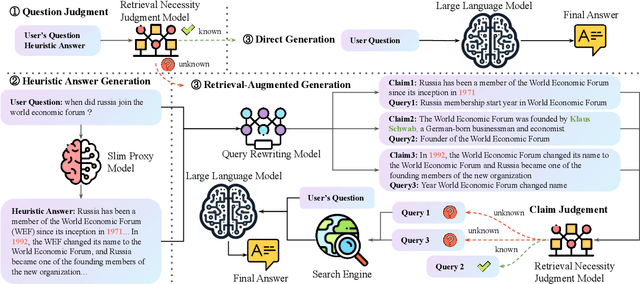
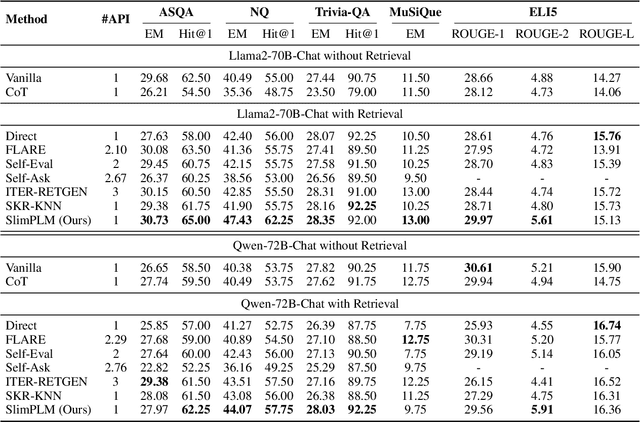
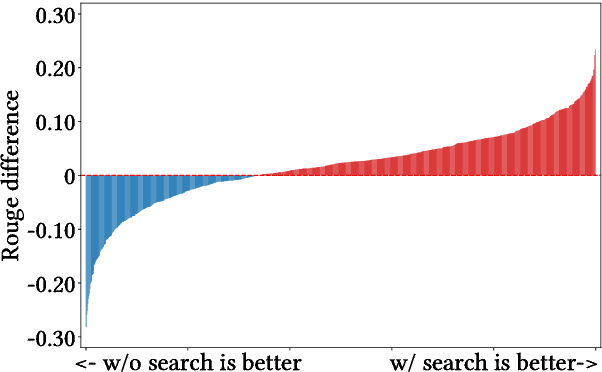
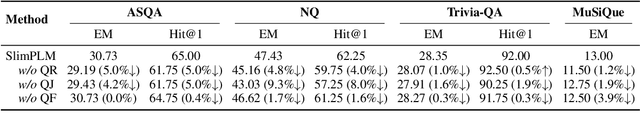
The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.
Optimizing Factual Accuracy in Text Generation through Dynamic Knowledge Selection
Aug 30, 2023
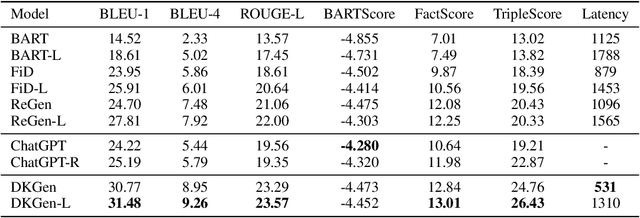
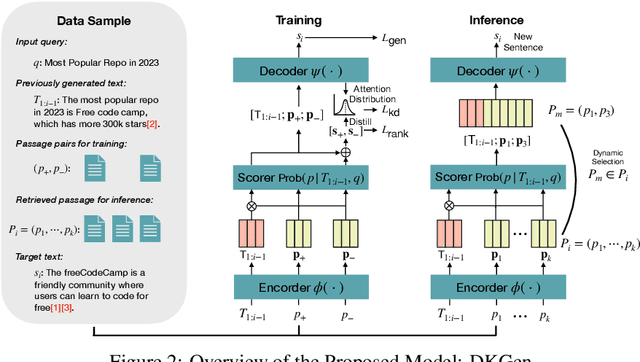
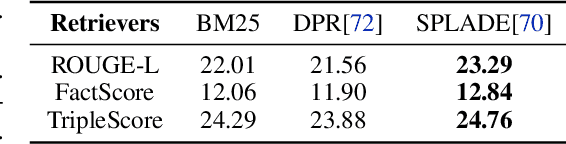
Language models (LMs) have revolutionized the way we interact with information, but they often generate nonfactual text, raising concerns about their reliability. Previous methods use external knowledge as references for text generation to enhance factuality but often struggle with the knowledge mix-up(e.g., entity mismatch) of irrelevant references. Besides,as the length of the output text grows, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text. In this paper, we present DKGen, which divide the text generation process into an iterative process. In each iteration, DKGen takes the input query, the previously generated text and a subset of the reference passages as input to generate short text. During the process, the subset is dynamically selected from the full passage set based on their relevance to the previously generated text and the query, largely eliminating the irrelevant references from input. To further enhance DKGen's ability to correctly use these external knowledge, DKGen distills the relevance order of reference passages to the cross-attention distribution of decoder. We train and evaluate DKGen on a large-scale benchmark dataset. Experiment results show that DKGen outperforms all baseline models.