 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Factual Accuracy in Text Generation through Dynamic Knowledge Selection
Paper and Code

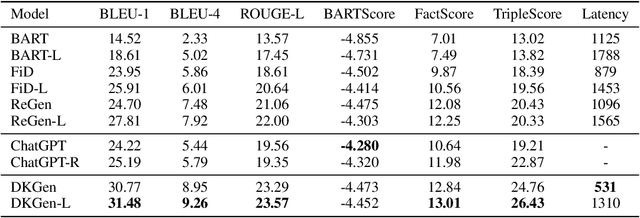
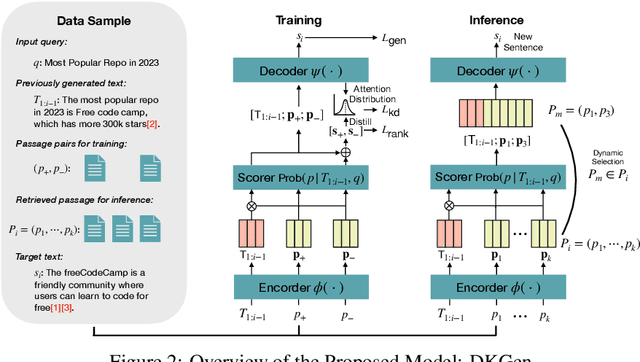
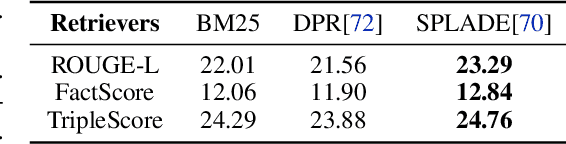
Language models (LMs) have revolutionized the way we interact with information, but they often generate nonfactual text, raising concerns about their reliability. Previous methods use external knowledge as references for text generation to enhance factuality but often struggle with the knowledge mix-up(e.g., entity mismatch) of irrelevant references. Besides,as the length of the output text grows, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text. In this paper, we present DKGen, which divide the text generation process into an iterative process. In each iteration, DKGen takes the input query, the previously generated text and a subset of the reference passages as input to generate short text. During the process, the subset is dynamically selected from the full passage set based on their relevance to the previously generated text and the query, largely eliminating the irrelevant references from input. To further enhance DKGen's ability to correctly use these external knowledge, DKGen distills the relevance order of reference passages to the cross-attention distribution of decoder. We train and evaluate DKGen on a large-scale benchmark dataset. Experiment results show that DKGen outperforms all baseline models.