 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Paper and Code
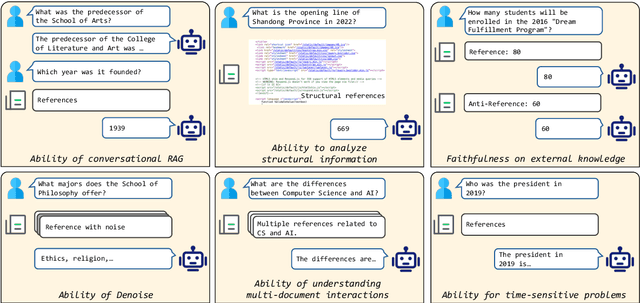
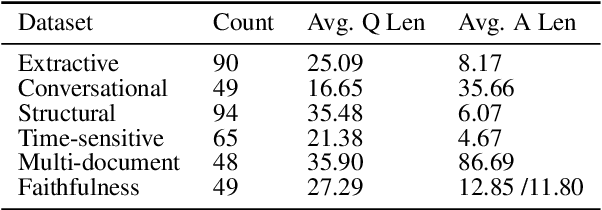
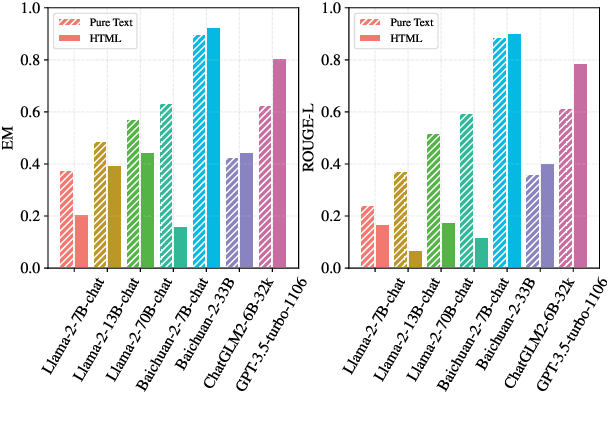
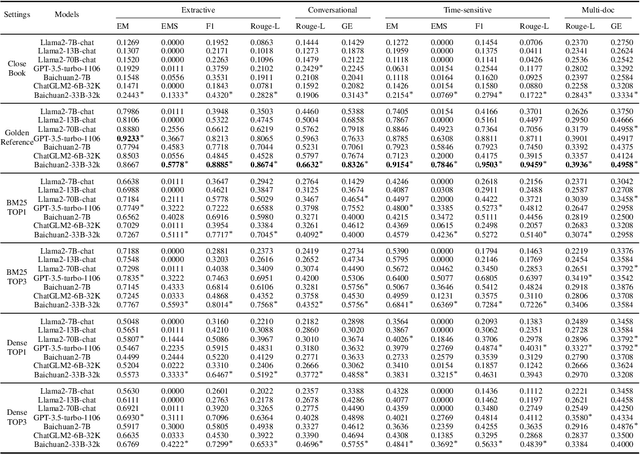
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.