 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Component Analysis: A Principled Approach for Concept Extraction in LLMs
Jan 29, 2026Developing human understandable interpretation of large language models (LLMs) becomes increasingly critical for their deployment in essential domains. Mechanistic interpretability seeks to mitigate the issues through extracts human-interpretable process and concepts from LLMs' activations. Sparse autoencoders (SAEs) have emerged as a popular approach for extracting interpretable and monosemantic concepts by decomposing the LLM internal representations into a dictionary. Despite their empirical progress, SAEs suffer from a fundamental theoretical ambiguity: the well-defined correspondence between LLM representations and human-interpretable concepts remains unclear. This lack of theoretical grounding gives rise to several methodological challenges, including difficulties in principled method design and evaluation criteria. In this work, we show that, under mild assumptions, LLM representations can be approximated as a {linear mixture} of the log-posteriors over concepts given the input context, through the lens of a latent variable model where concepts are treated as latent variables. This motivates a principled framework for concept extraction, namely Concept Component Analysis (ConCA), which aims to recover the log-posterior of each concept from LLM representations through a {unsupervised} linear unmixing process. We explore a specific variant, termed sparse ConCA, which leverages a sparsity prior to address the inherent ill-posedness of the unmixing problem. We implement 12 sparse ConCA variants and demonstrate their ability to extract meaningful concepts across multiple LLMs, offering theory-backed advantages over SAEs.
Negate or Embrace: On How Misalignment Shapes Multimodal Representation Learning
Apr 16, 2025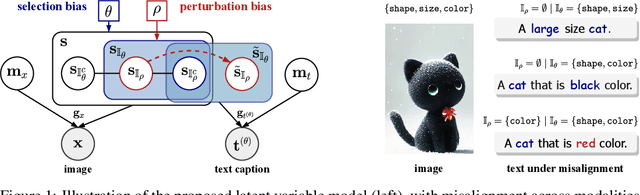

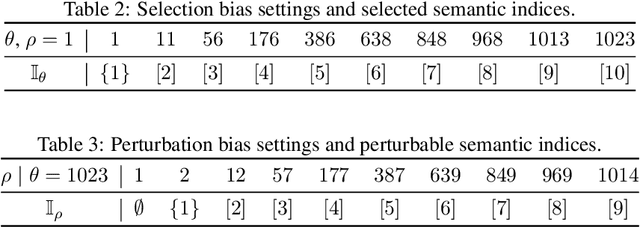

Multimodal representation learning, exemplified by multimodal contrastive learning (MMCL) using image-text pairs, aims to learn powerful representations by aligning cues across modalities. This approach relies on the core assumption that the exemplar image-text pairs constitute two representations of an identical concept. However, recent research has revealed that real-world datasets often exhibit misalignment. There are two distinct viewpoints on how to address this issue: one suggests mitigating the misalignment, and the other leveraging it. We seek here to reconcile these seemingly opposing perspectives, and to provide a practical guide for practitioners. Using latent variable models we thus formalize misalignment by introducing two specific mechanisms: selection bias, where some semantic variables are missing, and perturbation bias, where semantic variables are distorted -- both affecting latent variables shared across modalities. Our theoretical analysis demonstrates that, under mild assumptions, the representations learned by MMCL capture exactly the information related to the subset of the semantic variables invariant to selection and perturbation biases. This provides a unified perspective for understanding misalignment. Based on this, we further offer actionable insights into how misalignment should inform the design of real-world ML systems. We validate our theoretical findings through extensive empirical studies on both synthetic data and real image-text datasets, shedding light on the nuanced impact of misalignment on multimodal representation learning.
I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data?
Mar 12, 2025The remarkable achievements of large language models (LLMs) have led many to conclude that they exhibit a form of intelligence. This is as opposed to explanations of their capabilities based on their ability to perform relatively simple manipulations of vast volumes of data. To illuminate the distinction between these explanations, we introduce a novel generative model that generates tokens on the basis of human interpretable concepts represented as latent discrete variables. Under mild conditions, even when the mapping from the latent space to the observed space is non-invertible, we establish an identifiability result: the representations learned by LLMs through next-token prediction can be approximately modeled as the logarithm of the posterior probabilities of these latent discrete concepts, up to an invertible linear transformation. This theoretical finding not only provides evidence that LLMs capture underlying generative factors, but also strongly reinforces the linear representation hypothesis, which posits that LLMs learn linear representations of human-interpretable concepts. Empirically, we validate our theoretical results through evaluations on both simulation data and the Pythia, Llama, and DeepSeek model families.
Eliminating Prior Bias for Semantic Image Editing via Dual-Cycle Diffusion
Feb 07, 2023The recent success of text-to-image generation diffusion models has also revolutionized semantic image editing, enabling the manipulation of images based on query/target texts. Despite these advancements, a significant challenge lies in the potential introduction of prior bias in pre-trained models during image editing, e.g., making unexpected modifications to inappropriate regions. To this point, we present a novel Dual-Cycle Diffusion model that addresses the issue of prior bias by generating an unbiased mask as the guidance of image editing. The proposed model incorporates a Bias Elimination Cycle that consists of both a forward path and an inverted path, each featuring a Structural Consistency Cycle to ensure the preservation of image content during the editing process. The forward path utilizes the pre-trained model to produce the edited image, while the inverted path converts the result back to the source image. The unbiased mask is generated by comparing differences between the processed source image and the edited image to ensure that both conform to the same distribution. Our experiments demonstrate the effectiveness of the proposed method, as it significantly improves the D-CLIP score from 0.272 to 0.283. The code will be available at https://github.com/JohnDreamer/DualCycleDiffsion.
On the Sparse DAG Structure Learning Based on Adaptive Lasso
Sep 07, 2022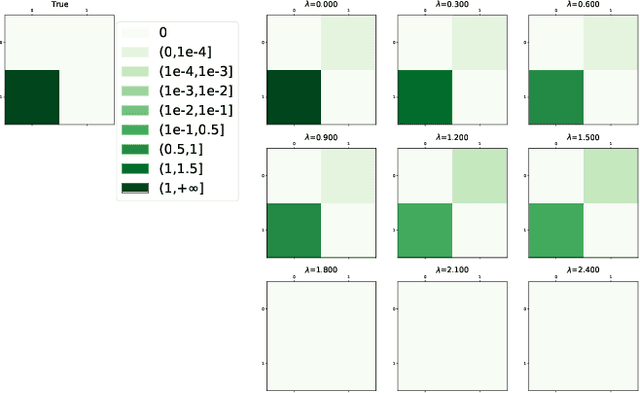
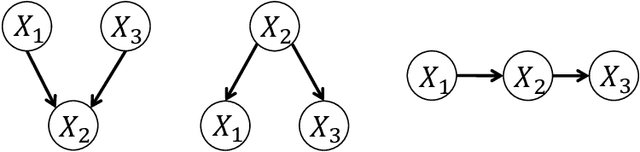
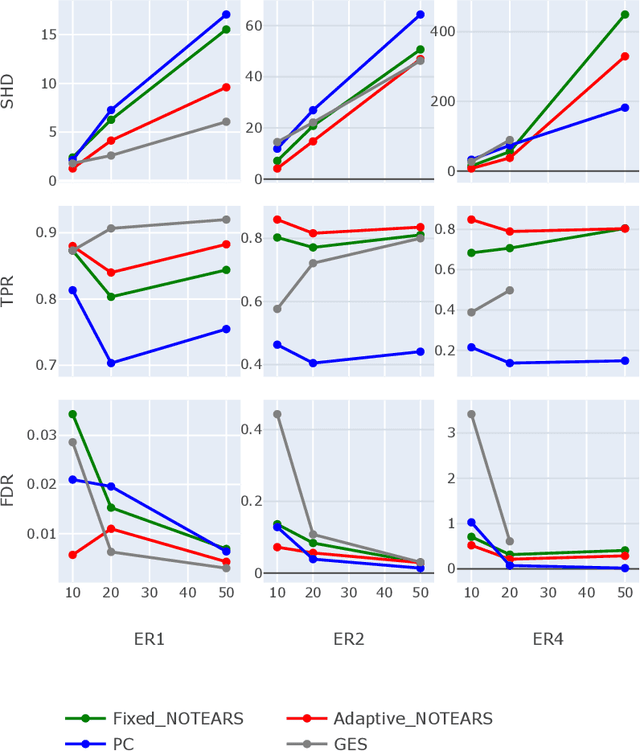
Learning the underlying casual structure, represented by Directed Acyclic Graphs (DAGs), of concerned events from fully-observational data is a crucial part of causal reasoning, but it is challenging due to the combinatorial and large search space. A recent flurry of developments recast this combinatorial problem into a continuous optimization problem by leveraging an algebraic equality characterization of acyclicity. However, these methods suffer from the fixed-threshold step after optimization, which is not a flexible and systematic way to rule out the cycle-inducing edges or false discoveries edges with small values caused by numerical precision. In this paper, we develop a data-driven DAG structure learning method without the predefined threshold, called adaptive NOTEARS [30], achieved by applying adaptive penalty levels to each parameters in the regularization term. We show that adaptive NOTEARS enjoys the oracle properties under some specific conditions. Furthermore, simulation experimental results validate the effectiveness of our method, without setting any gap of edges weights around zero.
MissDAG: Causal Discovery in the Presence of Missing Data with Continuous Additive Noise Models
May 27, 2022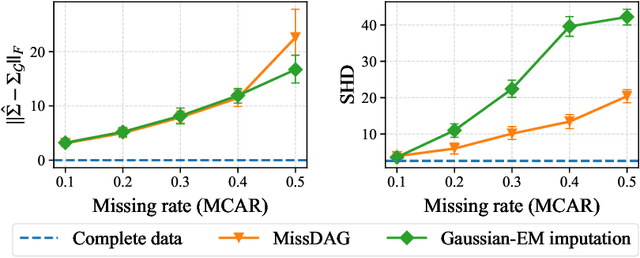
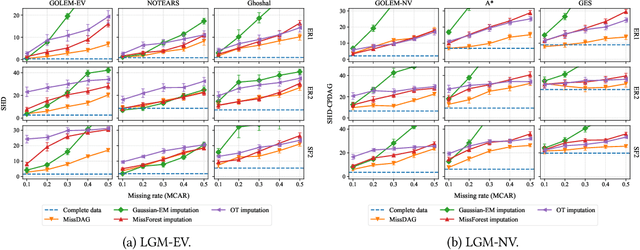
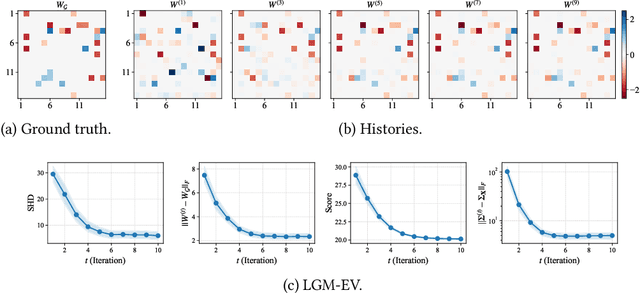
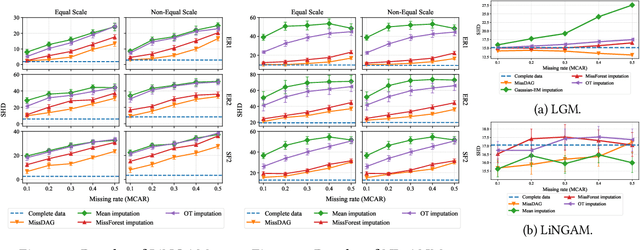
State-of-the-art causal discovery methods usually assume that the observational data is complete. However, the missing data problem is pervasive in many practical scenarios such as clinical trials, economics, and biology. One straightforward way to address the missing data problem is first to impute the data using off-the-shelf imputation methods and then apply existing causal discovery methods. However, such a two-step method may suffer from suboptimality, as the imputation algorithm is unaware of the causal discovery step. In this paper, we develop a general method, which we call MissDAG, to perform causal discovery from data with incomplete observations. Focusing mainly on the assumptions of ignorable missingness and the identifiable additive noise models (ANMs), MissDAG maximizes the expected likelihood of the visible part of observations under the expectation-maximization (EM) framework. In the E-step, in cases where computing the posterior distributions of parameters in closed-form is not feasible, Monte Carlo EM is leveraged to approximate the likelihood. In the M-step, MissDAG leverages the density transformation to model the noise distributions with simpler and specific formulations by virtue of the ANMs and uses a likelihood-based causal discovery algorithm with directed acyclic graph prior as an inductive bias. We demonstrate the flexibility of MissDAG for incorporating various causal discovery algorithms and its efficacy through extensive simulations and real data experiments.
Federated Causal Discovery
Dec 07, 2021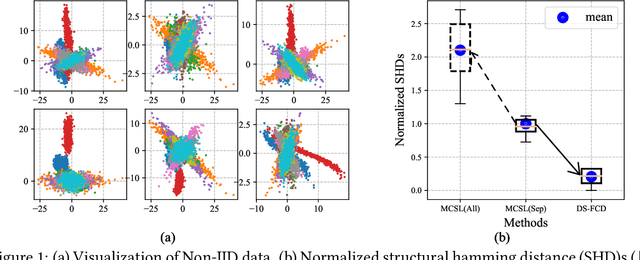
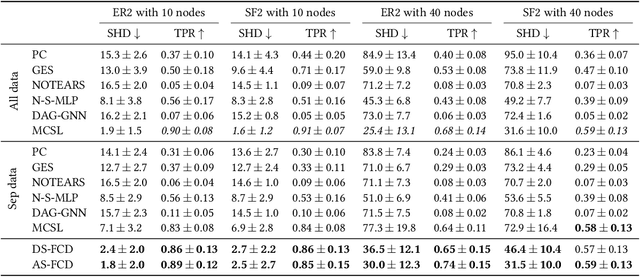
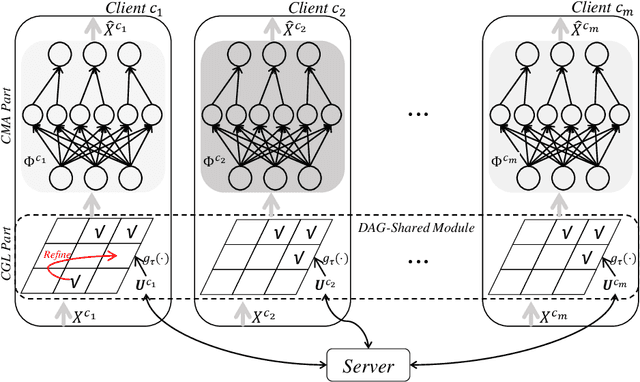
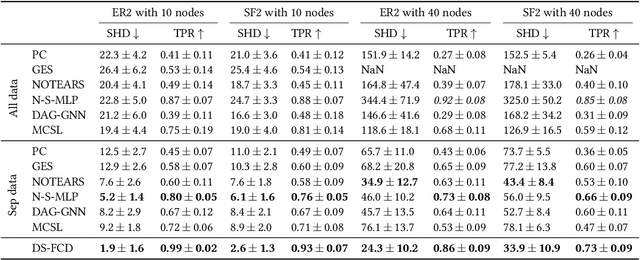
Causal discovery aims to learn a causal graph from observational data. To date, most causal discovery methods require data to be stored in a central server. However, data owners gradually refuse to share their personalized data to avoid privacy leakage, making this task more troublesome by cutting off the first step. A puzzle arises: $\textit{how do we infer causal relations from decentralized data?}$ In this paper, with the additive noise model assumption of data, we take the first step in developing a gradient-based learning framework named DAG-Shared Federated Causal Discovery (DS-FCD), which can learn the causal graph without directly touching local data and naturally handle the data heterogeneity. DS-FCD benefits from a two-level structure of each local model. The first level learns the causal graph and communicates with the server to get model information from other clients, while the second level approximates causal mechanisms and personally updates from its own data to accommodate the data heterogeneity. Moreover, DS-FCD formulates the overall learning task as a continuous optimization problem by taking advantage of an equality acyclicity constraint, which can be naturally solved by gradient descent methods. Extensive experiments on both synthetic and real-world datasets verify the efficacy of the proposed method.