 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetition-based Adaptive ReLU for Deep Neural Networks
Jul 28, 2024



Activation functions introduce nonlinearity into deep neural networks. Most popular activation functions allow positive values to pass through while blocking or suppressing negative values. From the idea that positive values and negative values are equally important, and they must compete for activation, we proposed a new Competition-based Adaptive ReLU (CAReLU). CAReLU scales the input values based on the competition results between positive values and negative values. It defines two parameters to adjust the scaling strategy and can be trained uniformly with other network parameters. We verify the effectiveness of CAReLU on image classification, super-resolution, and natural language processing tasks. In the experiment, our method performs better than other widely used activation functions. In the case of replacing ReLU in ResNet-18 with our proposed activation function, it improves the classification accuracy on the CIFAR-100 dataset. The effectiveness and the new perspective on the utilization of competition results between positive values and negative values make CAReLU a promising activation function.
Saturated Non-Monotonic Activation Functions
May 25, 2023Activation functions are essential to deep learning networks. Popular and versatile activation functions are mostly monotonic functions, some non-monotonic activation functions are being explored and show promising performance. But by introducing non-monotonicity, they also alter the positive input, which is proved to be unnecessary by the success of ReLU and its variants. In this paper, we double down on the non-monotonic activation functions' development and propose the Saturated Gaussian Error Linear Units by combining the characteristics of ReLU and non-monotonic activation functions. We present three new activation functions built with our proposed method: SGELU, SSiLU, and SMish, which are composed of the negative portion of GELU, SiLU, and Mish, respectively, and ReLU's positive portion. The results of image classification experiments on CIFAR-100 indicate that our proposed activation functions are highly effective and outperform state-of-the-art baselines across multiple deep learning architectures.
Federated Causal Discovery
Dec 07, 2021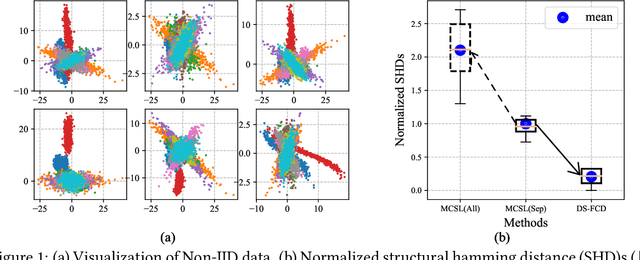
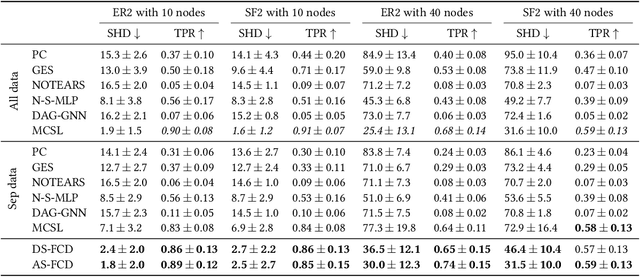
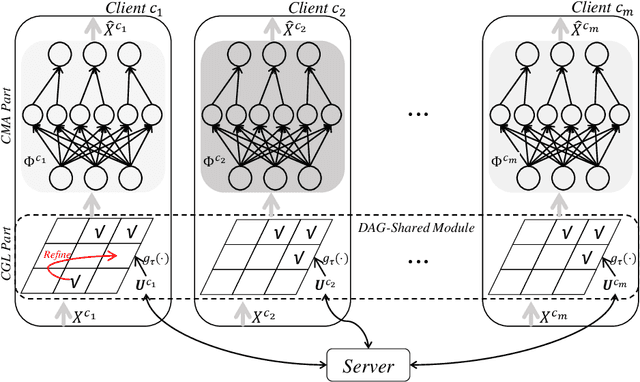
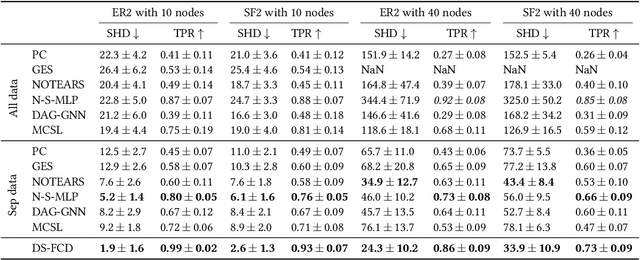
Causal discovery aims to learn a causal graph from observational data. To date, most causal discovery methods require data to be stored in a central server. However, data owners gradually refuse to share their personalized data to avoid privacy leakage, making this task more troublesome by cutting off the first step. A puzzle arises: $\textit{how do we infer causal relations from decentralized data?}$ In this paper, with the additive noise model assumption of data, we take the first step in developing a gradient-based learning framework named DAG-Shared Federated Causal Discovery (DS-FCD), which can learn the causal graph without directly touching local data and naturally handle the data heterogeneity. DS-FCD benefits from a two-level structure of each local model. The first level learns the causal graph and communicates with the server to get model information from other clients, while the second level approximates causal mechanisms and personally updates from its own data to accommodate the data heterogeneity. Moreover, DS-FCD formulates the overall learning task as a continuous optimization problem by taking advantage of an equality acyclicity constraint, which can be naturally solved by gradient descent methods. Extensive experiments on both synthetic and real-world datasets verify the efficacy of the proposed method.