 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetition-based Adaptive ReLU for Deep Neural Networks
Jul 28, 2024



Activation functions introduce nonlinearity into deep neural networks. Most popular activation functions allow positive values to pass through while blocking or suppressing negative values. From the idea that positive values and negative values are equally important, and they must compete for activation, we proposed a new Competition-based Adaptive ReLU (CAReLU). CAReLU scales the input values based on the competition results between positive values and negative values. It defines two parameters to adjust the scaling strategy and can be trained uniformly with other network parameters. We verify the effectiveness of CAReLU on image classification, super-resolution, and natural language processing tasks. In the experiment, our method performs better than other widely used activation functions. In the case of replacing ReLU in ResNet-18 with our proposed activation function, it improves the classification accuracy on the CIFAR-100 dataset. The effectiveness and the new perspective on the utilization of competition results between positive values and negative values make CAReLU a promising activation function.
Saturated Non-Monotonic Activation Functions
May 25, 2023Activation functions are essential to deep learning networks. Popular and versatile activation functions are mostly monotonic functions, some non-monotonic activation functions are being explored and show promising performance. But by introducing non-monotonicity, they also alter the positive input, which is proved to be unnecessary by the success of ReLU and its variants. In this paper, we double down on the non-monotonic activation functions' development and propose the Saturated Gaussian Error Linear Units by combining the characteristics of ReLU and non-monotonic activation functions. We present three new activation functions built with our proposed method: SGELU, SSiLU, and SMish, which are composed of the negative portion of GELU, SiLU, and Mish, respectively, and ReLU's positive portion. The results of image classification experiments on CIFAR-100 indicate that our proposed activation functions are highly effective and outperform state-of-the-art baselines across multiple deep learning architectures.
A Convolutional Neural Network with Mapping Layers for Hyperspectral Image Classification
Aug 26, 2019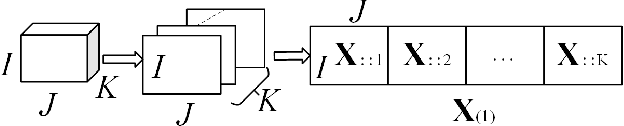

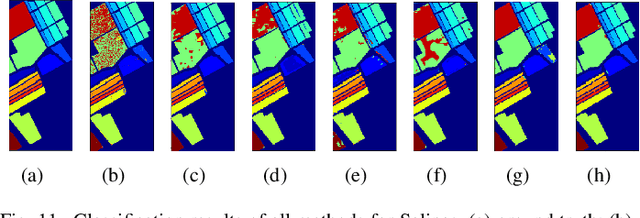
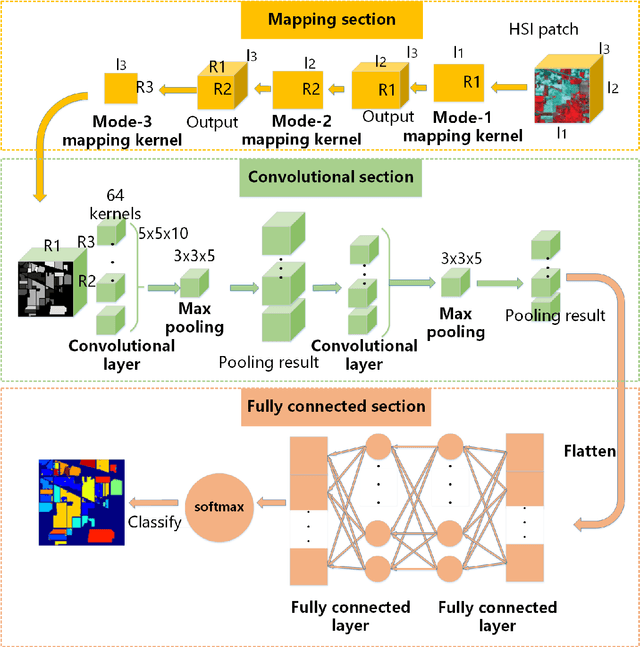
In this paper, we propose a convolutional neural network with mapping layers (MCNN) for hyperspectral image (HSI) classification. The proposed mapping layers map the input patch into a low dimensional subspace by multilinear algebra. We use our mapping layers to reduce the spectral and spatial redundancy and maintain most energy of the input. The feature extracted by our mapping layers can also reduce the number of following convolutional layers for feature extraction. Our MCNN architecture avoids the declining accuracy with increasing layers phenomenon of deep learning models for HSI classification and also saves the training time for its effective mapping layers. Furthermore, we impose the 3-D convolutional kernel on convolutional layer to extract the spectral-spatial features for HSI. We tested our MCNN on three datasets of Indian Pines, University of Pavia and Salinas, and we achieved the classification accuracy of 98.3%, 99.5% and 99.3%, respectively. Experimental results demonstrate that the proposed MCNN can significantly improve the classification accuracy and save much time consumption.