 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometric Mechanics of Contrastive Representation Learning: Alignment Potentials, Entropic Dispersion, and Cross-Modal Divergence
Jan 27, 2026While InfoNCE powers modern contrastive learning, its geometric mechanisms remain under-characterized beyond the canonical alignment--uniformity decomposition. We present a measure-theoretic framework that models learning as the evolution of representation measures on a fixed embedding manifold. By establishing value and gradient consistency in the large-batch limit, we bridge the stochastic objective to explicit deterministic energy landscapes, uncovering a fundamental geometric bifurcation between the unimodal and multimodal regimes. In the unimodal setting, the intrinsic landscape is strictly convex with a unique Gibbs equilibrium; here, entropy acts merely as a tie-breaker, clarifying "uniformity" as a constrained expansion within the alignment basin. In contrast, the symmetric multimodal objective contains a persistent negative symmetric divergence term that remains even after kernel sharpening. We show that this term induces barrier-driven co-adaptation, enforcing a population-level modality gap as a structural geometric necessity rather than an initialization artifact. Our results shift the analytical lens from pointwise discrimination to population geometry, offering a principled basis for diagnosing and controlling distributional misalignment.
Negate or Embrace: On How Misalignment Shapes Multimodal Representation Learning
Apr 16, 2025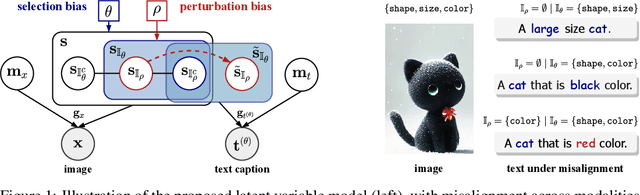

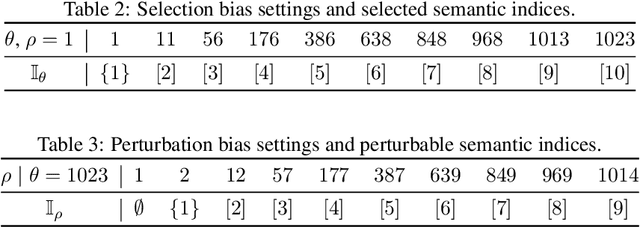

Multimodal representation learning, exemplified by multimodal contrastive learning (MMCL) using image-text pairs, aims to learn powerful representations by aligning cues across modalities. This approach relies on the core assumption that the exemplar image-text pairs constitute two representations of an identical concept. However, recent research has revealed that real-world datasets often exhibit misalignment. There are two distinct viewpoints on how to address this issue: one suggests mitigating the misalignment, and the other leveraging it. We seek here to reconcile these seemingly opposing perspectives, and to provide a practical guide for practitioners. Using latent variable models we thus formalize misalignment by introducing two specific mechanisms: selection bias, where some semantic variables are missing, and perturbation bias, where semantic variables are distorted -- both affecting latent variables shared across modalities. Our theoretical analysis demonstrates that, under mild assumptions, the representations learned by MMCL capture exactly the information related to the subset of the semantic variables invariant to selection and perturbation biases. This provides a unified perspective for understanding misalignment. Based on this, we further offer actionable insights into how misalignment should inform the design of real-world ML systems. We validate our theoretical findings through extensive empirical studies on both synthetic data and real image-text datasets, shedding light on the nuanced impact of misalignment on multimodal representation learning.
CLAP: Contrastive Learning with Augmented Prompts for Robustness on Pretrained Vision-Language Models
Nov 28, 2023Contrastive vision-language models, e.g., CLIP, have garnered substantial attention for their exceptional generalization capabilities. However, their robustness to perturbations has ignited concerns. Existing strategies typically reinforce their resilience against adversarial examples by enabling the image encoder to "see" these perturbed examples, often necessitating a complete retraining of the image encoder on both natural and adversarial samples. In this study, we propose a new method to enhance robustness solely through text augmentation, eliminating the need for retraining the image encoder on adversarial examples. Our motivation arises from the realization that text and image data inherently occupy a shared latent space, comprising latent content variables and style variables. This insight suggests the feasibility of learning to disentangle these latent content variables using text data exclusively. To accomplish this, we introduce an effective text augmentation method that focuses on modifying the style while preserving the content in the text data. By changing the style part of the text data, we empower the text encoder to emphasize latent content variables, ultimately enhancing the robustness of vision-language models. Our experiments across various datasets demonstrate substantial improvements in the robustness of the pre-trained CLIP model.