 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativity in the Age of AI: Rethinking the Role of Intentional Agency
Jan 22, 2026Many theorists of creativity maintain that intentional agency is a necessary condition of creativity. We argue that this requirement, which we call the Intentional Agency Condition (IAC), should be rejected as a general condition of creativity, while retaining its relevance in specific contexts. We show that recent advances in generative AI have rendered the IAC increasingly problematic, both descriptively and functionally. We offer two reasons for abandoning it at the general level. First, we present corpus evidence indicating that authors and journalists are increasingly comfortable ascribing creativity to generative AI, despite its lack of intentional agency. This development places pressure on the linguistic intuitions that have traditionally been taken to support the IAC. Second, drawing on the method of conceptual engineering, we argue that the IAC no longer fulfils its core social function. Rather than facilitating the identification and encouragement of reliable sources of novel and valuable products, it now feeds into biases that distort our assessments of AI-generated outputs. We therefore propose replacing the IAC with a consistency requirement, according to which creativity tracks the reliable generation of novel and valuable products. Nonetheless, we explain why the IAC should be retained in specific local domains.
Professional Presentation and Projected Power: A Case Study of Implicit Gender Information in English CVs
Nov 17, 2022



Gender discrimination in hiring is a pertinent and persistent bias in society, and a common motivating example for exploring bias in NLP. However, the manifestation of gendered language in application materials has received limited attention. This paper investigates the framing of skills and background in CVs of self-identified men and women. We introduce a data set of 1.8K authentic, English-language, CVs from the US, covering 16 occupations, allowing us to partially control for the confound occupation-specific gender base rates. We find that (1) women use more verbs evoking impressions of low power; and (2) classifiers capture gender signal even after data balancing and removal of pronouns and named entities, and this holds for both transformer-based and linear classifiers.
Automated clustering of COVID-19 anti-vaccine discourse on Twitter
Mar 03, 2022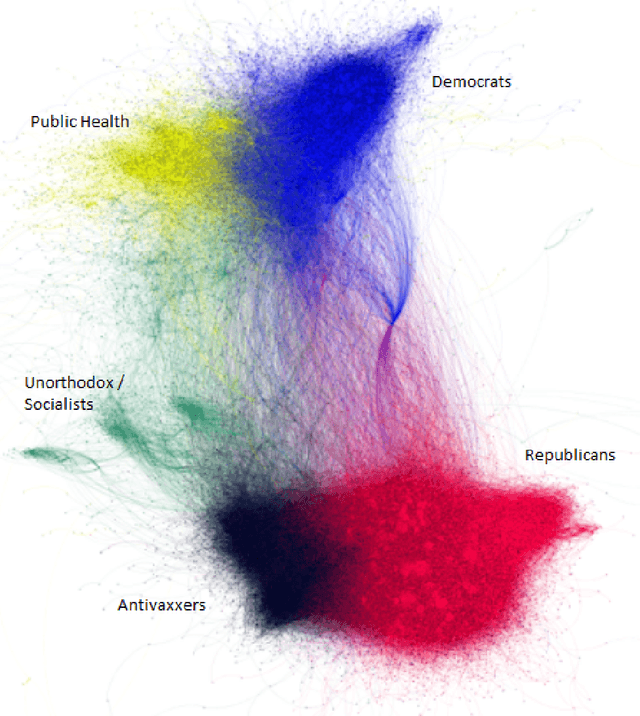
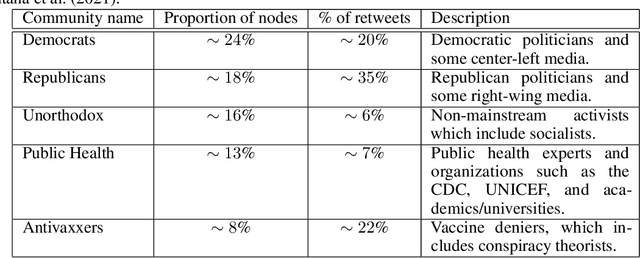
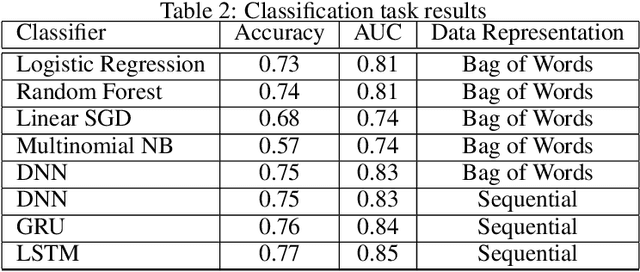
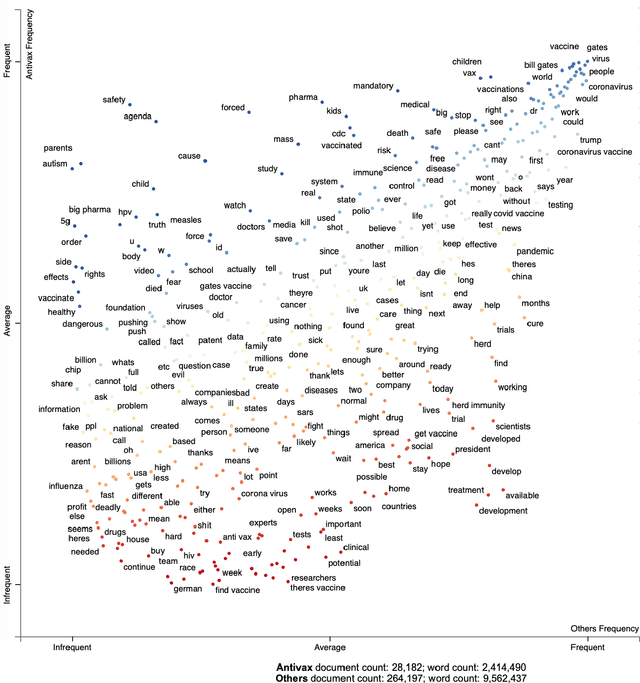
Attitudes about vaccination have become more polarized; it is common to see vaccine disinformation and fringe conspiracy theories online. An observational study of Twitter vaccine discourse is found in Ojea Quintana et al. (2021): the authors analyzed approximately six months' of Twitter discourse -- 1.3 million original tweets and 18 million retweets between December 2019 and June 2020, ranging from before to after the establishment of Covid-19 as a pandemic. This work expands upon Ojea Quintana et al. (2021) with two main contributions from data science. First, based on the authors' initial network clustering and qualitative analysis techniques, we are able to clearly demarcate and visualize the language patterns used in discourse by Antivaxxers (anti-vaccination campaigners and vaccine deniers) versus other clusters (collectively, Others). Second, using the characteristics of Antivaxxers' tweets, we develop text classifiers to determine the likelihood a given user is employing anti-vaccination language, ultimately contributing to an early-warning mechanism to improve the health of our epistemic environment and bolster (and not hinder) public health initiatives.
LEx: A Framework for Operationalising Layers of Machine Learning Explanations
Apr 15, 2021Several social factors impact how people respond to AI explanations used to justify AI decisions affecting them personally. In this position paper, we define a framework called the \textit{layers of explanation} (LEx), a lens through which we can assess the appropriateness of different types of explanations. The framework uses the notions of \textit{sensitivity} (emotional responsiveness) of features and the level of \textit{stakes} (decision's consequence) in a domain to determine whether different types of explanations are \textit{appropriate} in a given context. We demonstrate how to use the framework to assess the appropriateness of different types of explanations in different domains.
Observement as Universal Measurement
Dec 07, 2020


Measurement theory is the cornerstone of science, but no equivalent theory underpins the huge volumes of non-numerical data now being generated. In this study, we show that replacing numbers with alternative mathematical models, such as strings and graphs, generalises traditional measurement to provide rigorous, formal systems (`observement') for recording and interpreting non-numerical data. Moreover, we show that these representations are already widely used and identify general classes of interpretive methodologies implicit in representations based on character strings and graphs (networks). This implies that a generalised concept of measurement has the potential to reveal new insights as well as deep connections between different fields of research.