 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Confidence Bounds for Stochastic Partial Monitoring
Paper and Code
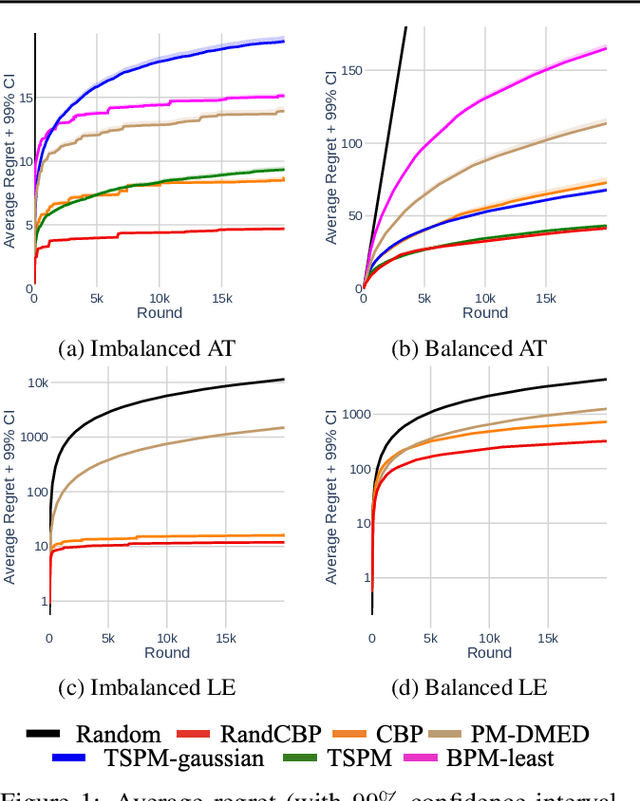
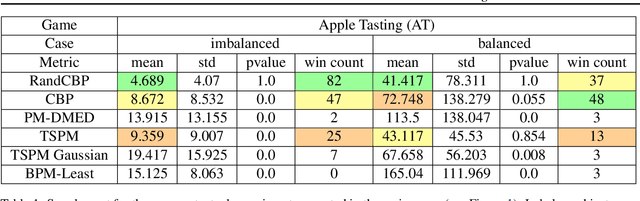
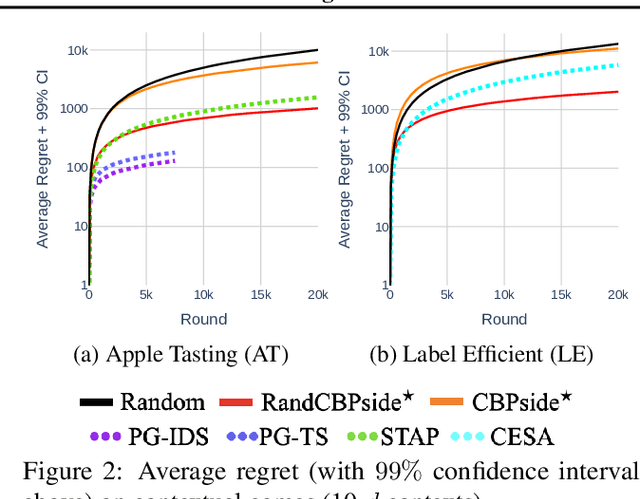

The partial monitoring (PM) framework provides a theoretical formulation of sequential learning problems with incomplete feedback. On each round, a learning agent plays an action while the environment simultaneously chooses an outcome. The agent then observes a feedback signal that is only partially informative about the (unobserved) outcome. The agent leverages the received feedback signals to select actions that minimize the (unobserved) cumulative loss. In contextual PM, the outcomes depend on some side information that is observable by the agent before selecting the action on each round. In this paper, we consider the contextual and non-contextual PM settings with stochastic outcomes. We introduce a new class of strategies based on the randomization of deterministic confidence bounds, that extend regret guarantees to settings where existing stochastic strategies are not applicable. Our experiments show that the proposed RandCBP and RandCBPside* strategies improve state-of-the-art baselines in PM games. To encourage the adoption of the PM framework, we design a use case on the real-world problem of monitoring the error rate of any deployed classification system.