 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Match Templates for Unseen Instance Detection
Nov 26, 2019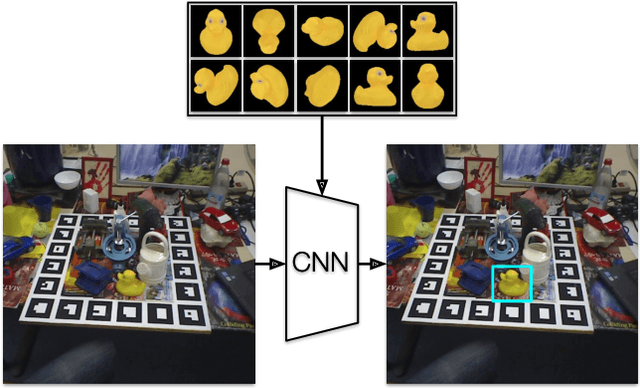
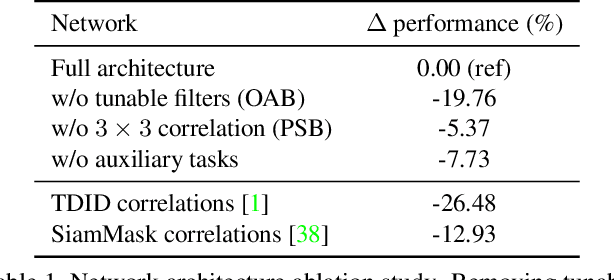


Detecting objects in images is a quintessential problem in computer vision. Much of the focus in the literature has been on the problem of identifying the bounding box of a particular type of objects in an image. Yet, in many contexts such as robotics and augmented reality, it is more important to find a specific object instance---a unique toy or a custom industrial part for example---rather than a generic object class. Here, applications can require a rapid shift from one object instance to another, thus requiring fast turnaround which affords little-to-no training time. In this context, we propose a method for detecting objects that are unknown at training time. Our approach frames the problem as one of learned template matching, where a network is trained to match the template of an object in an image. The template is obtained by rendering a textured 3D model of the object. At test time, we provide a novel 3D object, and the network is able to successfully detect it, even under significant occlusion. Our method offers an improvement of almost 30 mAP over the previous template matching methods on the challenging Occluded Linemod (overall mAP of 50.7). With no access to the objects at training time, our method still yields detection results that are on par with existing ones that are allowed to train on the objects. By reviving this research direction in the context of more powerful, deep feature extractors, our work sets the stage for more development in the area of unseen object instance detection.
Learning Object Localization and 6D Pose Estimation from Simulation and Weakly Labeled Real Images
Jun 18, 2018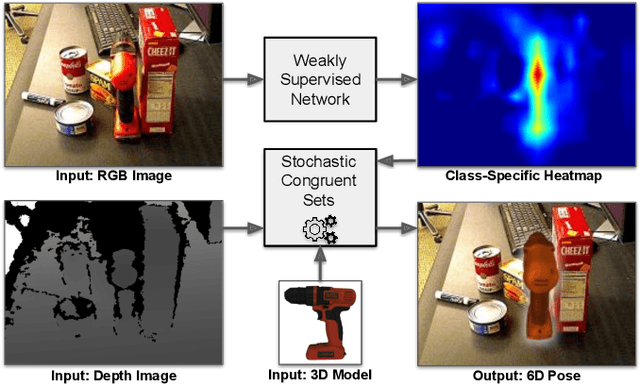



This work proposes a process for efficiently training a point-wise object detector that enables localizing objects and computing their 6D poses in cluttered and occluded scenes. Accurate pose estimation is typically a requirement for robust robotic grasping and manipulation of objects placed in cluttered, tight environments, such as a shelf with multiple objects. To minimize the human labor required for annotation, the proposed object detector is first trained in simulation by using automatically annotated synthetic images. We then show that the performance of the detector can be substantially improved by using a small set of weakly annotated real images, where a human provides only a list of objects present in each image without indicating the location of the objects. To close the gap between real and synthetic images, we adopt a domain adaptation approach through adversarial training. The detector resulting from this training process can be used to localize objects by using its per-object activation maps. In this work, we use the activation maps to guide the search of 6D poses of objects. Our proposed approach is evaluated on several publicly available datasets for pose estimation. We also evaluated our model on classification and localization in unsupervised and semi-supervised settings. The results clearly indicate that this approach could provide an efficient way toward fully automating the training process of computer vision models used in robotics.