 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach me how to Label: Labeling Functions from Natural Language with Text-to-text Transformers
Paper and Code
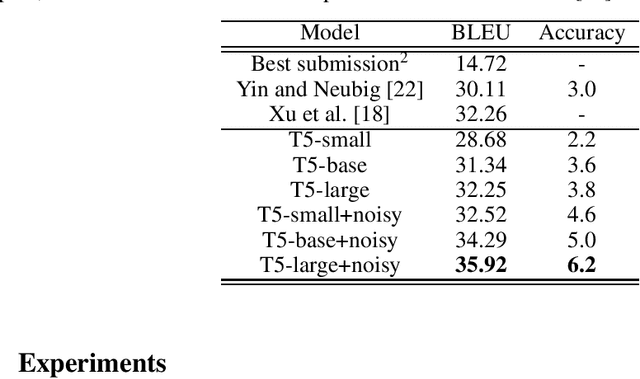
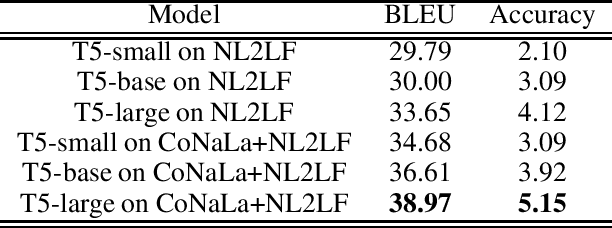
Annotated data has become the most important bottleneck in training accurate machine learning models, especially for areas that require domain expertise. A recent approach to deal with the above issue proposes using natural language explanations instead of labeling individual data points, thereby increasing human annotators' efficiency as well as decreasing costs substantially. This paper focuses on the task of turning these natural language descriptions into Python labeling functions by following a novel approach to semantic parsing with pre-trained text-to-text Transformers. In a series of experiments our approach achieves a new state of the art on the semantic parsing benchmark CoNaLa, surpassing the previous best approach by 3.7 BLEU points. Furthermore, on a manually constructed dataset of natural language descriptions-labeling functions pairs we achieve a BLEU of 0.39. Our approach can be regarded as a stepping stone towards models that are taught how to label in natural language, instead of being provided specific labeled samples. Our code, constructed dataset and models are available at https://github.com/ypapanik/t5-for-code-generation.