 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Embedding Allocation: Distributed Representations of Topic Models
Paper and Code

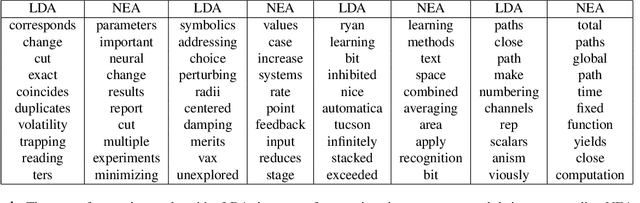
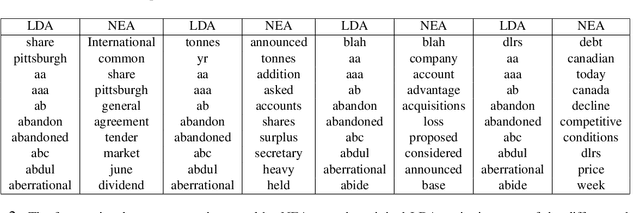

Word embedding models such as the skip-gram learn vector representations of words' semantic relationships, and document embedding models learn similar representations for documents. On the other hand, topic models provide latent representations of the documents' topical themes. To get the benefits of these representations simultaneously, we propose a unifying algorithm, called neural embedding allocation (NEA), which deconstructs topic models into interpretable vector-space embeddings of words, topics, documents, authors, and so on, by learning neural embeddings to mimic the topic models. We showcase NEA's effectiveness and generality on LDA, author-topic models and the recently proposed mixed membership skip gram topic model and achieve better performance with the embeddings compared to several state-of-the-art models. Furthermore, we demonstrate that using NEA to smooth out the topics improves coherence scores over the original topic models when the number of topics is large.