 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVRL: Learning Reward Functions from Multiple Feedback Types with Amortized Variational Inference
Feb 16, 2026Reward learning typically relies on a single feedback type or combines multiple feedback types using manually weighted loss terms. Currently, it remains unclear how to jointly learn reward functions from heterogeneous feedback types such as demonstrations, comparisons, ratings, and stops that provide qualitatively different signals. We address this challenge by formulating reward learning from multiple feedback types as Bayesian inference over a shared latent reward function, where each feedback type contributes information through an explicit likelihood. We introduce a scalable amortized variational inference approach that learns a shared reward encoder and feedback-specific likelihood decoders and is trained by optimizing a single evidence lower bound. Our approach avoids reducing feedback to a common intermediate representation and eliminates the need for manual loss balancing. Across discrete and continuous-control benchmarks, we show that jointly inferred reward posteriors outperform single-type baselines, exploit complementary information across feedback types, and yield policies that are more robust to environment perturbations. The inferred reward uncertainty further provides interpretable signals for analyzing model confidence and consistency across feedback types.
Reward Learning from Multiple Feedback Types
Feb 28, 2025Learning rewards from preference feedback has become an important tool in the alignment of agentic models. Preference-based feedback, often implemented as a binary comparison between multiple completions, is an established method to acquire large-scale human feedback. However, human feedback in other contexts is often much more diverse. Such diverse feedback can better support the goals of a human annotator, and the simultaneous use of multiple sources might be mutually informative for the learning process or carry type-dependent biases for the reward learning process. Despite these potential benefits, learning from different feedback types has yet to be explored extensively. In this paper, we bridge this gap by enabling experimentation and evaluating multi-type feedback in a broad set of environments. We present a process to generate high-quality simulated feedback of six different types. Then, we implement reward models and downstream RL training for all six feedback types. Based on the simulated feedback, we investigate the use of types of feedback across ten RL environments and compare them to pure preference-based baselines. We show empirically that diverse types of feedback can be utilized and lead to strong reward modeling performance. This work is the first strong indicator of the potential of multi-type feedback for RLHF.
Mapping out the Space of Human Feedback for Reinforcement Learning: A Conceptual Framework
Nov 18, 2024



Reinforcement Learning from Human feedback (RLHF) has become a powerful tool to fine-tune or train agentic machine learning models. Similar to how humans interact in social contexts, we can use many types of feedback to communicate our preferences, intentions, and knowledge to an RL agent. However, applications of human feedback in RL are often limited in scope and disregard human factors. In this work, we bridge the gap between machine learning and human-computer interaction efforts by developing a shared understanding of human feedback in interactive learning scenarios. We first introduce a taxonomy of feedback types for reward-based learning from human feedback based on nine key dimensions. Our taxonomy allows for unifying human-centered, interface-centered, and model-centered aspects. In addition, we identify seven quality metrics of human feedback influencing both the human ability to express feedback and the agent's ability to learn from the feedback. Based on the feedback taxonomy and quality criteria, we derive requirements and design choices for systems learning from human feedback. We relate these requirements and design choices to existing work in interactive machine learning. In the process, we identify gaps in existing work and future research opportunities. We call for interdisciplinary collaboration to harness the full potential of reinforcement learning with data-driven co-adaptive modeling and varied interaction mechanics.
RLHF-Blender: A Configurable Interactive Interface for Learning from Diverse Human Feedback
Aug 08, 2023
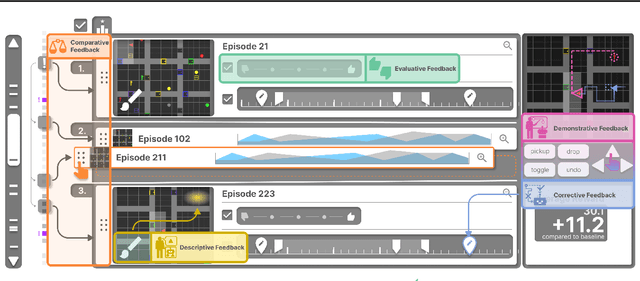
To use reinforcement learning from human feedback (RLHF) in practical applications, it is crucial to learn reward models from diverse sources of human feedback and to consider human factors involved in providing feedback of different types. However, the systematic study of learning from diverse types of feedback is held back by limited standardized tooling available to researchers. To bridge this gap, we propose RLHF-Blender, a configurable, interactive interface for learning from human feedback. RLHF-Blender provides a modular experimentation framework and implementation that enables researchers to systematically investigate the properties and qualities of human feedback for reward learning. The system facilitates the exploration of various feedback types, including demonstrations, rankings, comparisons, and natural language instructions, as well as studies considering the impact of human factors on their effectiveness. We discuss a set of concrete research opportunities enabled by RLHF-Blender. More information is available at https://rlhfblender.info/.
* 14 pages, 3 figures