 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing LLMs for Serendipity Discovery in Knowledge Graphs: A Case for Drug Repurposing
Nov 16, 2025Large Language Models (LLMs) have greatly advanced knowledge graph question answering (KGQA), yet existing systems are typically optimized for returning highly relevant but predictable answers. A missing yet desired capacity is to exploit LLMs to suggest surprise and novel ("serendipitious") answers. In this paper, we formally define the serendipity-aware KGQA task and propose the SerenQA framework to evaluate LLMs' ability to uncover unexpected insights in scientific KGQA tasks. SerenQA includes a rigorous serendipity metric based on relevance, novelty, and surprise, along with an expert-annotated benchmark derived from the Clinical Knowledge Graph, focused on drug repurposing. Additionally, it features a structured evaluation pipeline encompassing three subtasks: knowledge retrieval, subgraph reasoning, and serendipity exploration. Our experiments reveal that while state-of-the-art LLMs perform well on retrieval, they still struggle to identify genuinely surprising and valuable discoveries, underscoring a significant room for future improvements. Our curated resources and extended version are released at: https://cwru-db-group.github.io/serenQA.
Quantifying the Risks of Tool-assisted Rephrasing to Linguistic Diversity
Oct 23, 2024



Writing assistants and large language models see widespread use in the creation of text content. While their effectiveness for individual users has been evaluated in the literature, little is known about their proclivity to change language or reduce its richness when adopted by a large user base. In this paper, we take a first step towards quantifying this risk by measuring the semantic and vocabulary change enacted by the use of rephrasing tools on a multi-domain corpus of human-generated text.
Generating Robust Counterfactual Witnesses for Graph Neural Networks
Apr 30, 2024



This paper introduces a new class of explanation structures, called robust counterfactual witnesses (RCWs), to provide robust, both counterfactual and factual explanations for graph neural networks. Given a graph neural network M, a robust counterfactual witness refers to the fraction of a graph G that are counterfactual and factual explanation of the results of M over G, but also remains so for any "disturbed" G by flipping up to k of its node pairs. We establish the hardness results, from tractable results to co-NP-hardness, for verifying and generating robust counterfactual witnesses. We study such structures for GNN-based node classification, and present efficient algorithms to verify and generate RCWs. We also provide a parallel algorithm to verify and generate RCWs for large graphs with scalability guarantees. We experimentally verify our explanation generation process for benchmark datasets, and showcase their applications.
LAGE: A Java Framework to reconstruct Gene Regulatory Networks from Large-Scale Continues Expression Data
Nov 09, 2012LAGE is a systematic framework developed in Java. The motivation of LAGE is to provide a scalable and parallel solution to reconstruct Gene Regulatory Networks (GRNs) from continuous gene expression data for very large amount of genes. The basic idea of our framework is motivated by the philosophy of divideand-conquer. Specifically, LAGE recursively partitions genes into multiple overlapping communities with much smaller sizes, learns intra-community GRNs respectively before merge them altogether. Besides, the complete information of overlapping communities serves as the byproduct, which could be used to mine meaningful functional modules in biological networks.
LSBN: A Large-Scale Bayesian Structure Learning Framework for Model Averaging
Oct 18, 2012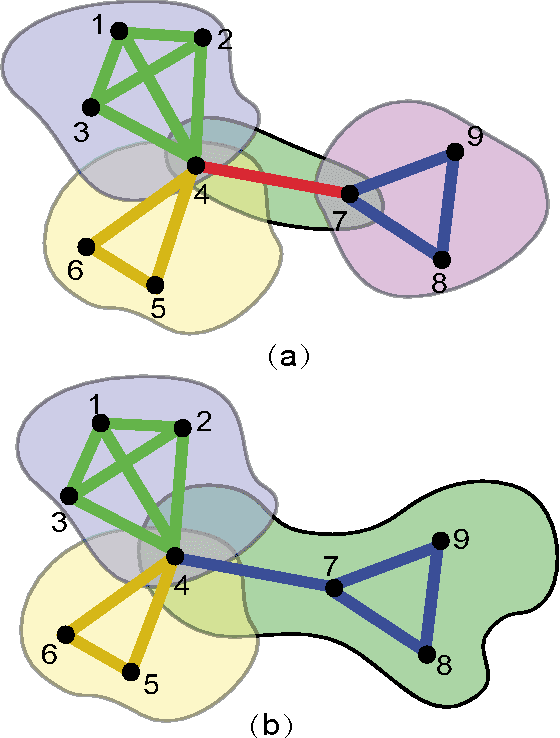
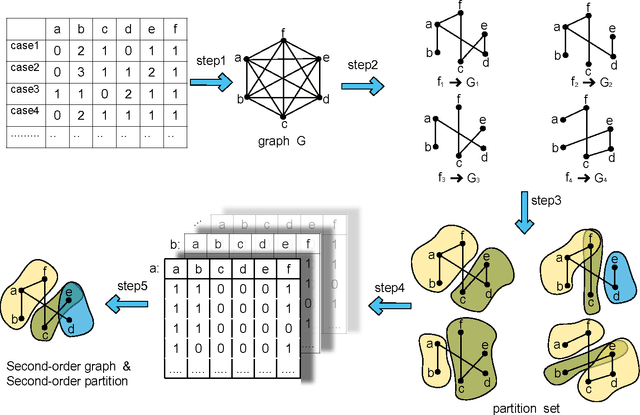
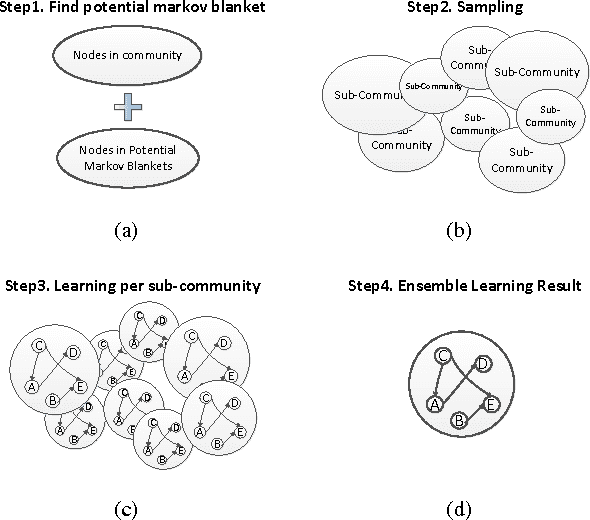

The motivation for this paper is to apply Bayesian structure learning using Model Averaging in large-scale networks. Currently, Bayesian model averaging algorithm is applicable to networks with only tens of variables, restrained by its super-exponential complexity. We present a novel framework, called LSBN(Large-Scale Bayesian Network), making it possible to handle networks with infinite size by following the principle of divide-and-conquer. The method of LSBN comprises three steps. In general, LSBN first performs the partition by using a second-order partition strategy, which achieves more robust results. LSBN conducts sampling and structure learning within each overlapping community after the community is isolated from other variables by Markov Blanket. Finally LSBN employs an efficient algorithm, to merge structures of overlapping communities into a whole. In comparison with other four state-of-art large-scale network structure learning algorithms such as ARACNE, PC, Greedy Search and MMHC, LSBN shows comparable results in five common benchmark datasets, evaluated by precision, recall and f-score. What's more, LSBN makes it possible to learn large-scale Bayesian structure by Model Averaging which used to be intractable. In summary, LSBN provides an scalable and parallel framework for the reconstruction of network structures. Besides, the complete information of overlapping communities serves as the byproduct, which could be used to mine meaningful clusters in biological networks, such as protein-protein-interaction network or gene regulatory network, as well as in social network.