 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch engines in polarized media environment: Auditing political information curation on Google and Bing prior to 2024 US elections
Jan 08, 2025



Search engines play an important role in the context of modern elections. By curating information in response to user queries, search engines influence how individuals are informed about election-related developments and perceive the media environment in which elections take place. It has particular implications for (perceived) polarization, especially if search engines' curation results in a skewed treatment of information sources based on their political leaning. Until now, however, it is unclear whether such a partisan gap emerges through information curation on search engines and what user- and system-side factors affect it. To address this shortcoming, we audit the two largest Western search engines, Google and Bing, prior to the 2024 US presidential elections and examine how these search engines' organic search results and additional interface elements represent election-related information depending on the queries' slant, user location, and time when the search was conducted. Our findings indicate that both search engines tend to prioritize left-leaning media sources, with the exact scope of search results' ideological slant varying between Democrat- and Republican-focused queries. We also observe limited effects of location- and time-based factors on organic search results, whereas results for additional interface elements were more volatile over time and specific US states. Together, our observations highlight that search engines' information curation actively mirrors the partisan divides present in the US media environments and has the potential to contribute to (perceived) polarization within these environments.
Finding frames with BERT: A transformer-based approach to generic news frame detection
Aug 30, 2024Framing is among the most extensively used concepts in the field of communication science. The availability of digital data offers new possibilities for studying how specific aspects of social reality are made more salient in online communication but also raises challenges related to the scaling of framing analysis and its adoption to new research areas (e.g. studying the impact of artificial intelligence-powered systems on representation of societally relevant issues). To address these challenges, we introduce a transformer-based approach for generic news frame detection in Anglophone online content. While doing so, we discuss the composition of the training and test datasets, the model architecture, and the validation of the approach and reflect on the possibilities and limitations of the automated detection of generic news frames.
Algorithmically Curated Lies: How Search Engines Handle Misinformation about US Biolabs in Ukraine
Jan 24, 2024



The growing volume of online content prompts the need for adopting algorithmic systems of information curation. These systems range from web search engines to recommender systems and are integral for helping users stay informed about important societal developments. However, unlike journalistic editing the algorithmic information curation systems (AICSs) are known to be subject to different forms of malperformance which make them vulnerable to possible manipulation. The risk of manipulation is particularly prominent in the case when AICSs have to deal with information about false claims that underpin propaganda campaigns of authoritarian regimes. Using as a case study of the Russian disinformation campaign concerning the US biolabs in Ukraine, we investigate how one of the most commonly used forms of AICSs - i.e. web search engines - curate misinformation-related content. For this aim, we conduct virtual agent-based algorithm audits of Google, Bing, and Yandex search outputs in June 2022. Our findings highlight the troubling performance of search engines. Even though some search engines, like Google, were less likely to return misinformation results, across all languages and locations, the three search engines still mentioned or promoted a considerable share of false content (33% on Google; 44% on Bing, and 70% on Yandex). We also find significant disparities in misinformation exposure based on the language of search, with all search engines presenting a higher number of false stories in Russian. Location matters as well with users from Germany being more likely to be exposed to search results promoting false information. These observations stress the possibility of AICSs being vulnerable to manipulation, in particular in the case of the unfolding propaganda campaigns, and underline the importance of monitoring performance of these systems to prevent it.
Panning for gold: Lessons learned from the platform-agnostic automated detection of political content in textual data
Jul 01, 2022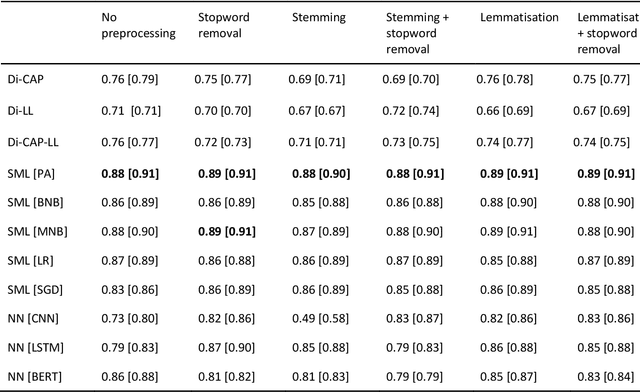
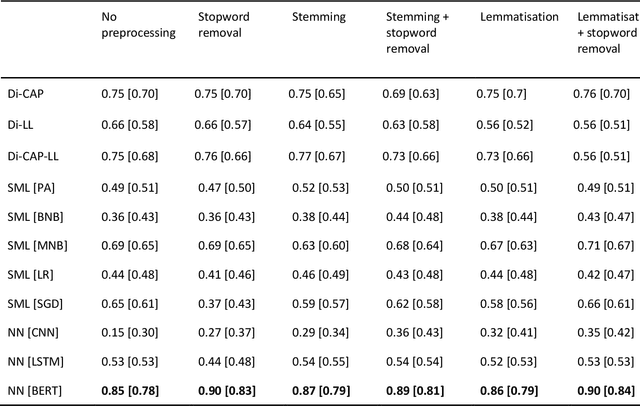
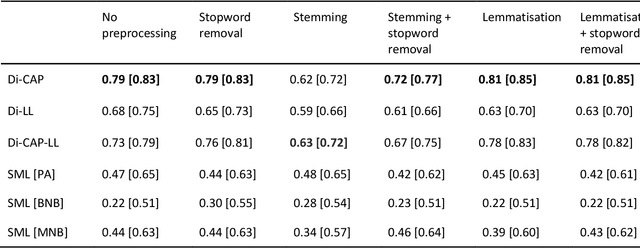
The growing availability of data about online information behaviour enables new possibilities for political communication research. However, the volume and variety of these data makes them difficult to analyse and prompts the need for developing automated content approaches relying on a broad range of natural language processing techniques (e.g. machine learning- or neural network-based ones). In this paper, we discuss how these techniques can be used to detect political content across different platforms. Using three validation datasets, which include a variety of political and non-political textual documents from online platforms, we systematically compare the performance of three groups of detection techniques relying on dictionaries, supervised machine learning, or neural networks. We also examine the impact of different modes of data preprocessing (e.g. stemming and stopword removal) on the low-cost implementations of these techniques using a large set (n = 66) of detection models. Our results show the limited impact of preprocessing on model performance, with the best results for less noisy data being achieved by neural network- and machine-learning-based models, in contrast to the more robust performance of dictionary-based models on noisy data.