 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Co-Distillation for Personalized Federated Learning
Paper and Code

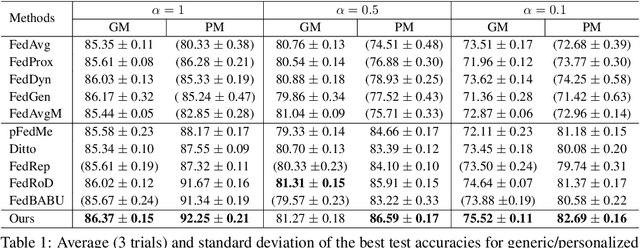
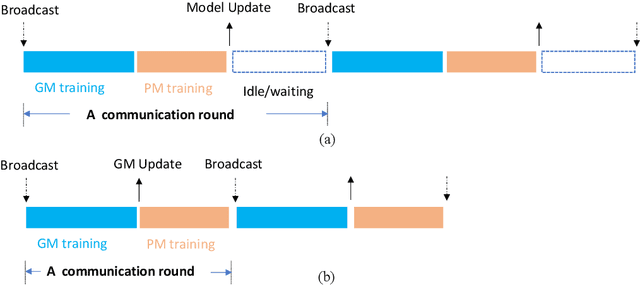
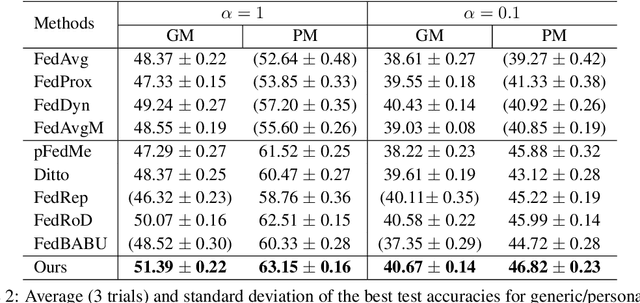
Personalized federated learning (PFL) has been widely investigated to address the challenge of data heterogeneity, especially when a single generic model is inadequate in satisfying the diverse performance requirements of local clients simultaneously. Existing PFL methods are inherently based on the idea that the relations between the generic global and personalized local models are captured by the similarity of model weights. Such a similarity is primarily based on either partitioning the model architecture into generic versus personalized components, or modeling client relationships via model weights. To better capture similar (yet distinct) generic versus personalized model representations, we propose \textit{spectral distillation}, a novel distillation method based on model spectrum information. Building upon spectral distillation, we also introduce a co-distillation framework that establishes a two-way bridge between generic and personalized model training. Moreover, to utilize the local idle time in conventional PFL, we propose a wait-free local training protocol. Through extensive experiments on multiple datasets over diverse heterogeneous data settings, we demonstrate the outperformance and efficacy of our proposed spectral co-distillation method, as well as our wait-free training protocol.