 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEEP: An Industrial Pre-Training Framework for Online Recommendation via Knowledge Extraction and Plugging
Aug 22, 2022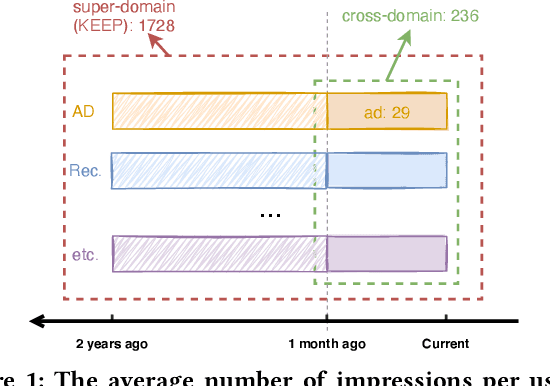

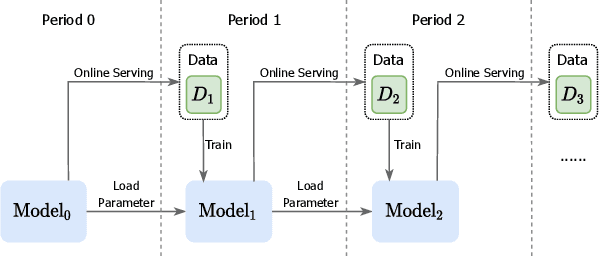
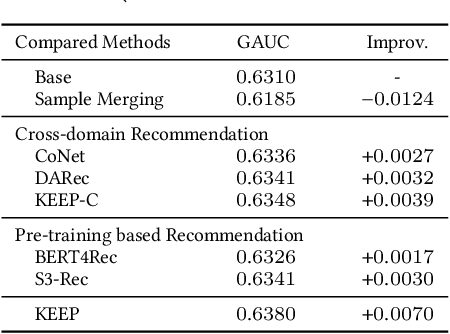
An industrial recommender system generally presents a hybrid list that contains results from multiple subsystems. In practice, each subsystem is optimized with its own feedback data to avoid the disturbance among different subsystems. However, we argue that such data usage may lead to sub-optimal online performance because of the \textit{data sparsity}. To alleviate this issue, we propose to extract knowledge from the \textit{super-domain} that contains web-scale and long-time impression data, and further assist the online recommendation task (downstream task). To this end, we propose a novel industrial \textbf{K}nowl\textbf{E}dge \textbf{E}xtraction and \textbf{P}lugging (\textbf{KEEP}) framework, which is a two-stage framework that consists of 1) a supervised pre-training knowledge extraction module on super-domain, and 2) a plug-in network that incorporates the extracted knowledge into the downstream model. This makes it friendly for incremental training of online recommendation. Moreover, we design an efficient empirical approach for KEEP and introduce our hands-on experience during the implementation of KEEP in a large-scale industrial system. Experiments conducted on two real-world datasets demonstrate that KEEP can achieve promising results. It is notable that KEEP has also been deployed on the display advertising system in Alibaba, bringing a lift of $+5.4\%$ CTR and $+4.7\%$ RPM.
Adversarial Gradient Driven Exploration for Deep Click-Through Rate Prediction
Dec 21, 2021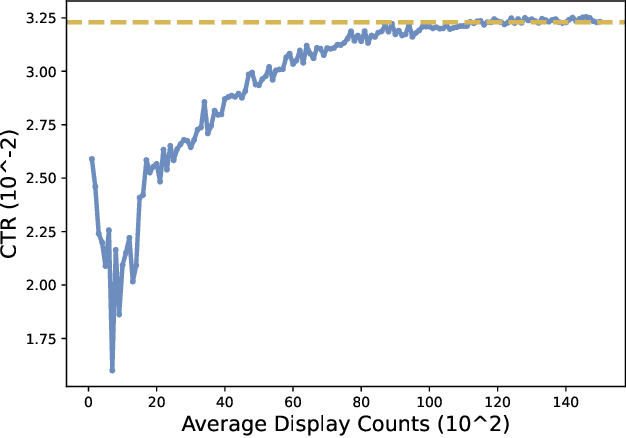
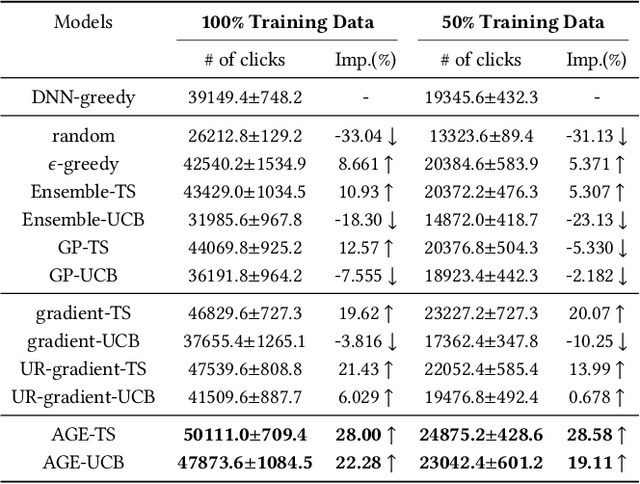
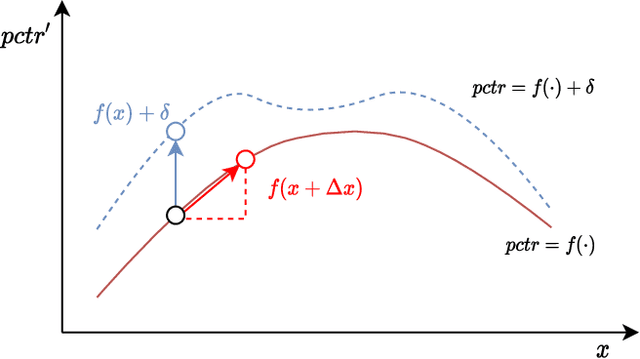
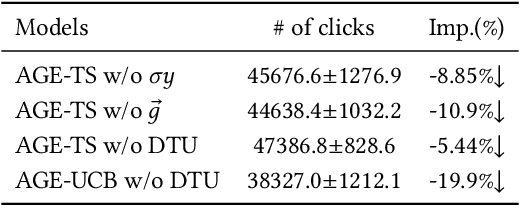
Nowadays, data-driven deep neural models have already shown remarkable progress on Click-through Rate (CTR) prediction. Unfortunately, the effectiveness of such models may fail when there are insufficient data. To handle this issue, researchers often adopt exploration strategies to examine items based on the estimated reward, e.g., UCB or Thompson Sampling. In the context of Exploitation-and-Exploration for CTR prediction, recent studies have attempted to utilize the prediction uncertainty along with model prediction as the reward score. However, we argue that such an approach may make the final ranking score deviate from the original distribution, and thereby affect model performance in the online system. In this paper, we propose a novel exploration method called \textbf{A}dversarial \textbf{G}radient Driven \textbf{E}xploration (AGE). Specifically, we propose a Pseudo-Exploration Module to simulate the gradient updating process, which can approximate the influence of the samples of to-be-explored items for the model. In addition, for better exploration efficiency, we propose an Dynamic Threshold Unit to eliminate the effects of those samples with low potential CTR. The effectiveness of our approach was demonstrated on an open-access academic dataset. Meanwhile, AGE has also been deployed in a real-world display advertising platform and all online metrics have been significantly improved.
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
Nov 11, 2020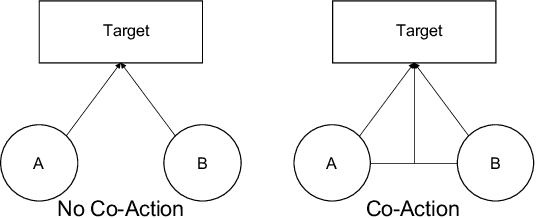
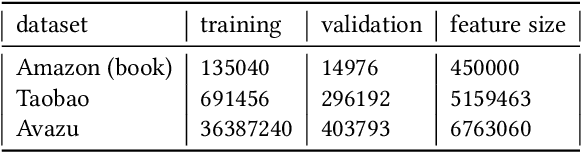
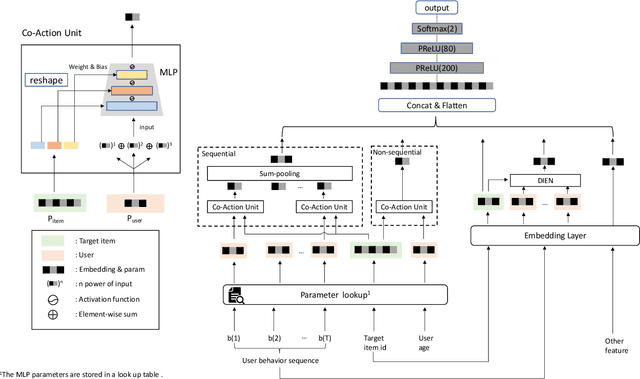
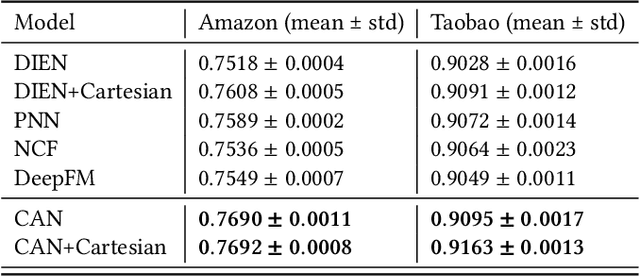
Inspired by the success of deep learning, recent industrial Click-Through Rate (CTR) prediction models have made the transition from traditional shallow approaches to deep approaches. Deep Neural Networks (DNNs) are known for its ability to learn non-linear interactions from raw feature automatically, however, the non-linear feature interaction is learned in an implicit manner. The non-linear interaction may be hard to capture and explicitly model the \textit{co-action} of raw feature is beneficial for CTR prediction. \textit{Co-action} refers to the collective effects of features toward final prediction. In this paper, we argue that current CTR models do not fully explore the potential of feature co-action. We conduct experiments and show that the effect of feature co-action is underestimated seriously. Motivated by our observation, we propose feature Co-Action Network (CAN) to explore the potential of feature co-action. The proposed model can efficiently and effectively capture the feature co-action, which improves the model performance while reduce the storage and computation consumption. Experiment results on public and industrial datasets show that CAN outperforms state-of-the-art CTR models by a large margin. Up to now, CAN has been deployed in the Alibaba display advertisement system, obtaining averaging 12\% improvement on CTR and 8\% on RPM.
Res-embedding for Deep Learning Based Click-Through Rate Prediction Modeling
Jun 25, 2019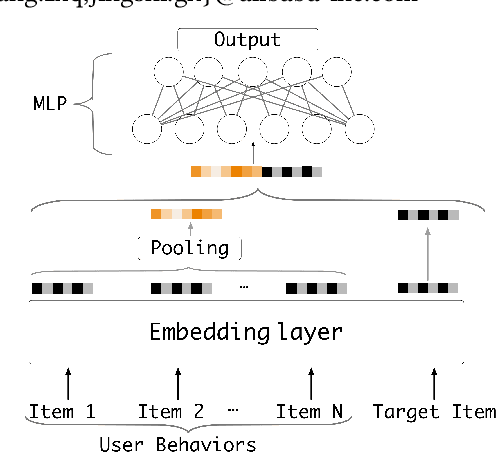
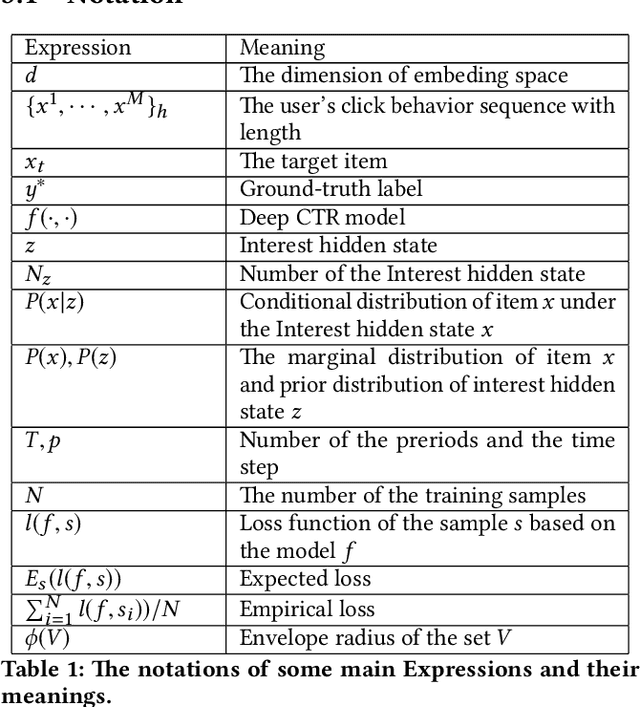
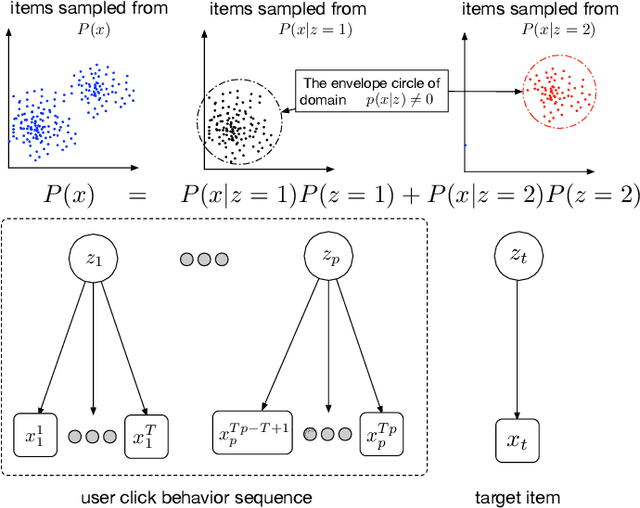
Recently, click-through rate (CTR) prediction models have evolved from shallow methods to deep neural networks. Most deep CTR models follow an Embedding\&MLP paradigm, that is, first mapping discrete id features, e.g. user visited items, into low dimensional vectors with an embedding module, then learn a multi-layer perception (MLP) to fit the target. In this way, embedding module performs as the representative learning and plays a key role in the model performance. However, in many real-world applications, deep CTR model often suffers from poor generalization performance, which is mostly due to the learning of embedding parameters. In this paper, we model user behavior using an interest delay model, study carefully the embedding mechanism, and obtain two important results: (i) We theoretically prove that small aggregation radius of embedding vectors of items which belongs to a same user interest domain will result in good generalization performance of deep CTR model. (ii) Following our theoretical analysis, we design a new embedding structure named res-embedding. In res-embedding module, embedding vector of each item is the sum of two components: (i) a central embedding vector calculated from an item-based interest graph (ii) a residual embedding vector with its scale to be relatively small. Empirical evaluation on several public datasets demonstrates the effectiveness of the proposed res-embedding structure, which brings significant improvement on the model performance.
Deep Interest Evolution Network for Click-Through Rate Prediction
Nov 06, 2018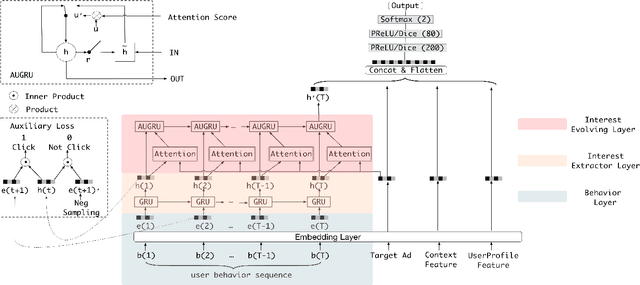

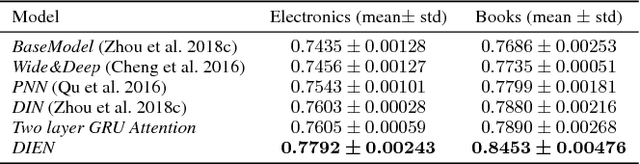
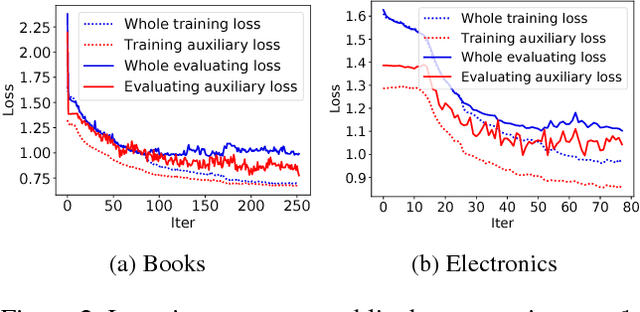
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.
Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net
Mar 15, 2018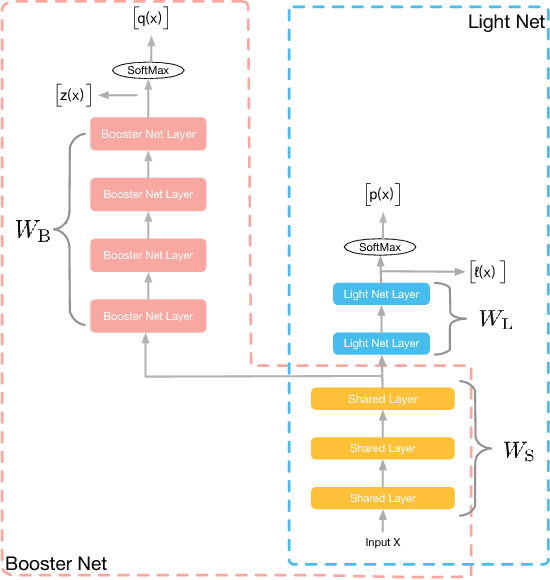

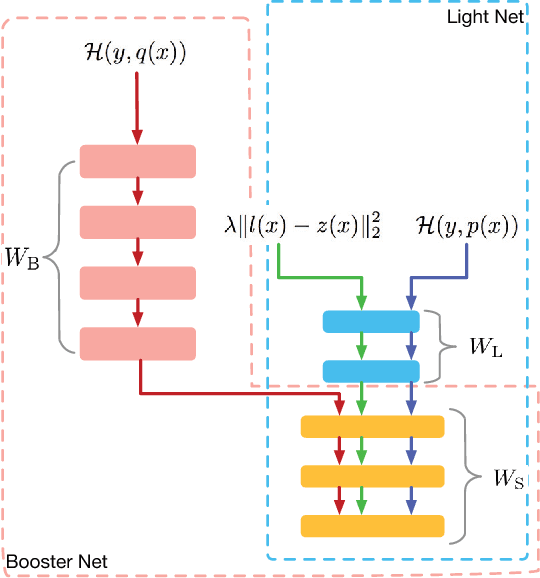

Models applied on real time response task, like click-through rate (CTR) prediction model, require high accuracy and rigorous response time. Therefore, top-performing deep models of high depth and complexity are not well suited for these applications with the limitations on the inference time. In order to further improve the neural networks' performance given the time and computational limitations, we propose an approach that exploits a cumbersome net to help train the lightweight net for prediction. We dub the whole process rocket launching, where the cumbersome booster net is used to guide the learning of the target light net throughout the whole training process. We analyze different loss functions aiming at pushing the light net to behave similarly to the booster net, and adopt the loss with best performance in our experiments. We use one technique called gradient block to improve the performance of the light net and booster net further. Experiments on benchmark datasets and real-life industrial advertisement data present that our light model can get performance only previously achievable with more complex models.