 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Regression for Continuous Value Prediction using Residual Quantization
Feb 26, 2026Continuous value prediction plays a crucial role in industrial-scale recommendation systems, including tasks such as predicting users' watch-time and estimating the gross merchandise value (GMV) in e-commerce transactions. However, it remains challenging due to the highly complex and long-tailed nature of the data distributions. Existing generative approaches rely on rigid parametric distribution assumptions, which fundamentally limits their performance when such assumptions misalign with real-world data. Overly simplified forms cannot adequately model real-world complexities, while more intricate assumptions often suffer from poor scalability and generalization. To address these challenges, we propose a residual quantization (RQ)-based sequence learning framework that represents target continuous values as a sum of ordered quantization codes, predicted recursively from coarse to fine granularity with diminishing quantization errors. We introduce a representation learning objective that aligns RQ code embedding space with the ordinal structure of target values, allowing the model to capture continuous representations for quantization codes and further improving prediction accuracy. We perform extensive evaluations on public benchmarks for lifetime value (LTV) and watch-time prediction, alongside a large-scale online experiment for GMV prediction on an industrial short-video recommendation platform. The results consistently show that our approach outperforms state-of-the-art methods, while demonstrating strong generalization across diverse continuous value prediction tasks in recommendation systems.
Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net
Mar 15, 2018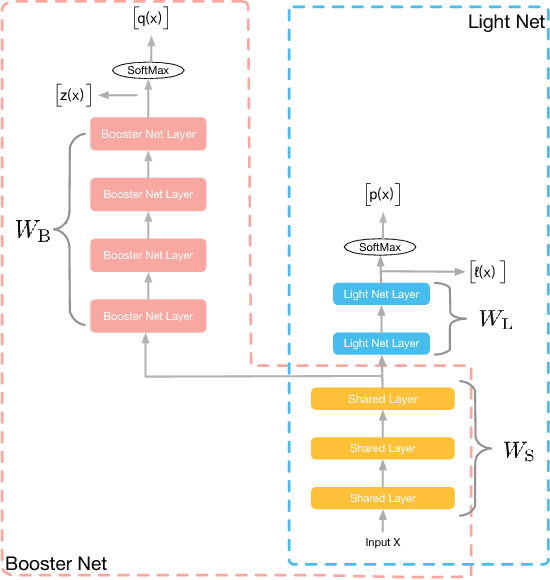

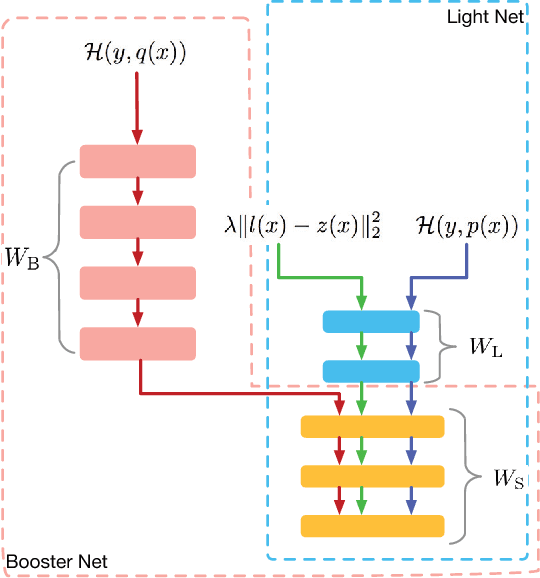

Models applied on real time response task, like click-through rate (CTR) prediction model, require high accuracy and rigorous response time. Therefore, top-performing deep models of high depth and complexity are not well suited for these applications with the limitations on the inference time. In order to further improve the neural networks' performance given the time and computational limitations, we propose an approach that exploits a cumbersome net to help train the lightweight net for prediction. We dub the whole process rocket launching, where the cumbersome booster net is used to guide the learning of the target light net throughout the whole training process. We analyze different loss functions aiming at pushing the light net to behave similarly to the booster net, and adopt the loss with best performance in our experiments. We use one technique called gradient block to improve the performance of the light net and booster net further. Experiments on benchmark datasets and real-life industrial advertisement data present that our light model can get performance only previously achievable with more complex models.
Aligning where to see and what to tell: image caption with region-based attention and scene factorization
Jun 20, 2015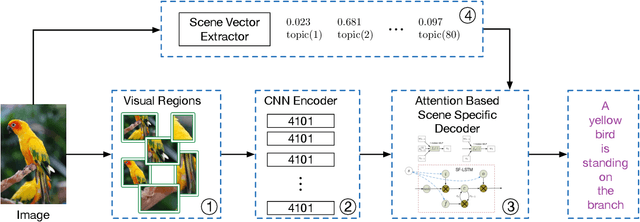
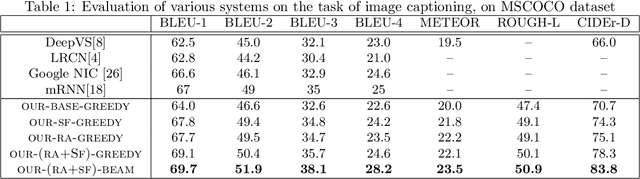
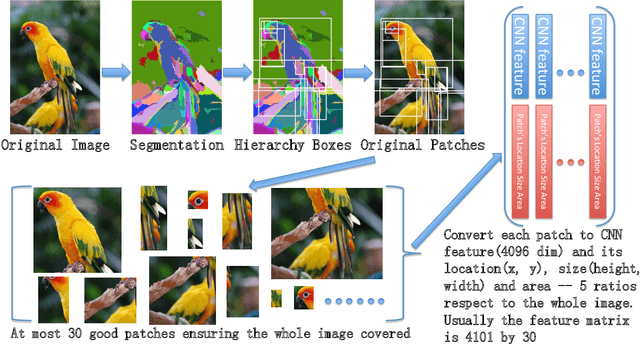
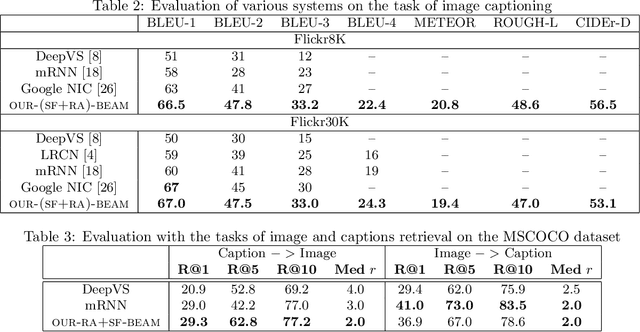
Recent progress on automatic generation of image captions has shown that it is possible to describe the most salient information conveyed by images with accurate and meaningful sentences. In this paper, we propose an image caption system that exploits the parallel structures between images and sentences. In our model, the process of generating the next word, given the previously generated ones, is aligned with the visual perception experience where the attention shifting among the visual regions imposes a thread of visual ordering. This alignment characterizes the flow of "abstract meaning", encoding what is semantically shared by both the visual scene and the text description. Our system also makes another novel modeling contribution by introducing scene-specific contexts that capture higher-level semantic information encoded in an image. The contexts adapt language models for word generation to specific scene types. We benchmark our system and contrast to published results on several popular datasets. We show that using either region-based attention or scene-specific contexts improves systems without those components. Furthermore, combining these two modeling ingredients attains the state-of-the-art performance.