 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEEP: An Industrial Pre-Training Framework for Online Recommendation via Knowledge Extraction and Plugging
Paper and Code
Aug 22, 2022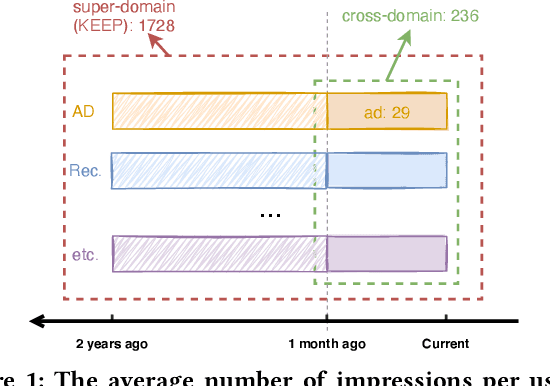

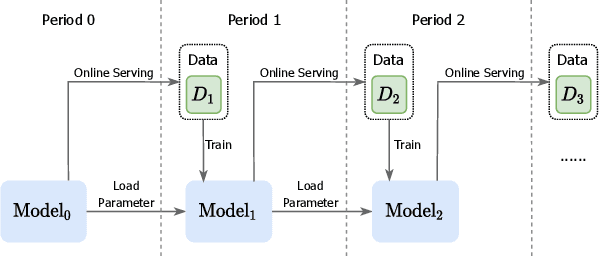
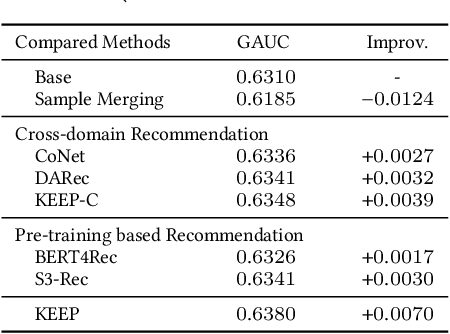
An industrial recommender system generally presents a hybrid list that contains results from multiple subsystems. In practice, each subsystem is optimized with its own feedback data to avoid the disturbance among different subsystems. However, we argue that such data usage may lead to sub-optimal online performance because of the \textit{data sparsity}. To alleviate this issue, we propose to extract knowledge from the \textit{super-domain} that contains web-scale and long-time impression data, and further assist the online recommendation task (downstream task). To this end, we propose a novel industrial \textbf{K}nowl\textbf{E}dge \textbf{E}xtraction and \textbf{P}lugging (\textbf{KEEP}) framework, which is a two-stage framework that consists of 1) a supervised pre-training knowledge extraction module on super-domain, and 2) a plug-in network that incorporates the extracted knowledge into the downstream model. This makes it friendly for incremental training of online recommendation. Moreover, we design an efficient empirical approach for KEEP and introduce our hands-on experience during the implementation of KEEP in a large-scale industrial system. Experiments conducted on two real-world datasets demonstrate that KEEP can achieve promising results. It is notable that KEEP has also been deployed on the display advertising system in Alibaba, bringing a lift of $+5.4\%$ CTR and $+4.7\%$ RPM.