 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring AI-Augmented Sensemaking of Patient-Generated Health Data: A Mixed-Method Study with Healthcare Professionals in Cardiac Risk Reduction
Feb 05, 2026Individuals are increasingly generating substantial personal health and lifestyle data, e.g. through wearables and smartphones. While such data could transform preventative care, its integration into clinical practice is hindered by its scale, heterogeneity and the time pressure and data literacy of healthcare professionals (HCPs). We explore how large language models (LLMs) can support sensemaking of patient-generated health data (PGHD) with automated summaries and natural language data exploration. Using cardiovascular disease (CVD) risk reduction as a use case, 16 HCPs reviewed multimodal PGHD in a mixed-methods study with a prototype that integrated common charts, LLM-generated summaries, and a conversational interface. Findings show that AI summaries provided quick overviews that anchored exploration, while conversational interaction supported flexible analysis and bridged data-literacy gaps. However, HCPs raised concerns about transparency, privacy, and overreliance. We contribute empirical insights and sociotechnical design implications for integrating AI-driven summarization and conversation into clinical workflows to support PGHD sensemaking.
Expectations, Explanations, and Embodiment: Attempts at Robot Failure Recovery
Apr 09, 2025
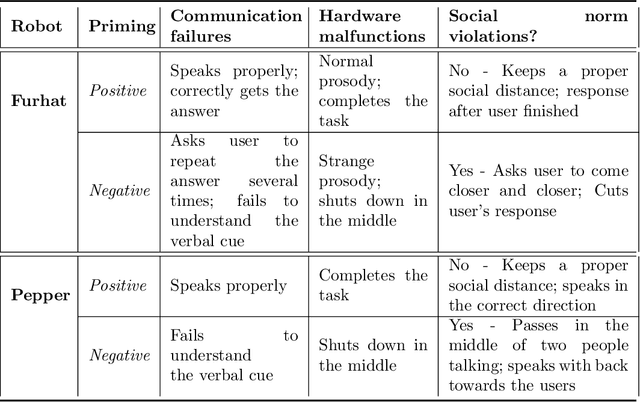
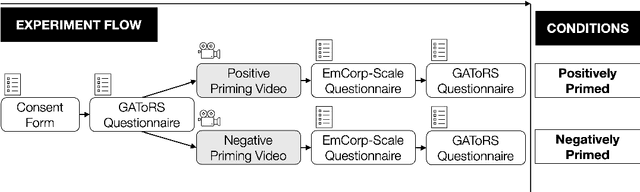
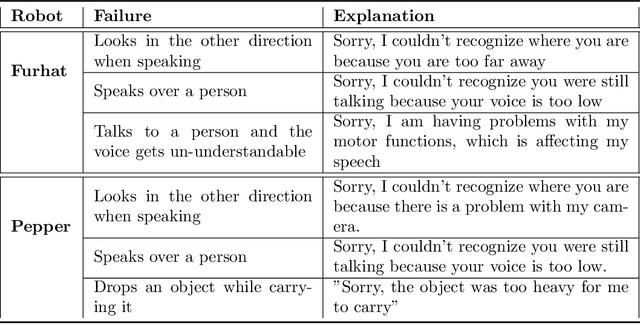
Expectations critically shape how people form judgments about robots, influencing whether they view failures as minor technical glitches or deal-breaking flaws. This work explores how high and low expectations, induced through brief video priming, affect user perceptions of robot failures and the utility of explanations in HRI. We conducted two online studies ($N=600$ total participants); each replicated two robots with different embodiments, Furhat and Pepper. In our first study, grounded in expectation theory, participants were divided into two groups, one primed with positive and the other with negative expectations regarding the robot's performance, establishing distinct expectation frameworks. This validation study aimed to verify whether the videos could reliably establish low and high-expectation profiles. In the second study, participants were primed using the validated videos and then viewed a new scenario in which the robot failed at a task. Half viewed a version where the robot explained its failure, while the other half received no explanation. We found that explanations significantly improved user perceptions of Furhat, especially when participants were primed to have lower expectations. Explanations boosted satisfaction and enhanced the robot's perceived expressiveness, indicating that effectively communicating the cause of errors can help repair user trust. By contrast, Pepper's explanations produced minimal impact on user attitudes, suggesting that a robot's embodiment and style of interaction could determine whether explanations can successfully offset negative impressions. Together, these findings underscore the need to consider users' expectations when tailoring explanation strategies in HRI. When expectations are initially low, a cogent explanation can make the difference between dismissing a failure and appreciating the robot's transparency and effort to communicate.
Classification of Higher Mobility Linkages
Mar 08, 2021



We provide a complete classification of paradoxical $n$-linkages, $n\geq6$ whose mobility is $n-4$ or higher containing $R$, $P$ or $H$ joints. We also explicitly write down strong necessary conditions for $nR$-linkages of mobility $n-5$.