 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Conv: A Multimodal Dataset and Benchmark for Context-Aware Grounding in 3D Dialogue
May 20, 2026Grounding language in the physical world requires AI systems to interpret references that emerge dynamically during conversation. While current vision-language models (VLMs) excel at static image tasks, they struggle to resolve ambiguous expressions in spontaneous, multi-turn dialogue. We address this gap by introducing (1) a benchmark for referential communication in dynamic 3D environments, built from 6.7 hours of egocentric VR interaction with synchronized speech, motion, gaze, and 3D scene geometry, and (2) a two-stage grounding pipeline that explicitly resolves conversational ambiguity before visual localization. The benchmark includes over 4,200 manually verified referring expressions spanning full, partitive, and pronominal types. Our contextual rewriting approach improves grounding performance by 11-22 percentage points on average, with a pure detector (GroundingDINO) reaching 56.7% on pronominals after rewriting, nearly double the best end-to-end baseline. Results demonstrate that decoupling linguistic reasoning from visual perception is more effective than end-to-end approaches for conversational grounding.
* Extended version of the paper published at LREC 2026 (Palma de Mallorca, Spain), with expanded VLM baselines and inter-annotator agreement analysis
FAIR_XAI: Improving Multimodal Foundation Model Fairness via Explainability for Wellbeing Assessment
Apr 26, 2026In recent years, the integration of multimodal machine learning in wellbeing assessment has offered transformative potential for monitoring mental health. However, with the rapid advancement of Vision-Language Models (VLMs), their deployment in clinical settings has raised concerns due to their lack of transparency and potential for bias. While previous research has explored the intersection of fairness and Explainable AI (XAI), its application to VLMs for wellbeing assessment and depression prediction remains under-explored. This work investigates VLM performance across laboratory (AFAR-BSFT) and naturalistic (E-DAIC) datasets, focusing on diagnostic reliability and demographic fairness. Performance varied substantially across environments and architectures; Phi3.5-Vision achieved 80.4% accuracy on E-DAIC, while Qwen2-VL struggled at 33.9%. Additionally, both models demonstrated a tendency to over-predict depression on AFAR-BSFT. Although bias existed across both architectures, Qwen2-VL showed higher gender disparities, while Phi-3.5-Vision exhibited more racial bias. Our XAI intervention framework yielded mixed results; fairness prompting achieved perfect equal opportunity for Qwen2-VL at a severe accuracy cost on E-DAIC. On AFAR-BSFT, explainability-based interventions improved procedural consistency but did not guarantee outcome fairness, sometimes amplifying racial bias. These results highlight a persistent gap between procedural transparency and equitable outcomes. We analyse these findings and consolidate concrete recommendations for addressing them, emphasising that future fairness interventions must jointly optimise predictive accuracy, demographic parity, and cross-domain generalisation.
Investigating Associational Biases in Inter-Model Communication of Large Generative Models
Jan 29, 2026Social bias in generative AI can manifest not only as performance disparities but also as associational bias, whereby models learn and reproduce stereotypical associations between concepts and demographic groups, even in the absence of explicit demographic information (e.g., associating doctors with men). These associations can persist, propagate, and potentially amplify across repeated exchanges in inter-model communication pipelines, where one generative model's output becomes another's input. This is especially salient for human-centred perception tasks, such as human activity recognition and affect prediction, where inferences about behaviour and internal states can lead to errors or stereotypical associations that propagate into unequal treatment. In this work, focusing on human activity and affective expression, we study how such associations evolve within an inter-model communication pipeline that alternates between image generation and image description. Using the RAF-DB and PHASE datasets, we quantify demographic distribution drift induced by model-to-model information exchange and assess whether these drifts are systematic using an explainability pipeline. Our results reveal demographic drifts toward younger representations for both actions and emotions, as well as toward more female-presenting representations, primarily for emotions. We further find evidence that some predictions are supported by spurious visual regions (e.g., background or hair) rather than concept-relevant cues (e.g., body or face). We also examine whether these demographic drifts translate into measurable differences in downstream behaviour, i.e., while predicting activity and emotion labels. Finally, we outline mitigation strategies spanning data-centric, training and deployment interventions, and emphasise the need for careful safeguards when deploying interconnected models in human-centred AI systems.
Expectations, Explanations, and Embodiment: Attempts at Robot Failure Recovery
Apr 09, 2025
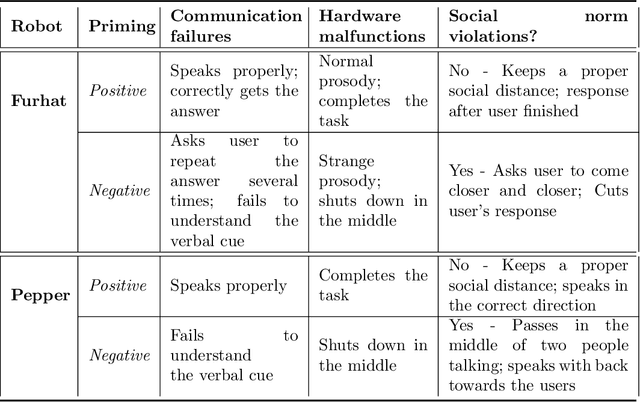
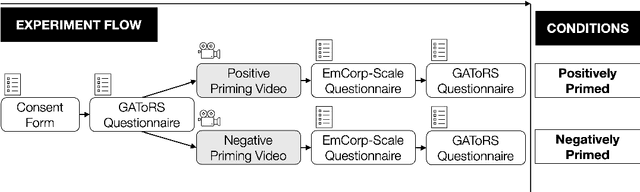
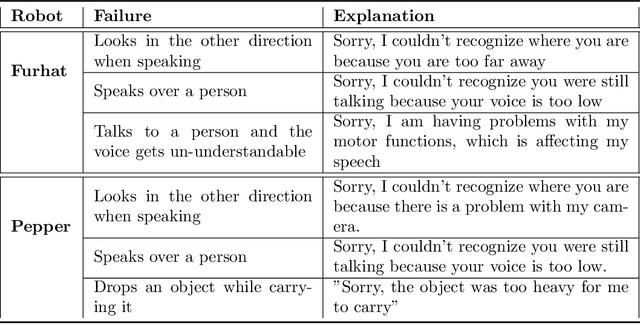
Expectations critically shape how people form judgments about robots, influencing whether they view failures as minor technical glitches or deal-breaking flaws. This work explores how high and low expectations, induced through brief video priming, affect user perceptions of robot failures and the utility of explanations in HRI. We conducted two online studies ($N=600$ total participants); each replicated two robots with different embodiments, Furhat and Pepper. In our first study, grounded in expectation theory, participants were divided into two groups, one primed with positive and the other with negative expectations regarding the robot's performance, establishing distinct expectation frameworks. This validation study aimed to verify whether the videos could reliably establish low and high-expectation profiles. In the second study, participants were primed using the validated videos and then viewed a new scenario in which the robot failed at a task. Half viewed a version where the robot explained its failure, while the other half received no explanation. We found that explanations significantly improved user perceptions of Furhat, especially when participants were primed to have lower expectations. Explanations boosted satisfaction and enhanced the robot's perceived expressiveness, indicating that effectively communicating the cause of errors can help repair user trust. By contrast, Pepper's explanations produced minimal impact on user attitudes, suggesting that a robot's embodiment and style of interaction could determine whether explanations can successfully offset negative impressions. Together, these findings underscore the need to consider users' expectations when tailoring explanation strategies in HRI. When expectations are initially low, a cogent explanation can make the difference between dismissing a failure and appreciating the robot's transparency and effort to communicate.
AsyReC: A Multimodal Graph-based Framework for Spatio-Temporal Asymmetric Dyadic Relationship Classification
Apr 07, 2025Dyadic social relationships, which refer to relationships between two individuals who know each other through repeated interactions (or not), are shaped by shared spatial and temporal experiences. Current computational methods for modeling these relationships face three major challenges: (1) the failure to model asymmetric relationships, e.g., one individual may perceive the other as a friend while the other perceives them as an acquaintance, (2) the disruption of continuous interactions by discrete frame sampling, which segments the temporal continuity of interaction in real-world scenarios, and (3) the limitation to consider periodic behavioral cues, such as rhythmic vocalizations or recurrent gestures, which are crucial for inferring the evolution of dyadic relationships. To address these challenges, we propose AsyReC, a multimodal graph-based framework for asymmetric dyadic relationship classification, with three core innovations: (i) a triplet graph neural network with node-edge dual attention that dynamically weights multimodal cues to capture interaction asymmetries (addressing challenge 1); (ii) a clip-level relationship learning architecture that preserves temporal continuity, enabling fine-grained modeling of real-world interaction dynamics (addressing challenge 2); and (iii) a periodic temporal encoder that projects time indices onto sine/cosine waveforms to model recurrent behavioral patterns (addressing challenge 3). Extensive experiments on two public datasets demonstrate state-of-the-art performance, while ablation studies validate the critical role of asymmetric interaction modeling and periodic temporal encoding in improving the robustness of dyadic relationship classification in real-world scenarios. Our code is publicly available at: https://github.com/tw-repository/AsyReC.
Robot-Led Vision Language Model Wellbeing Assessment of Children
Apr 03, 2025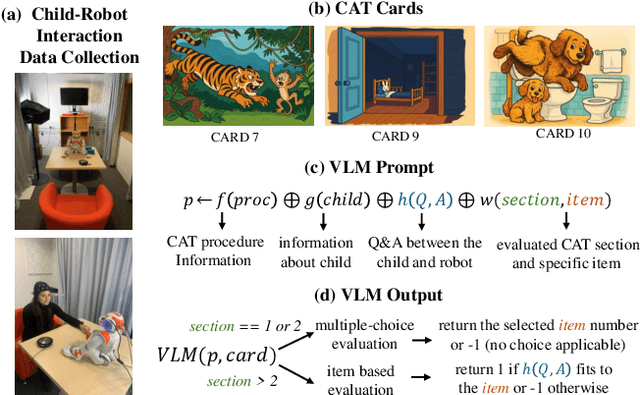
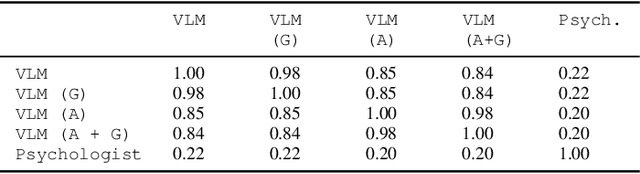
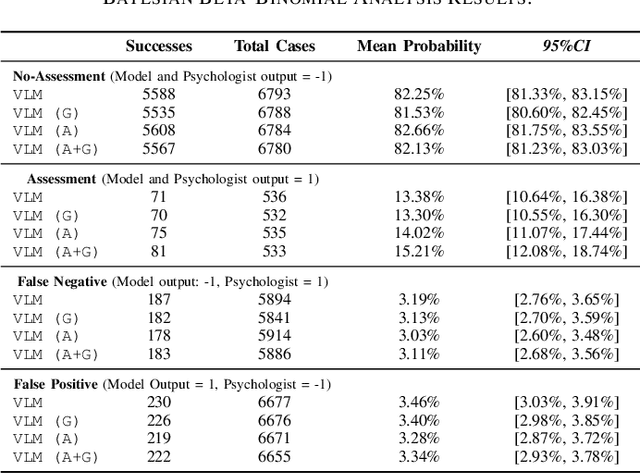
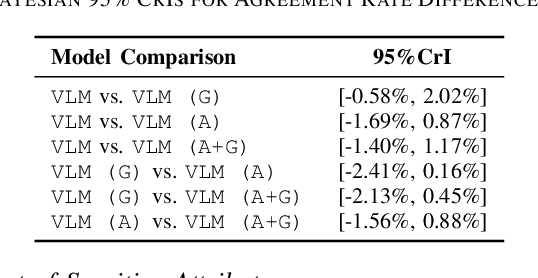
This study presents a novel robot-led approach to assessing children's mental wellbeing using a Vision Language Model (VLM). Inspired by the Child Apperception Test (CAT), the social robot NAO presented children with pictorial stimuli to elicit their verbal narratives of the images, which were then evaluated by a VLM in accordance with CAT assessment guidelines. The VLM's assessments were systematically compared to those provided by a trained psychologist. The results reveal that while the VLM demonstrates moderate reliability in identifying cases with no wellbeing concerns, its ability to accurately classify assessments with clinical concern remains limited. Moreover, although the model's performance was generally consistent when prompted with varying demographic factors such as age and gender, a significantly higher false positive rate was observed for girls, indicating potential sensitivity to gender attribute. These findings highlight both the promise and the challenges of integrating VLMs into robot-led assessments of children's wellbeing.
BT-ACTION: A Test-Driven Approach for Modular Understanding of User Instruction Leveraging Behaviour Trees and LLMs
Apr 03, 2025Natural language instructions are often abstract and complex, requiring robots to execute multiple subtasks even for seemingly simple queries. For example, when a user asks a robot to prepare avocado toast, the task involves several sequential steps. Moreover, such instructions can be ambiguous or infeasible for the robot or may exceed the robot's existing knowledge. While Large Language Models (LLMs) offer strong language reasoning capabilities to handle these challenges, effectively integrating them into robotic systems remains a key challenge. To address this, we propose BT-ACTION, a test-driven approach that combines the modular structure of Behavior Trees (BT) with LLMs to generate coherent sequences of robot actions for following complex user instructions, specifically in the context of preparing recipes in a kitchen-assistance setting. We evaluated BT-ACTION in a comprehensive user study with 45 participants, comparing its performance to direct LLM prompting. Results demonstrate that the modular design of BT-ACTION helped the robot make fewer mistakes and increased user trust, and participants showed a significant preference for the robot leveraging BT-ACTION. The code is publicly available at https://github.com/1Eggbert7/BT_LLM.
Let's move on: Topic Change in Robot-Facilitated Group Discussions
Apr 02, 2025Robot-moderated group discussions have the potential to facilitate engaging and productive interactions among human participants. Previous work on topic management in conversational agents has predominantly focused on human engagement and topic personalization, with the agent having an active role in the discussion. Also, studies have shown the usefulness of including robots in groups, yet further exploration is still needed for robots to learn when to change the topic while facilitating discussions. Accordingly, our work investigates the suitability of machine-learning models and audiovisual non-verbal features in predicting appropriate topic changes. We utilized interactions between a robot moderator and human participants, which we annotated and used for extracting acoustic and body language-related features. We provide a detailed analysis of the performance of machine learning approaches using sequential and non-sequential data with different sets of features. The results indicate promising performance in classifying inappropriate topic changes, outperforming rule-based approaches. Additionally, acoustic features exhibited comparable performance and robustness compared to the complete set of multimodal features. Our annotated data is publicly available at https://github.com/ghadj/topic-change-robot-discussions-data-2024.
* 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
Streaming Network for Continual Learning of Object Relocations under Household Context Drifts
Nov 08, 2024



In most applications, robots need to adapt to new environments and be multi-functional without forgetting previous information. This requirement gains further importance in real-world scenarios where robots operate in coexistence with humans. In these complex environments, human actions inevitably lead to changes, requiring robots to adapt accordingly. To effectively address these dynamics, the concept of continual learning proves essential. It not only enables learning models to integrate new knowledge while preserving existing information but also facilitates the acquisition of insights from diverse contexts. This aspect is particularly relevant to the issue of context-switching, where robots must navigate and adapt to changing situational dynamics. Our approach introduces a novel approach to effectively tackle the problem of context drifts by designing a Streaming Graph Neural Network that incorporates both regularization and rehearsal techniques. Our Continual\_GTM model enables us to retain previous knowledge from different contexts, and it is more effective than traditional fine-tuning approaches. We evaluated the efficacy of Continual\_GTM in predicting human routines within household environments, leveraging spatio-temporal object dynamics across diverse scenarios.
GRACE: Generating Socially Appropriate Robot Actions Leveraging LLMs and Human Explanations
Sep 25, 2024



When operating in human environments, robots need to handle complex tasks while both adhering to social norms and accommodating individual preferences. For instance, based on common sense knowledge, a household robot can predict that it should avoid vacuuming during a social gathering, but it may still be uncertain whether it should vacuum before or after having guests. In such cases, integrating common-sense knowledge with human preferences, often conveyed through human explanations, is fundamental yet a challenge for existing systems. In this paper, we introduce GRACE, a novel approach addressing this while generating socially appropriate robot actions. GRACE leverages common sense knowledge from Large Language Models (LLMs), and it integrates this knowledge with human explanations through a generative network architecture. The bidirectional structure of GRACE enables robots to refine and enhance LLM predictions by utilizing human explanations and makes robots capable of generating such explanations for human-specified actions. Our experimental evaluations show that integrating human explanations boosts GRACE's performance, where it outperforms several baselines and provides sensible explanations.