 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Robustness and Generalization: A k* Distribution Analysis of Concept Clustering in Latent Space for Vision Models
Aug 17, 2024



Most evaluations of vision models use indirect methods to assess latent space quality. These methods often involve adding extra layers to project the latent space into a new one. This projection makes it difficult to analyze and compare the original latent space. This article uses the k* Distribution, a local neighborhood analysis method, to examine the learned latent space at the level of individual concepts, which can be extended to examine the entire latent space. We introduce skewness-based true and approximate metrics for interpreting individual concepts to assess the overall quality of vision models' latent space. Our findings indicate that current vision models frequently fracture the distributions of individual concepts within the latent space. Nevertheless, as these models improve in generalization across multiple datasets, the degree of fracturing diminishes. A similar trend is observed in robust vision models, where increased robustness correlates with reduced fracturing. Ultimately, this approach enables a direct interpretation and comparison of the latent spaces of different vision models and reveals a relationship between a model's generalizability and robustness. Results show that as a model becomes more general and robust, it tends to learn features that result in better clustering of concepts. Project Website is available online at https://shashankkotyan.github.io/k-Distribution/
Beyond KV Caching: Shared Attention for Efficient LLMs
Jul 13, 2024The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Adapting to Covariate Shift in Real-time by Encoding Trees with Motion Equations
Apr 08, 2024



Input distribution shift presents a significant problem in many real-world systems. Here we present Xenovert, an adaptive algorithm that can dynamically adapt to changes in input distribution. It is a perfect binary tree that adaptively divides a continuous input space into several intervals of uniform density while receiving a continuous stream of input. This process indirectly maps the source distribution to the shifted target distribution, preserving the data's relationship with the downstream decoder/operation, even after the shift occurs. In this paper, we demonstrated how a neural network integrated with Xenovert achieved better results in 4 out of 5 shifted datasets, saving the hurdle of retraining a machine learning model. We anticipate that Xenovert can be applied to many more applications that require adaptation to unforeseen input distribution shifts, even when the distribution shift is drastic.
Attention-Driven Reasoning: Unlocking the Potential of Large Language Models
Apr 05, 2024



Large Language Models (LLMs) have shown remarkable capabilities, but their reasoning abilities and underlying mechanisms remain poorly understood. We present a novel approach to enhance LLMs' reasoning through attention mechanism optimization, without additional training data. We identify inefficiencies in the attention distribution caused by non-semantic tokens and propose an algorithm to re-balance the skewed distribution, enabling the model to abstract more nuanced knowledge. Our experiments demonstrate significantly improved reasoning capabilities, particularly for non-STEM questions. We provide insights into the role of attention patterns in LLMs' reasoning and propose a method to enhance these abilities, paving the way for more powerful and versatile language models.
EvoSeed: Unveiling the Threat on Deep Neural Networks with Real-World Illusions
Feb 07, 2024
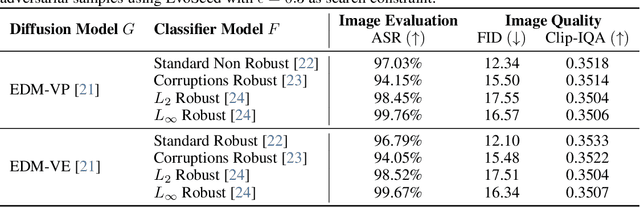
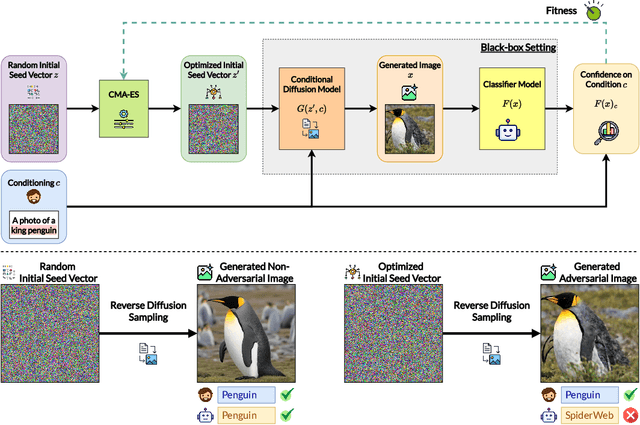
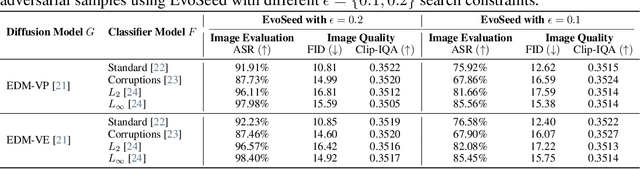
Deep neural networks are exploited using natural adversarial samples, which have no impact on human perception but are misclassified. Current approaches often rely on the white-box nature of deep neural networks to generate these adversarial samples or alter the distribution of adversarial samples compared to training distribution. To alleviate the limitations of current approaches, we propose EvoSeed, a novel evolutionary strategy-based search algorithmic framework to generate natural adversarial samples. Our EvoSeed framework uses auxiliary Diffusion and Classifier models to operate in a model-agnostic black-box setting. We employ CMA-ES to optimize the search for an adversarial seed vector, which, when processed by the Conditional Diffusion Model, results in an unrestricted natural adversarial sample misclassified by the Classifier Model. Experiments show that generated adversarial images are of high image quality and are transferable to different classifiers. Our approach demonstrates promise in enhancing the quality of adversarial samples using evolutionary algorithms. We hope our research opens new avenues to enhance the robustness of deep neural networks in real-world scenarios. Project Website can be accessed at \url{https://shashankkotyan.github.io/EvoSeed}.
k* Distribution: Evaluating the Latent Space of Deep Neural Networks using Local Neighborhood Analysis
Dec 07, 2023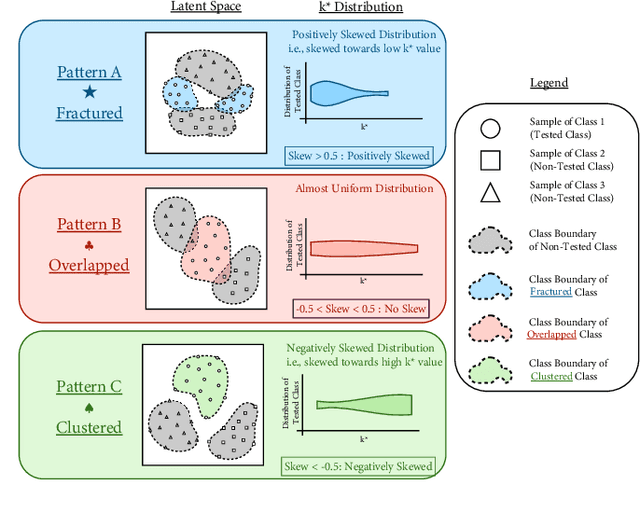

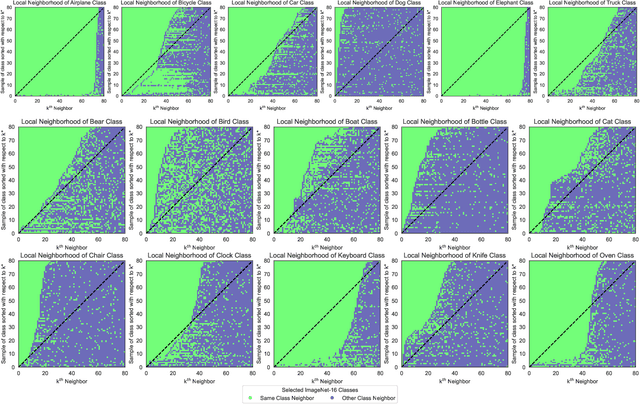

Most examinations of neural networks' learned latent spaces typically employ dimensionality reduction techniques such as t-SNE or UMAP. While these methods effectively capture the overall sample distribution in the entire learned latent space, they tend to distort the structure of sample distributions within specific classes in the subset of the latent space. This distortion complicates the task of easily distinguishing classes identifiable by neural networks. In response to this challenge, we introduce the k* Distribution methodology. This approach focuses on capturing the characteristics and structure of sample distributions for individual classes within the subset of the learned latent space using local neighborhood analysis. The key concept is to facilitate easy comparison of different k* distributions, enabling analysis of how various classes are processed by the same neural network. This provides a more profound understanding of existing contemporary visualizations. Our study reveals three distinct distributions of samples within the learned latent space subset: a) Fractured, b) Overlapped, and c) Clustered. We note and demonstrate that the distribution of samples within the network's learned latent space significantly varies depending on the class. Furthermore, we illustrate that our analysis can be applied to explore the latent space of diverse neural network architectures, various layers within neural networks, transformations applied to input samples, and the distribution of training and testing data for neural networks. We anticipate that our approach will facilitate more targeted investigations into neural networks by collectively examining the distribution of different samples within the learned latent space.
The Challenges of Image Generation Models in Generating Multi-Component Images
Nov 22, 2023



Recent advances in text-to-image generators have led to substantial capabilities in image generation. However, the complexity of prompts acts as a bottleneck in the quality of images generated. A particular under-explored facet is the ability of generative models to create high-quality images comprising multiple components given as a prior. In this paper, we propose and validate a metric called Components Inclusion Score (CIS) to evaluate the extent to which a model can correctly generate multiple components. Our results reveal that the evaluated models struggle to incorporate all the visual elements from prompts with multiple components (8.53% drop in CIS per component for all evaluated models). We also identify a significant decline in the quality of the images and context awareness within an image as the number of components increased (15.91% decrease in inception Score and 9.62% increase in Frechet Inception Distance). To remedy this issue, we fine-tuned Stable Diffusion V2 on a custom-created test dataset with multiple components, outperforming its vanilla counterpart. To conclude, these findings reveal a critical limitation in existing text-to-image generators, shedding light on the challenge of generating multiple components within a single image using a complex prompt.
Towards Improving Robustness Against Common Corruptions using Mixture of Class Specific Experts
Nov 16, 2023

Neural networks have demonstrated significant accuracy across various domains, yet their vulnerability to subtle input alterations remains a persistent challenge. Conventional methods like data augmentation, while effective to some extent, fall short in addressing unforeseen corruptions, limiting the adaptability of neural networks in real-world scenarios. In response, this paper introduces a novel paradigm known as the Mixture of Class-Specific Expert Architecture. The approach involves disentangling feature learning for individual classes, offering a nuanced enhancement in scalability and overall performance. By training dedicated network segments for each class and subsequently aggregating their outputs, the proposed architecture aims to mitigate vulnerabilities associated with common neural network structures. The study underscores the importance of comprehensive evaluation methodologies, advocating for the incorporation of benchmarks like the common corruptions benchmark. This inclusion provides nuanced insights into the vulnerabilities of neural networks, especially concerning their generalization capabilities and robustness to unforeseen distortions. The research aligns with the broader objective of advancing the development of highly robust learning systems capable of nuanced reasoning across diverse and challenging real-world scenarios. Through this contribution, the paper aims to foster a deeper understanding of neural network limitations and proposes a practical approach to enhance their resilience in the face of evolving and unpredictable conditions.
Towards Improving Robustness Against Common Corruptions in Object Detectors Using Adversarial Contrastive Learning
Nov 14, 2023Neural networks have revolutionized various domains, exhibiting remarkable accuracy in tasks like natural language processing and computer vision. However, their vulnerability to slight alterations in input samples poses challenges, particularly in safety-critical applications like autonomous driving. Current approaches, such as introducing distortions during training, fall short in addressing unforeseen corruptions. This paper proposes an innovative adversarial contrastive learning framework to enhance neural network robustness simultaneously against adversarial attacks and common corruptions. By generating instance-wise adversarial examples and optimizing contrastive loss, our method fosters representations that resist adversarial perturbations and remain robust in real-world scenarios. Subsequent contrastive learning then strengthens the similarity between clean samples and their adversarial counterparts, fostering representations resistant to both adversarial attacks and common distortions. By focusing on improving performance under adversarial and real-world conditions, our approach aims to bolster the robustness of neural networks in safety-critical applications, such as autonomous vehicles navigating unpredictable weather conditions. We anticipate that this framework will contribute to advancing the reliability of neural networks in challenging environments, facilitating their widespread adoption in mission-critical scenarios.
Improving Robustness for Vision Transformer with a Simple Dynamic Scanning Augmentation
Nov 01, 2023



Vision Transformer (ViT) has demonstrated promising performance in computer vision tasks, comparable to state-of-the-art neural networks. Yet, this new type of deep neural network architecture is vulnerable to adversarial attacks limiting its capabilities in terms of robustness. This article presents a novel contribution aimed at further improving the accuracy and robustness of ViT, particularly in the face of adversarial attacks. We propose an augmentation technique called `Dynamic Scanning Augmentation' that leverages dynamic input sequences to adaptively focus on different patches, thereby maintaining performance and robustness. Our detailed investigations reveal that this adaptability to the input sequence induces significant changes in the attention mechanism of ViT, even for the same image. We introduce four variations of Dynamic Scanning Augmentation, outperforming ViT in terms of both robustness to adversarial attacks and accuracy against natural images, with one variant showing comparable results. By integrating our augmentation technique, we observe a substantial increase in ViT's robustness, improving it from $17\%$ to $92\%$ measured across different types of adversarial attacks. These findings, together with other comprehensive tests, indicate that Dynamic Scanning Augmentation enhances accuracy and robustness by promoting a more adaptive type of attention. In conclusion, this work contributes to the ongoing research on Vision Transformers by introducing Dynamic Scanning Augmentation as a technique for improving the accuracy and robustness of ViT. The observed results highlight the potential of this approach in advancing computer vision tasks and merit further exploration in future studies.