 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond KV Caching: Shared Attention for Efficient LLMs
Jul 13, 2024The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Attention-Driven Reasoning: Unlocking the Potential of Large Language Models
Apr 05, 2024



Large Language Models (LLMs) have shown remarkable capabilities, but their reasoning abilities and underlying mechanisms remain poorly understood. We present a novel approach to enhance LLMs' reasoning through attention mechanism optimization, without additional training data. We identify inefficiencies in the attention distribution caused by non-semantic tokens and propose an algorithm to re-balance the skewed distribution, enabling the model to abstract more nuanced knowledge. Our experiments demonstrate significantly improved reasoning capabilities, particularly for non-STEM questions. We provide insights into the role of attention patterns in LLMs' reasoning and propose a method to enhance these abilities, paving the way for more powerful and versatile language models.
Perceptual Deep Neural Networks: Adversarial Robustness through Input Recreation
Sep 08, 2020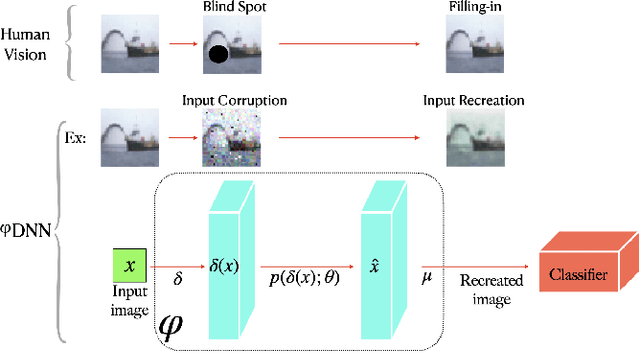
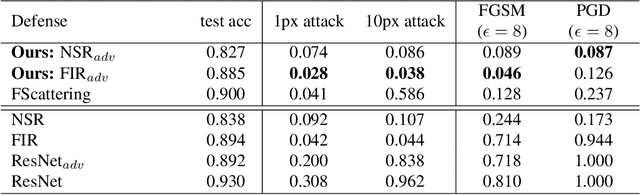
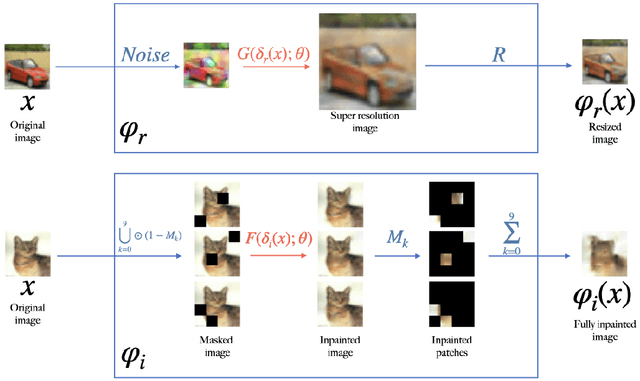
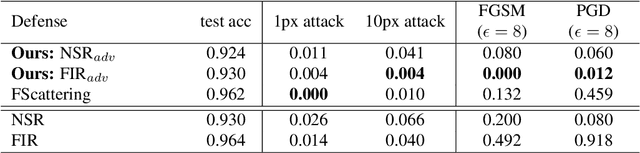
Adversarial examples have shown that albeit highly accurate, models learned by machines, differently from humans,have many weaknesses. However, humans' perception is also fundamentally different from machines, because we do not see the signals which arrive at the retina but a rather complex recreation of them. In this paper, we explore how machines could recreate the input as well as investigate the benefits of such an augmented perception. In this regard, we propose Perceptual Deep Neural Networks ($\varphi$DNN) which also recreate their own input before further processing. The concept is formalized mathematically and two variations of it are developed (one based on inpainting the whole image and the other based on a noisy resized super resolution recreation). Experiments reveal that $\varphi$DNNs can reduce attacks' accuracy substantially, surpassing state-of-the-art defenses in 87% of the tests for adversarial training variations and 100% of the tests when only comparing with other pre-processing type of defenses. Moreover, the recreation process intentionally corrupts the input image. Interestingly, we show by ablation tests that corrupting the input is, although counter-intuitive,beneficial. This suggests that the blind-spot in vertebrates might also be, analogously, the precursor of visual robustness. Thus, $\varphi$DNNs reveal that input recreation has strong benefits for artificial neural networks similar to biological ones, shedding light into the importance of the blind-spot and starting an area of perception models for robust recognition in artificial intelligence.