 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Multi-view and Temporal Fusing Transformer for 3D Human Pose Estimation
Paper and Code
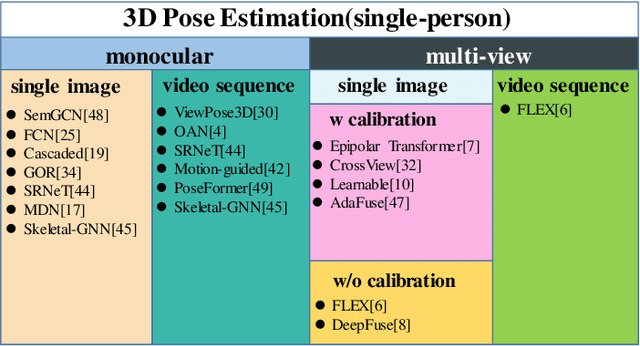
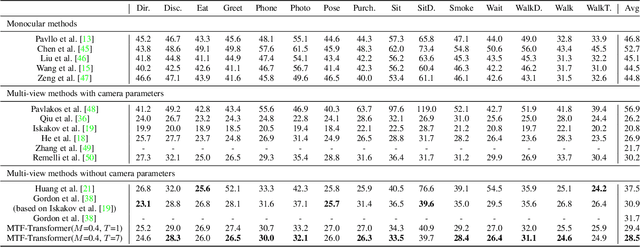
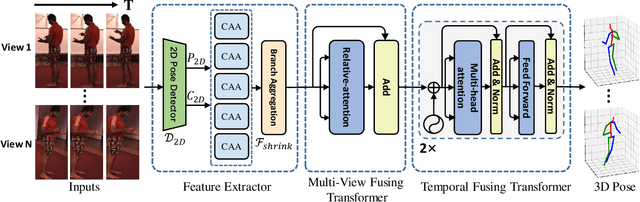

In practical application, 3D Human Pose Estimation (HPE) is facing with several variable elements, involving the number of views, the length of the video sequence, and whether using camera calibration. To this end, we propose a unified framework named Multi-view and Temporal Fusing Transformer (MTF-Transformer) to adaptively handle varying view numbers and video length without calibration. MTF-Transformer consists of Feature Extractor, Multi-view Fusing Transformer (MFT), and Temporal Fusing Transformer (TFT). Feature Extractor estimates the 2D pose from each image and encodes the predicted coordinates and confidence into feature embedding for further 3D pose inference. It discards the image features and focuses on lifting the 2D pose into the 3D pose, making the subsequent modules computationally lightweight enough to handle videos. MFT fuses the features of a varying number of views with a relative-attention block. It adaptively measures the implicit relationship between each pair of views and reconstructs the features. TFT aggregates the features of the whole sequence and predicts 3D pose via a transformer, which is adaptive to the length of the video and takes full advantage of the temporal information. With these modules, MTF-Transformer handles different application scenes, varying from a monocular-single-image to multi-view-video, and the camera calibration is avoidable. We demonstrate quantitative and qualitative results on the Human3.6M, TotalCapture, and KTH Multiview Football II. Compared with state-of-the-art methods with camera parameters, experiments show that MTF-Transformer not only obtains comparable results but also generalizes well to dynamic capture with an arbitrary number of unseen views. Code is available in https://github.com/lelexx/MTF-Transformer.