 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgRoCC: A Progressive Approach to Rough Crowd Counting
Paper and Code
Apr 18, 2025
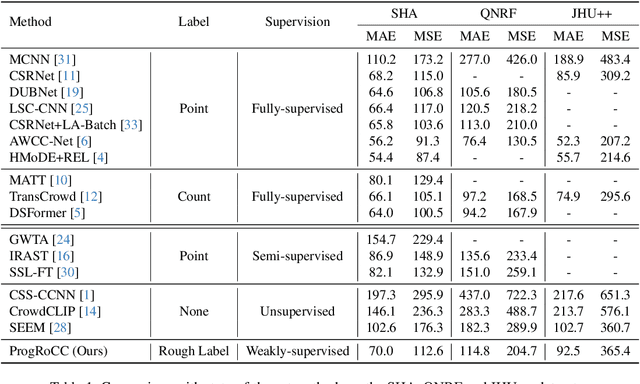
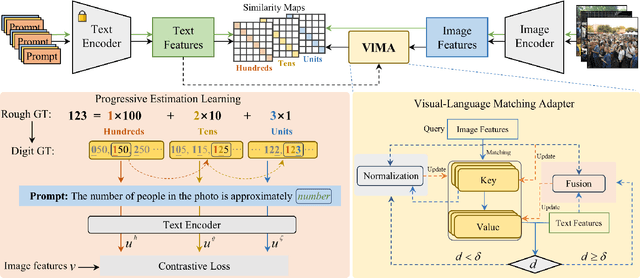

As the number of individuals in a crowd grows, enumeration-based techniques become increasingly infeasible and their estimates increasingly unreliable. We propose instead an estimation-based version of the problem: we label Rough Crowd Counting that delivers better accuracy on the basis of training data that is easier to acquire. Rough crowd counting requires only rough annotations of the number of targets in an image, instead of the more traditional, and far more expensive, per-target annotations. We propose an approach to the rough crowd counting problem based on CLIP, termed ProgRoCC. Specifically, we introduce a progressive estimation learning strategy that determines the object count through a coarse-to-fine approach. This approach delivers answers quickly, outperforms the state-of-the-art in semi- and weakly-supervised crowd counting. In addition, we design a vision-language matching adapter that optimizes key-value pairs by mining effective matches of two modalities to refine the visual features, thereby improving the final performance. Extensive experimental results on three widely adopted crowd counting datasets demonstrate the effectiveness of our method.