 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
SALAD-Pan: Sensor-Agnostic Latent Adaptive Diffusion for Pan-Sharpening
Feb 04, 2026Recently, diffusion models bring novel insights for Pan-sharpening and notably boost fusion precision. However, most existing models perform diffusion in the pixel space and train distinct models for different multispectral (MS) imagery, suffering from high latency and sensor-specific limitations. In this paper, we present SALAD-Pan, a sensor-agnostic latent space diffusion method for efficient pansharpening. Specifically, SALAD-Pan trains a band-wise single-channel VAE to encode high-resolution multispectral (HRMS) into compact latent representations, supporting MS images with various channel counts and establishing a basis for acceleration. Then spectral physical properties, along with PAN and MS images, are injected into the diffusion backbone through unidirectional and bidirectional interactive control structures respectively, achieving high-precision fusion in the diffusion process. Finally, a lightweight cross-spectral attention module is added to the central layer of diffusion model, reinforcing spectral connections to boost spectral consistency and further elevate fusion precision. Experimental results on GaoFen-2, QuickBird, and WorldView-3 demonstrate that SALAD-Pan outperforms state-of-the-art diffusion-based methods across all three datasets, attains a 2-3x inference speedup, and exhibits robust zero-shot (cross-sensor) capability.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025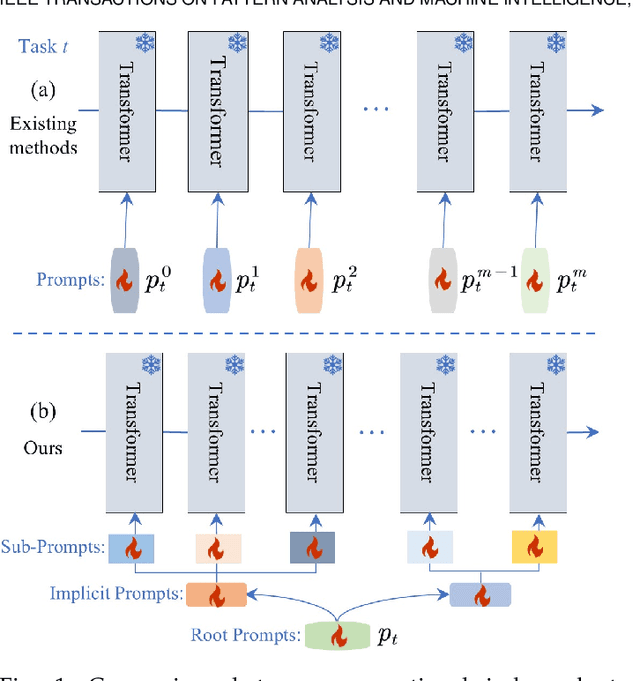
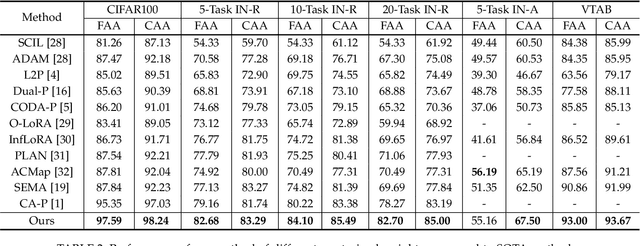
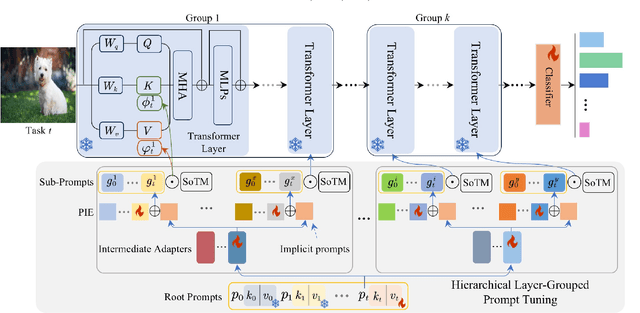
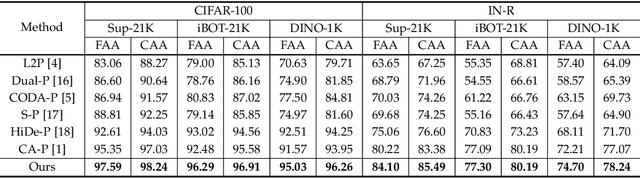
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.
ProgRoCC: A Progressive Approach to Rough Crowd Counting
Apr 18, 2025
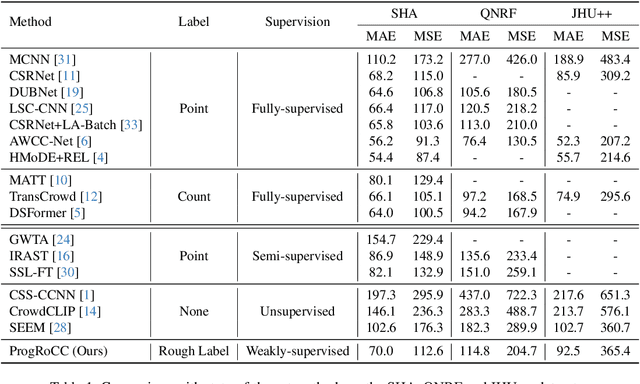
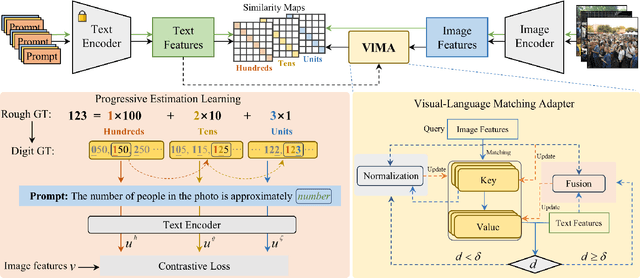

As the number of individuals in a crowd grows, enumeration-based techniques become increasingly infeasible and their estimates increasingly unreliable. We propose instead an estimation-based version of the problem: we label Rough Crowd Counting that delivers better accuracy on the basis of training data that is easier to acquire. Rough crowd counting requires only rough annotations of the number of targets in an image, instead of the more traditional, and far more expensive, per-target annotations. We propose an approach to the rough crowd counting problem based on CLIP, termed ProgRoCC. Specifically, we introduce a progressive estimation learning strategy that determines the object count through a coarse-to-fine approach. This approach delivers answers quickly, outperforms the state-of-the-art in semi- and weakly-supervised crowd counting. In addition, we design a vision-language matching adapter that optimizes key-value pairs by mining effective matches of two modalities to refine the visual features, thereby improving the final performance. Extensive experimental results on three widely adopted crowd counting datasets demonstrate the effectiveness of our method.
Teacher Agent: A Non-Knowledge Distillation Method for Rehearsal-based Video Incremental Learning
Jun 01, 2023



With the rise in popularity of video-based social media, new categories of videos are constantly being generated, creating an urgent need for robust incremental learning techniques for video understanding. One of the biggest challenges in this task is catastrophic forgetting, where the network tends to forget previously learned data while learning new categories. To overcome this issue, knowledge distillation is a widely used technique for rehearsal-based video incremental learning that involves transferring important information on similarities among different categories to enhance the student model. Therefore, it is preferable to have a strong teacher model to guide the students. However, the limited performance of the network itself and the occurrence of catastrophic forgetting can result in the teacher network making inaccurate predictions for some memory exemplars, ultimately limiting the student network's performance. Based on these observations, we propose a teacher agent capable of generating stable and accurate soft labels to replace the output of the teacher model. This method circumvents the problem of knowledge misleading caused by inaccurate predictions of the teacher model and avoids the computational overhead of loading the teacher model for knowledge distillation. Extensive experiments demonstrate the advantages of our method, yielding significant performance improvements while utilizing only half the resolution of video clips in the incremental phases as input compared to recent state-of-the-art methods. Moreover, our method surpasses the performance of joint training when employing four times the number of samples in episodic memory.
Crowd Counting with Online Knowledge Learning
Mar 18, 2023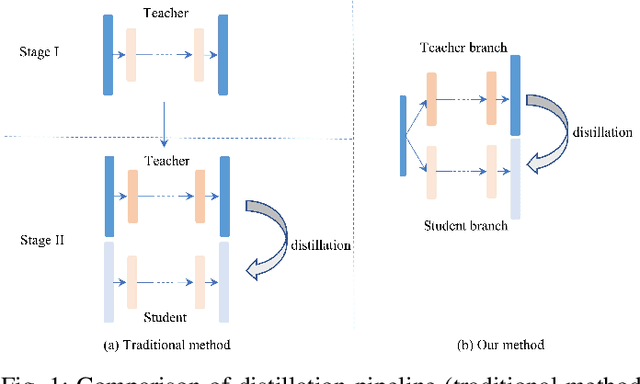
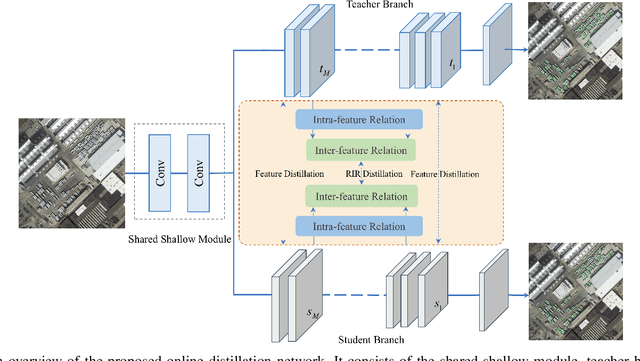
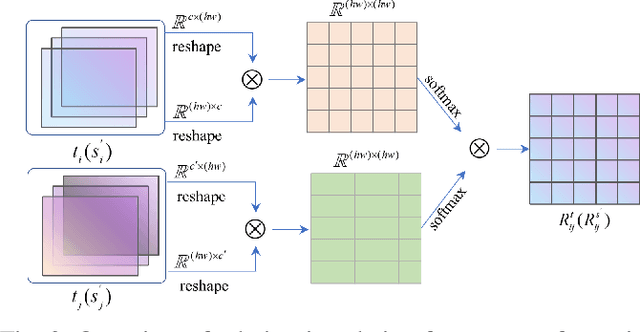
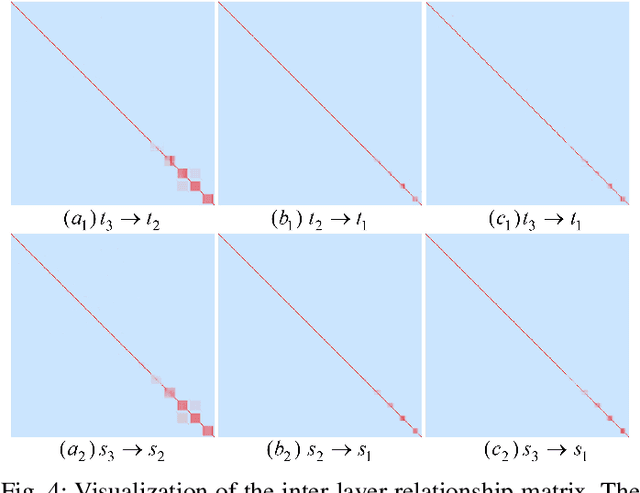
Efficient crowd counting models are urgently required for the applications in scenarios with limited computing resources, such as edge computing and mobile devices. A straightforward method to achieve this is knowledge distillation (KD), which involves using a trained teacher network to guide the training of a student network. However, this traditional two-phase training method can be time-consuming, particularly for large datasets, and it is also challenging for the student network to mimic the learning process of the teacher network. To overcome these challenges, we propose an online knowledge learning method for crowd counting. Our method builds an end-to-end training framework that integrates two independent networks into a single architecture, which consists of a shared shallow module, a teacher branch, and a student branch. This approach is more efficient than the two-stage training technique of traditional KD. Moreover, we propose a feature relation distillation method which allows the student branch to more effectively comprehend the evolution of inter-layer features by constructing a new inter-layer relationship matrix. It is combined with response distillation and feature internal distillation to enhance the transfer of mutually complementary information from the teacher branch to the student branch. Extensive experiments on four challenging crowd counting datasets demonstrate the effectiveness of our method which achieves comparable performance to state-of-the-art methods despite using far fewer parameters.
A Unified Object Counting Network with Object Occupation Prior
Dec 29, 2022


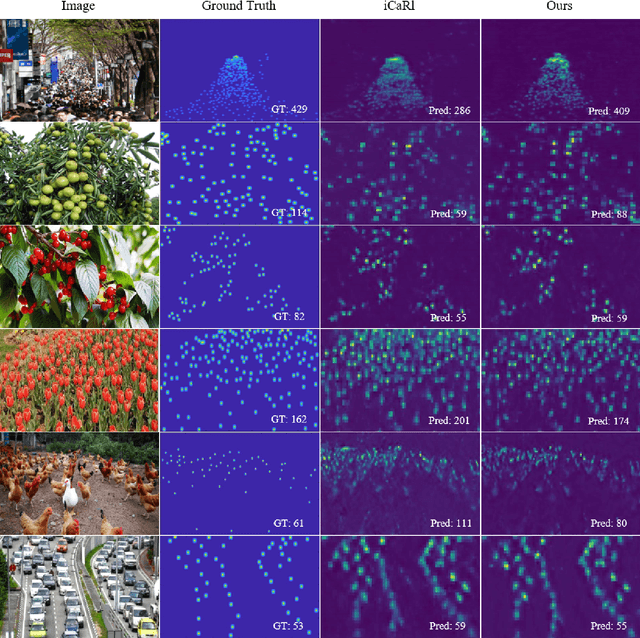
The counting task, which plays a fundamental rule in numerous applications (e.g., crowd counting, traffic statistics), aims to predict the number of objects with various densities. Existing object counting tasks are designed for a single object class. However, it is inevitable to encounter newly coming data with new classes in our real world. We name this scenario as \textit{evolving object counting}. In this paper, we build the first evolving object counting dataset and propose a unified object counting network as the first attempt to address this task. The proposed model consists of two key components: a class-agnostic mask module and a class-increment module. The class-agnostic mask module learns generic object occupation prior via predicting a class-agnostic binary mask (e.g., 1 denotes there exists an object at the considering position in an image and 0 otherwise). The class-increment module is used to handle new coming classes and provides discriminative class guidance for density map prediction. The combined outputs of class-agnostic mask module and image feature extractor are used to predict the final density map. When new classes come, we first add new neural nodes into the last regression and classification layers of this module. Then, instead of retraining the model from scratch, we utilize knowledge distilling to help the model remember what have already learned about previous object classes. We also employ a support sample bank to store a small number of typical training samples of each class, which are used to prevent the model from forgetting key information of old data. With this design, our model can efficiently and effectively adapt to new coming classes while keeping good performance on already seen data without large-scale retraining. Extensive experiments on the collected dataset demonstrate the favorable performance.
Mask-aware networks for crowd counting
Dec 18, 2018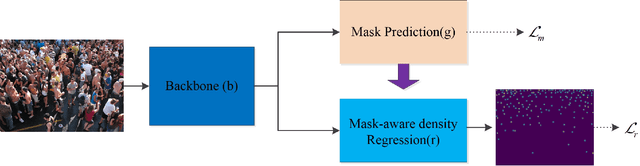
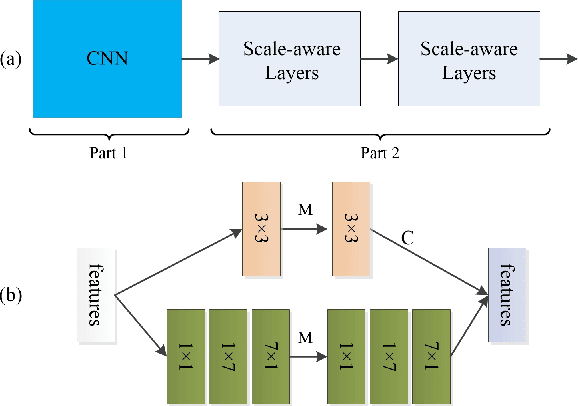
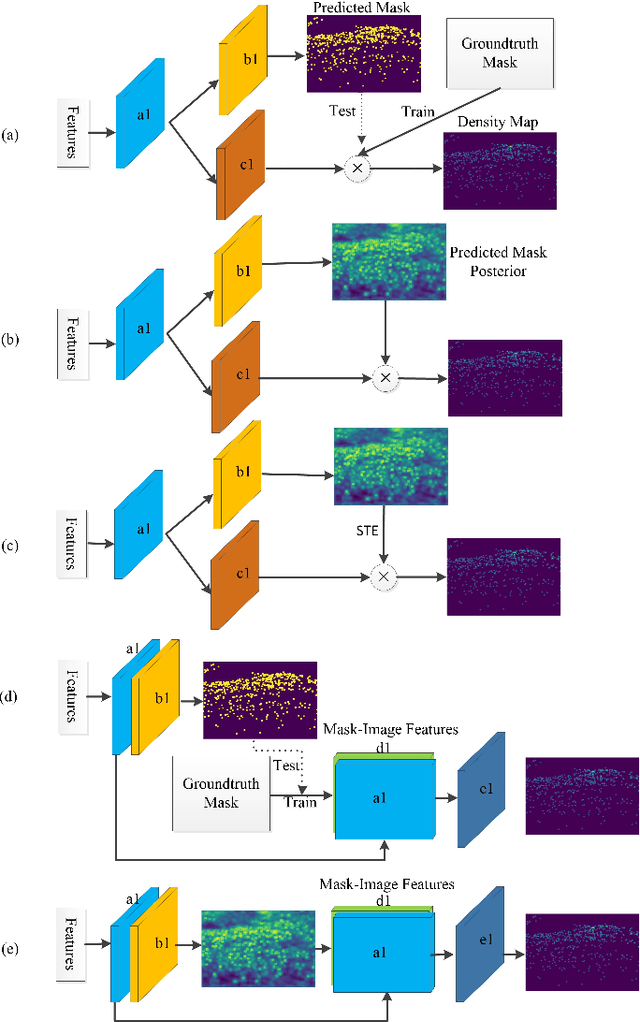

Crowd counting problem aims to count the number of objects within an image or a frame in the videos and is usually solved by estimating the density map generated from the object location annotations. The values in the density map, by nature, take two possible states: zero indicating no object around, a non-zero value indicating the existence of objects and the value denoting the local object density. In contrast to traditional methods which do not differentiate the density prediction of these two states, we propose to use a dedicated network branch to predict the object/non-object mask and then combine its prediction with the input image to produce the density map. Our rationale is that the mask prediction could be better modeled as a binary segmentation problem and the difficulty of estimating the density could be reduced if the mask is known. A key to the proposed scheme is the strategy of incorporating the mask prediction into the density map estimator. To this end, we study five possible solutions, and via analysis and experimental validation we identify the most effective one. Through extensive experiments on five public datasets, we demonstrate the superior performance of the proposed approach over the baselines and show that our network could achieve the state-of-the-art performance.