 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd Counting with Online Knowledge Learning
Mar 18, 2023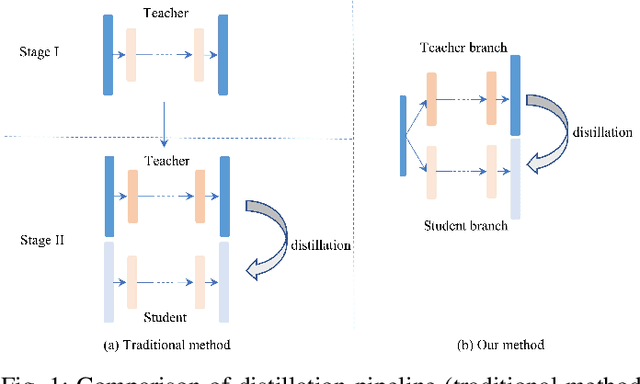
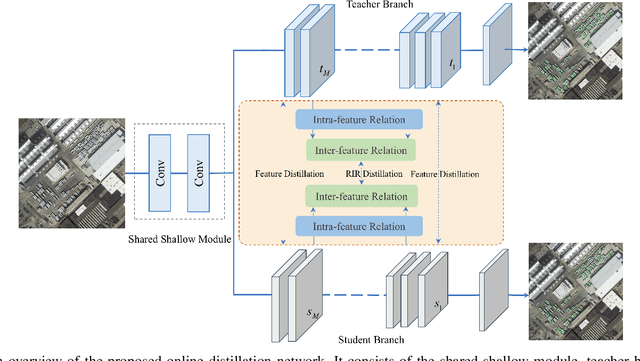
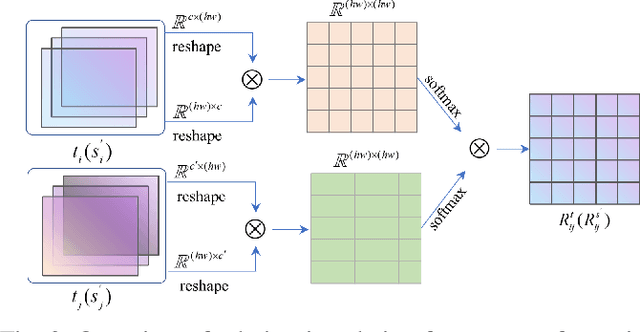
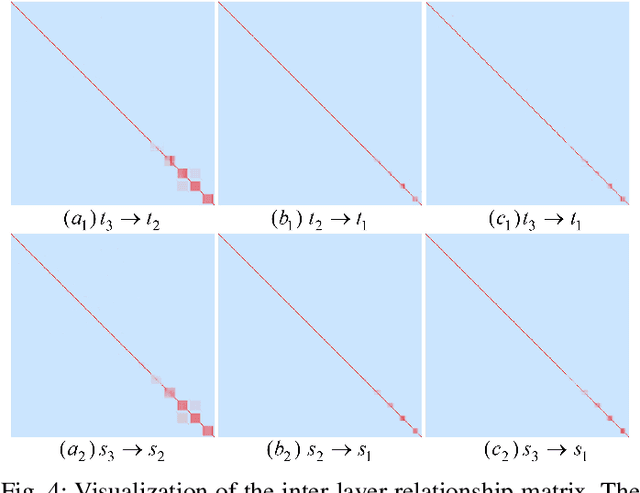
Efficient crowd counting models are urgently required for the applications in scenarios with limited computing resources, such as edge computing and mobile devices. A straightforward method to achieve this is knowledge distillation (KD), which involves using a trained teacher network to guide the training of a student network. However, this traditional two-phase training method can be time-consuming, particularly for large datasets, and it is also challenging for the student network to mimic the learning process of the teacher network. To overcome these challenges, we propose an online knowledge learning method for crowd counting. Our method builds an end-to-end training framework that integrates two independent networks into a single architecture, which consists of a shared shallow module, a teacher branch, and a student branch. This approach is more efficient than the two-stage training technique of traditional KD. Moreover, we propose a feature relation distillation method which allows the student branch to more effectively comprehend the evolution of inter-layer features by constructing a new inter-layer relationship matrix. It is combined with response distillation and feature internal distillation to enhance the transfer of mutually complementary information from the teacher branch to the student branch. Extensive experiments on four challenging crowd counting datasets demonstrate the effectiveness of our method which achieves comparable performance to state-of-the-art methods despite using far fewer parameters.
A Unified Object Counting Network with Object Occupation Prior
Dec 29, 2022


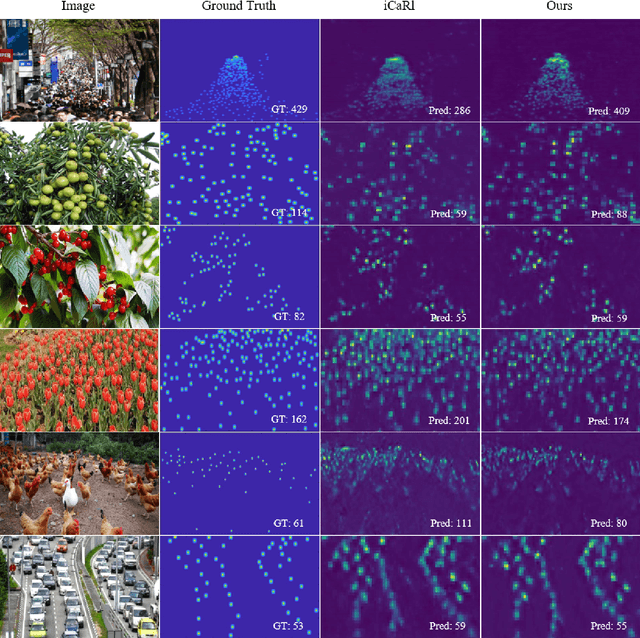
The counting task, which plays a fundamental rule in numerous applications (e.g., crowd counting, traffic statistics), aims to predict the number of objects with various densities. Existing object counting tasks are designed for a single object class. However, it is inevitable to encounter newly coming data with new classes in our real world. We name this scenario as \textit{evolving object counting}. In this paper, we build the first evolving object counting dataset and propose a unified object counting network as the first attempt to address this task. The proposed model consists of two key components: a class-agnostic mask module and a class-increment module. The class-agnostic mask module learns generic object occupation prior via predicting a class-agnostic binary mask (e.g., 1 denotes there exists an object at the considering position in an image and 0 otherwise). The class-increment module is used to handle new coming classes and provides discriminative class guidance for density map prediction. The combined outputs of class-agnostic mask module and image feature extractor are used to predict the final density map. When new classes come, we first add new neural nodes into the last regression and classification layers of this module. Then, instead of retraining the model from scratch, we utilize knowledge distilling to help the model remember what have already learned about previous object classes. We also employ a support sample bank to store a small number of typical training samples of each class, which are used to prevent the model from forgetting key information of old data. With this design, our model can efficiently and effectively adapt to new coming classes while keeping good performance on already seen data without large-scale retraining. Extensive experiments on the collected dataset demonstrate the favorable performance.