 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid-Attention Guided Network with Multiple Resolution Features for Person Re-Identification
Sep 16, 2020
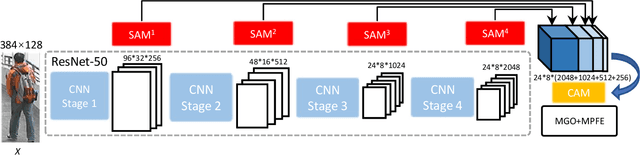
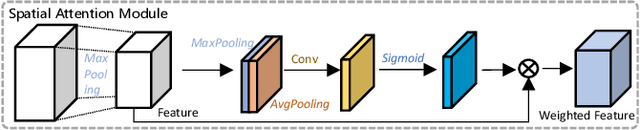

Extracting effective and discriminative features is very important for addressing the challenging person re-identification (re-ID) task. Prevailing deep convolutional neural networks (CNNs) usually use high-level features for identifying pedestrian. However, some essential spatial information resided in low-level features such as shape, texture and color will be lost when learning the high-level features, due to extensive padding and pooling operations in the training stage. In addition, most existing person re-ID methods are mainly based on hand-craft bounding boxes where images are precisely aligned. It is unrealistic in practical applications, since the exploited object detection algorithms often produce inaccurate bounding boxes. This will inevitably degrade the performance of existing algorithms. To address these problems, we put forward a novel person re-ID model that fuses high- and low-level embeddings to reduce the information loss caused in learning high-level features. Then we divide the fused embedding into several parts and reconnect them to obtain the global feature and more significant local features, so as to alleviate the affect caused by the inaccurate bounding boxes. In addition, we also introduce the spatial and channel attention mechanisms in our model, which aims to mine more discriminative features related to the target. Finally, we reconstruct the feature extractor to ensure that our model can obtain more richer and robust features. Extensive experiments display the superiority of our approach compared with existing approaches. Our code is available at https://github.com/libraflower/MutipleFeature-for-PRID.