 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Cloud-Free Optical Image Synthesis Using Multi-Temporal SAR and Contaminated Optical Data
Apr 23, 2025Addressing gaps caused by cloud cover and the long revisit cycle of satellites is vital for providing essential data to support remote sensing applications. This paper tackles the challenges of missing optical data synthesis, particularly in complex scenarios with cloud cover. We propose CRSynthNet, a novel image synthesis network that incorporates innovative designed modules such as the DownUp Block and Fusion Attention to enhance accuracy. Experimental results validate the effectiveness of CRSynthNet, demonstrating substantial improvements in restoring structural details, preserving spectral consist, and achieving superior visual effects that far exceed those produced by comparison methods. It achieves quantitative improvements across multiple metrics: a peak signal-to-noise ratio (PSNR) of 26.978, a structural similarity index measure (SSIM) of 0.648, and a root mean square error (RMSE) of 0.050. Furthermore, this study creates the TCSEN12 dataset, a valuable resource specifically designed to address cloud cover challenges in missing optical data synthesis study. The dataset uniquely includes cloud-covered images and leverages earlier image to predict later image, offering a realistic representation of real-world scenarios. This study offer practical method and valuable resources for optical satellite image synthesis task.
Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation
Oct 13, 2021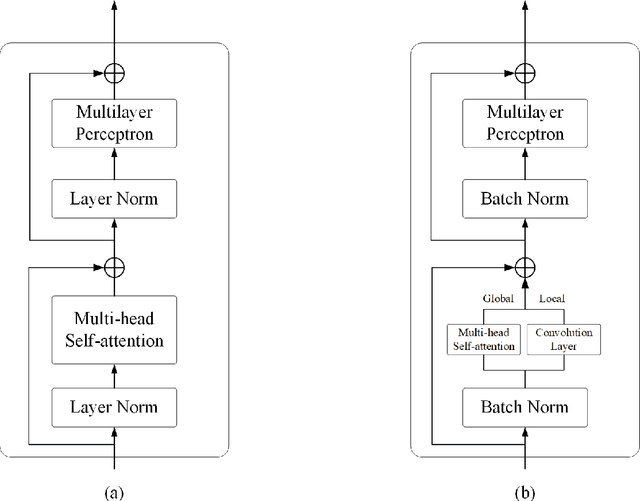

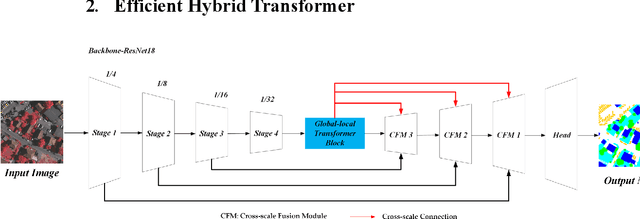
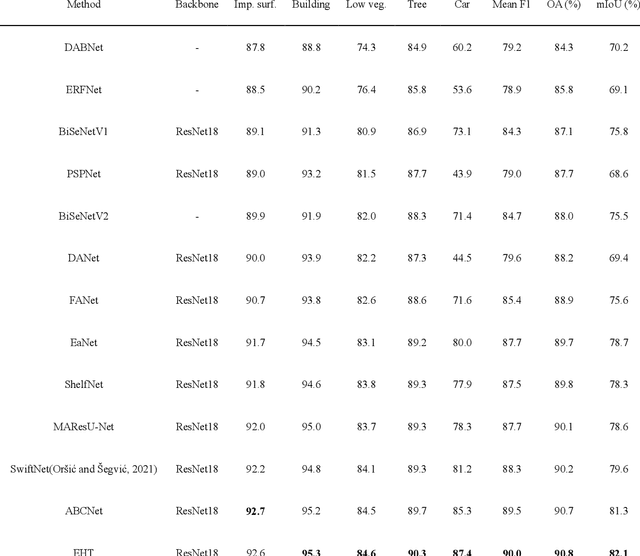
Semantic segmentation of fine-resolution urban scene images plays a vital role in extensive practical applications, such as land cover mapping, urban change detection, environmental protection and economic assessment. Driven by rapid developments in deep learning technologies, the convolutional neural network (CNN) has dominated the semantic segmentation task for many years. Convolutional neural networks adopt hierarchical feature representation, demonstrating strong local information extraction. However, the local property of the convolution layer limits the network from capturing global context that is crucial for precise segmentation. Recently, Transformer comprise a hot topic in the computer vision domain. Transformer demonstrates the great capability of global information modelling, boosting many vision tasks, such as image classification, object detection and especially semantic segmentation. In this paper, we propose an efficient hybrid Transformer (EHT) for real-time urban scene segmentation. The EHT adopts a hybrid structure with and CNN-based encoder and a transformer-based decoder, learning global-local context with lower computation. Extensive experiments demonstrate that our EHT has faster inference speed with competitive accuracy compared with state-of-the-art lightweight models. Specifically, the proposed EHT achieves a 66.9% mIoU on the UAVid test set and outperforms other benchmark networks significantly. The code will be available soon.
Transformer Meets Convolution: A Bilateral Awareness Net-work for Semantic Segmentation of Very Fine Resolution Ur-ban Scene Images
Jun 23, 2021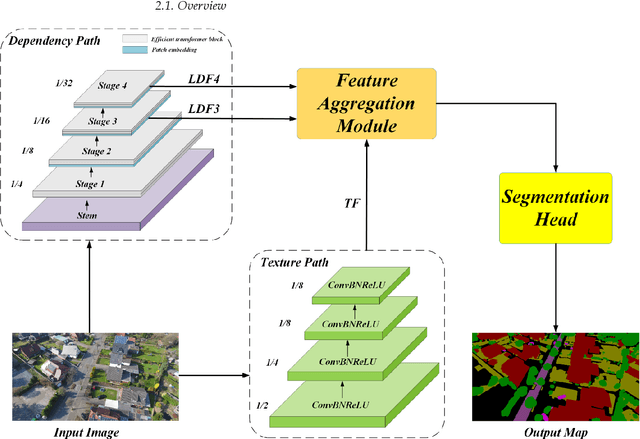
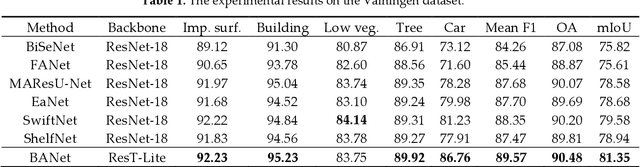
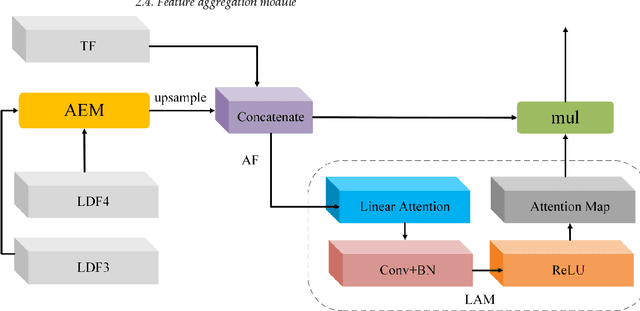
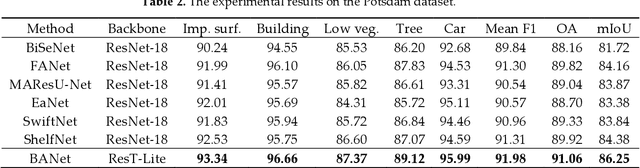
Semantic segmentation from very fine resolution (VFR) urban scene images plays a significant role in several application scenarios including autonomous driving, land cover classification, and urban planning, etc. However, the tremendous details contained in the VFR image severely limit the potential of the existing deep learning approaches. More seriously, the considerable variations in scale and appearance of objects further deteriorate the representational capacity of those se-mantic segmentation methods, leading to the confusion of adjacent objects. Addressing such is-sues represents a promising research field in the remote sensing community, which paves the way for scene-level landscape pattern analysis and decision making. In this manuscript, we pro-pose a bilateral awareness network (BANet) which contains a dependency path and a texture path to fully capture the long-range relationships and fine-grained details in VFR images. Specif-ically, the dependency path is conducted based on the ResT, a novel Transformer backbone with memory-efficient multi-head self-attention, while the texture path is built on the stacked convo-lution operation. Besides, using the linear attention mechanism, a feature aggregation module (FAM) is designed to effectively fuse the dependency features and texture features. Extensive experiments conducted on the three large-scale urban scene image segmentation datasets, i.e., ISPRS Vaihingen dataset, ISPRS Potsdam dataset, and UAVid dataset, demonstrate the effective-ness of our BANet. Specifically, a 64.6% mIoU is achieved on the UAVid dataset.
A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
May 11, 2021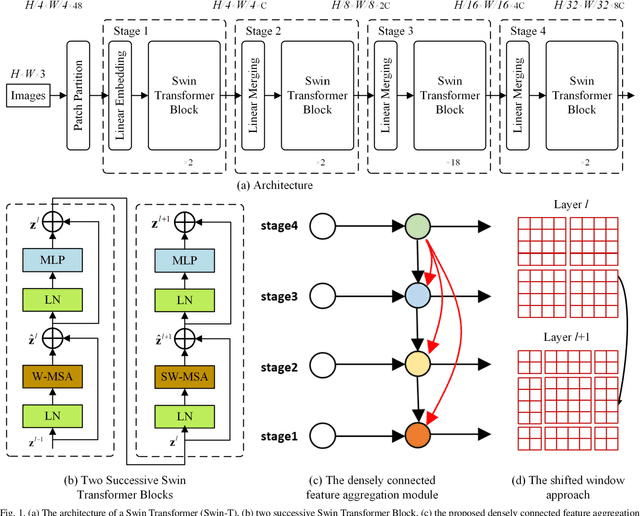
The fully-convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multi-level feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavours are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we propose the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.
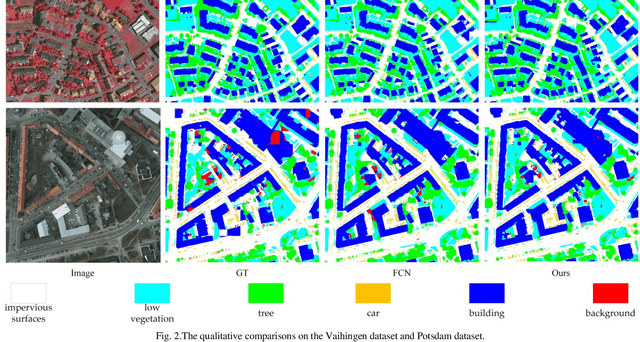
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021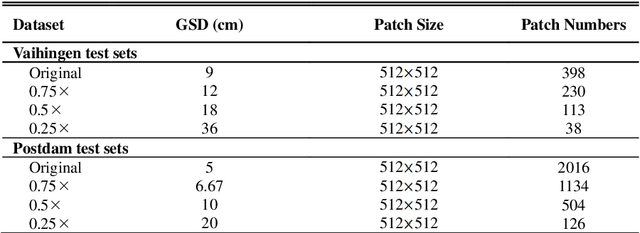


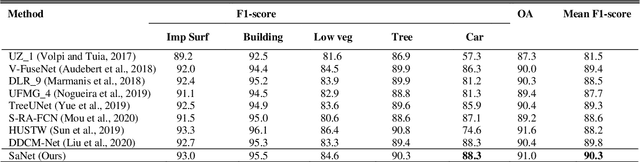
Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).
Feature Pyramid Network with Multi-Head Attention for Semantic Segmentation of Fine-Resolution Remotely Sensed Images
Feb 19, 2021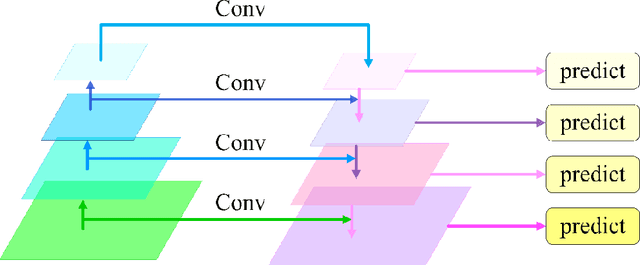
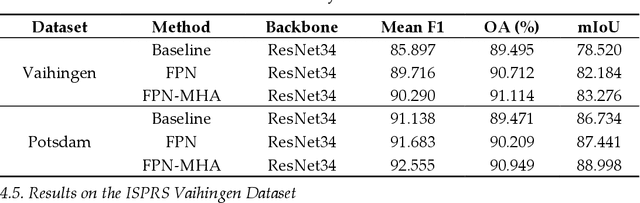
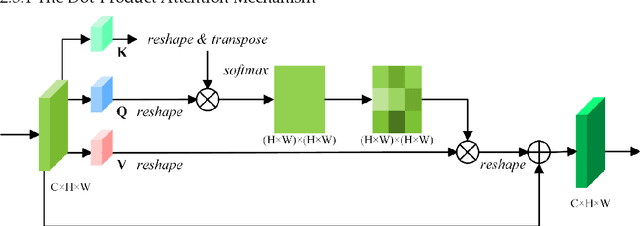
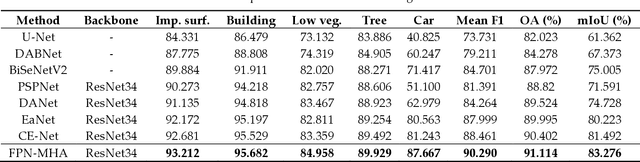
Semantic segmentation from fine-resolution remotely sensed images is an urgent issue in satellite imagery processing. Due to the complicated environment, automatic categorization and segmen-tation is a challenging matter especially for images with a fine resolution. Solving it can help to surmount a wide varied range of obstacles in urban planning, environmental protection, and natural landscape monitoring, which paves the way for complete scene understanding. However, the existing frequently-used encoder-decoder structure is unable to effectively combine the extracted spatial and contextual features. Therefore, in this paper, we introduce the Feature Pyramid Net-work (FPN) to bridge the gap between the low-level and high-level features. Moreover, we enhance the contextual information with the elaborate Multi-Head Attention module and propose the Feature Pyramid Network with Multi-Head Attention (FPN-MHA) for semantic segmentation of fine-resolution remotely sensed images. Extensive experiments conducted on the ISPRS Potsdam and Vaihingen datasets demonstrate the effectiveness of our FPN-MHA. Code is available at https://github.com/lironui/FPN-MHA.
ABCNet: Attentive Bilateral Contextual Network for Efficient Semantic Segmentation of Fine-Resolution Remote Sensing Images
Feb 04, 2021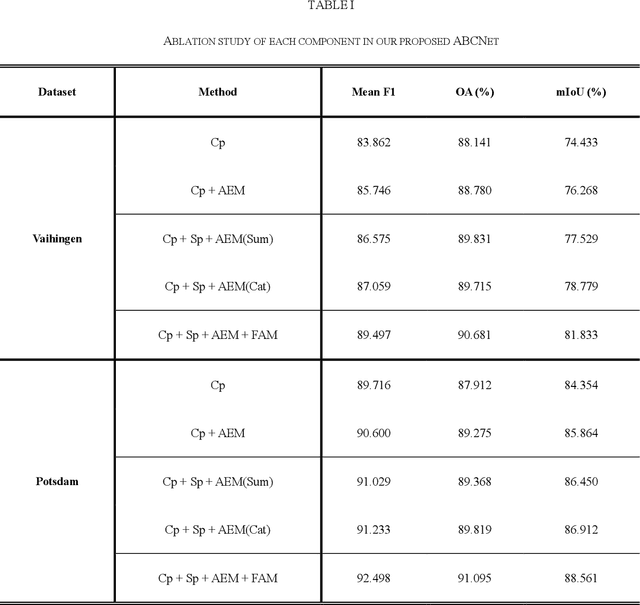
Semantic segmentation of remotely sensed images plays a crucial role in precision agriculture, environmental protection, and economic assessment. In recent years, substantial fine-resolution remote sensing images are available for semantic segmentation. However, due to the complicated information caused by the increased spatial resolution, state-of-the-art deep learning algorithms normally utilize complex network architectures for segmentation, which usually incurs high computational complexity. Specifically, the high-caliber performance of the convolutional neural network (CNN) heavily relies on fine-grained spatial details (fine resolution) and sufficient contextual information (large receptive fields), both of which trigger high computational costs. This crucially impedes their practicability and availability in real-world scenarios that require real-time processing. In this paper, we propose an Attentive Bilateral Contextual Network (ABCNet), a convolutional neural network (CNN) with double branches, with prominently lower computational consumptions compared to the cutting-edge algorithms, while maintaining a competitive accuracy. Code is available at https://github.com/lironui/ABCNet.
Multi-Head Linear Attention Generative Adversarial Network for Thin Cloud Removal
Dec 20, 2020


In remote sensing images, the existence of the thin cloud is an inevitable and ubiquitous phenomenon that crucially reduces the quality of imageries and limits the scenarios of application. Therefore, thin cloud removal is an indispensable procedure to enhance the utilization of remote sensing images. Generally, even though contaminated by thin clouds, the pixels still retain more or less surface information. Hence, different from thick cloud removal, thin cloud removal algorithms normally concentrate on inhibiting the cloud influence rather than substituting the cloud-contaminated pixels. Meanwhile, considering the surface features obscured by the cloud are usually similar to adjacent areas, the dependency between each pixel of the input is useful to reconstruct contaminated areas. In this paper, to make full use of the dependencies between pixels of the image, we propose a Multi-Head Linear Attention Generative Adversarial Network (MLAGAN) for Thin Cloud Removal. The MLA-GAN is based on the encoding-decoding framework consisting of multiple attention-based layers and deconvolutional layers. Compared with six deep learning-based thin cloud removal benchmarks, the experimental results on the RICE1 and RICE2 datasets demonstrate that the proposed framework MLA-GAN has dominant advantages in thin cloud removal.
Multi-stage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images
Dec 01, 2020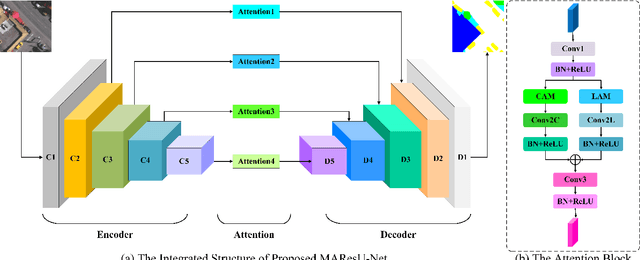
The attention mechanism can refine the extracted feature maps and boost the classification performance of the deep network, which has become an essential technique in computer vision and natural language processing. However, the memory and computational costs of the dot-product attention mechanism increase quadratically with the spatio-temporal size of the input. Such growth hinders the usage of attention mechanisms considerably in application scenarios with large-scale inputs. In this Letter, we propose a Linear Attention Mechanism (LAM) to address this issue, which is approximately equivalent to dot-product attention with computational efficiency. Such a design makes the incorporation between attention mechanisms and deep networks much more flexible and versatile. Based on the proposed LAM, we re-factor the skip connections in the raw U-Net and design a Multi-stage Attention ResU-Net (MAResU-Net) for semantic segmentation from fine-resolution remote sensing images. Experiments conducted on the Vaihingen dataset demonstrated the effectiveness and efficiency of our MAResU-Net. Open-source code is available at https://github.com/lironui/Multistage-Attention-ResU-Net.
Multi-Attention-Network for Semantic Segmentation of High-Resolution Remote Sensing Images
Sep 03, 2020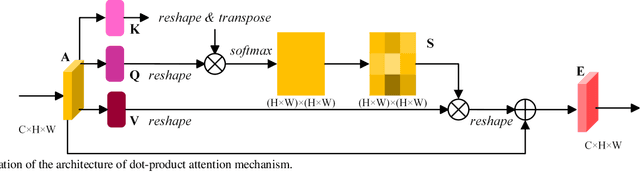
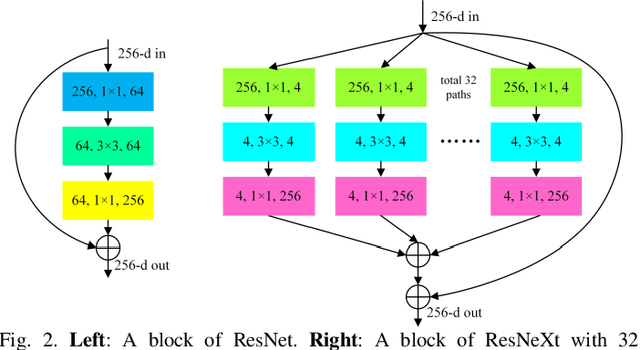
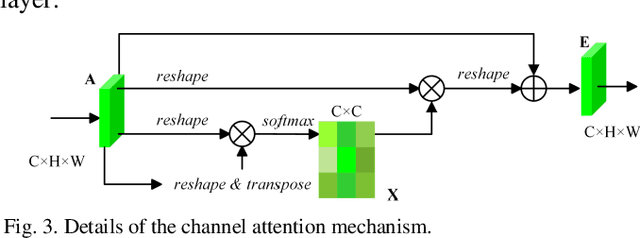
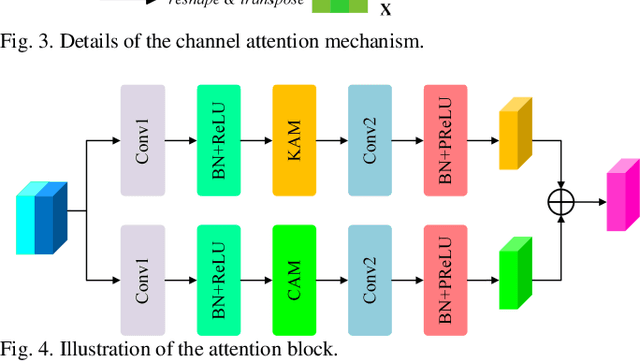
Semantic segmentation of remote sensing images plays an important role in land resource management, yield estimation, and economic assessment. Even though the semantic segmentation of remote sensing images has been prominently improved by convolutional neural networks, there are still several limitations contained in standard models. First, for encoder-decoder architectures like U-Net, the utilization of multi-scale features causes overuse of information, where similar low-level features are exploited at multiple scales for multiple times. Second, long-range dependencies of feature maps are not sufficiently explored, leading to feature representations associated with each semantic class are not optimal. Third, despite the dot-product attention mechanism has been introduced and harnessed widely in semantic segmentation to model long-range dependencies, the high time and space complexities of attention impede the usage of attention in application scenarios with large input. In this paper, we proposed a Multi-Attention-Network (MANet) to remedy these drawbacks, which extracts contextual dependencies by multi efficient attention mechanisms. A novel attention mechanism named kernel attention with linear complexity is proposed to alleviate the high computational demand of attention. Based on kernel attention and channel attention, we integrate local feature maps extracted by ResNeXt-101 with their corresponding global dependencies, and adaptively signalize interdependent channel maps. Experiments conducted on two remote sensing image datasets captured by variant satellites demonstrate that the performance of our MANet transcends the DeepLab V3+, PSPNet, FastFCN, and other baseline algorithms.