 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Chagas Disease from the ECG: The George B. Moody PhysioNet Challenge 2025
Oct 02, 2025Objective: Chagas disease is a parasitic infection that is endemic to South America, Central America, and, more recently, the U.S., primarily transmitted by insects. Chronic Chagas disease can cause cardiovascular diseases and digestive problems. Serological testing capacities for Chagas disease are limited, but Chagas cardiomyopathy often manifests in ECGs, providing an opportunity to prioritize patients for testing and treatment. Approach: The George B. Moody PhysioNet Challenge 2025 invites teams to develop algorithmic approaches for identifying Chagas disease from electrocardiograms (ECGs). Main results: This Challenge provides multiple innovations. First, we leveraged several datasets with labels from patient reports and serological testing, provided a large dataset with weak labels and smaller datasets with strong labels. Second, we augmented the data to support model robustness and generalizability to unseen data sources. Third, we applied an evaluation metric that captured the local serological testing capacity for Chagas disease to frame the machine learning problem as a triage task. Significance: Over 630 participants from 111 teams submitted over 1300 entries during the Challenge, representing diverse approaches from academia and industry worldwide.
ECG-Image-Database: A Dataset of ECG Images with Real-World Imaging and Scanning Artifacts; A Foundation for Computerized ECG Image Digitization and Analysis
Sep 25, 2024

We introduce the ECG-Image-Database, a large and diverse collection of electrocardiogram (ECG) images generated from ECG time-series data, with real-world scanning, imaging, and physical artifacts. We used ECG-Image-Kit, an open-source Python toolkit, to generate realistic images of 12-lead ECG printouts from raw ECG time-series. The images include realistic distortions such as noise, wrinkles, stains, and perspective shifts, generated both digitally and physically. The toolkit was applied to 977 12-lead ECG records from the PTB-XL database and 1,000 from Emory Healthcare to create high-fidelity synthetic ECG images. These unique images were subjected to both programmatic distortions using ECG-Image-Kit and physical effects like soaking, staining, and mold growth, followed by scanning and photography under various lighting conditions to create real-world artifacts. The resulting dataset includes 35,595 software-labeled ECG images with a wide range of imaging artifacts and distortions. The dataset provides ground truth time-series data alongside the images, offering a reference for developing machine and deep learning models for ECG digitization and classification. The images vary in quality, from clear scans of clean papers to noisy photographs of degraded papers, enabling the development of more generalizable digitization algorithms. ECG-Image-Database addresses a critical need for digitizing paper-based and non-digital ECGs for computerized analysis, providing a foundation for developing robust machine and deep learning models capable of converting ECG images into time-series. The dataset aims to serve as a reference for ECG digitization and computerized annotation efforts. ECG-Image-Database was used in the PhysioNet Challenge 2024 on ECG image digitization and classification.
Beyond Heart Murmur Detection: Automatic Murmur Grading from Phonocardiogram
Sep 27, 2022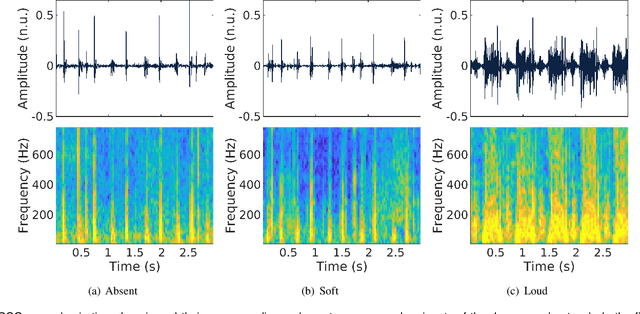
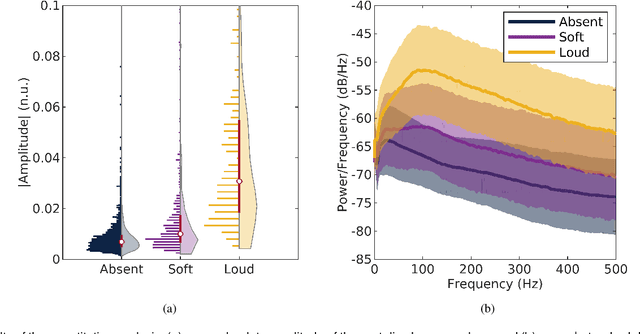
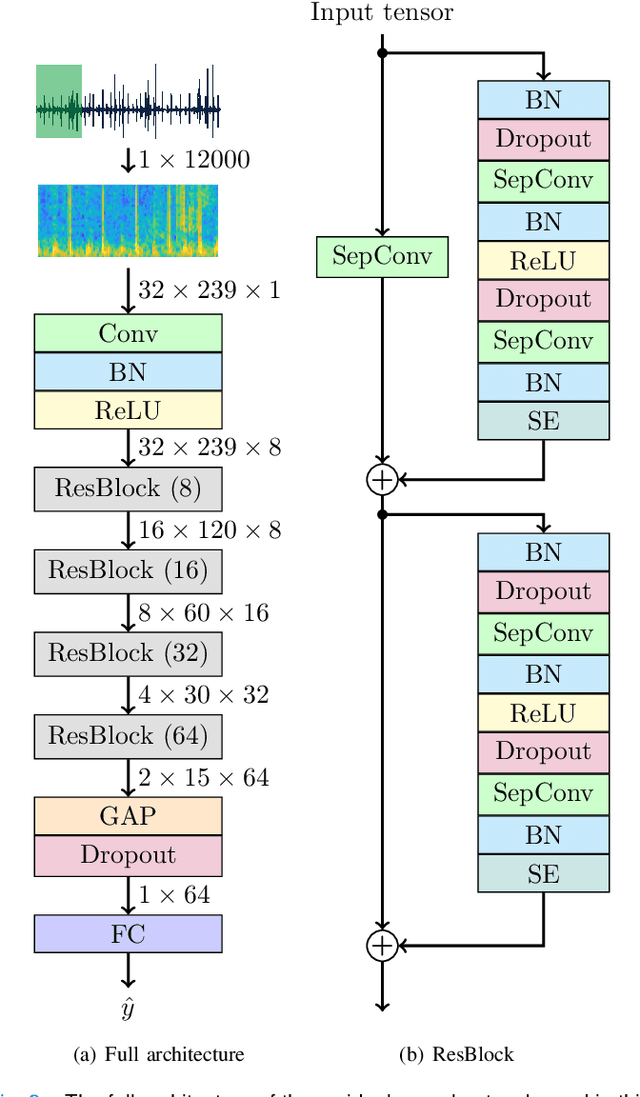
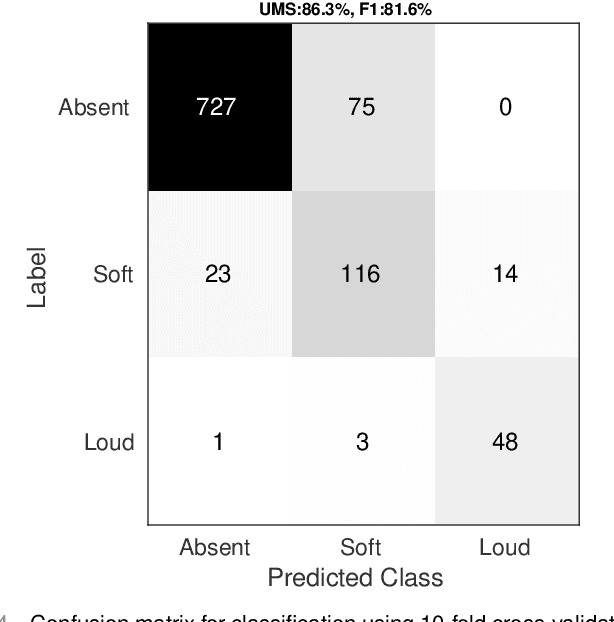
Objective: Murmurs are abnormal heart sounds, identified by experts through cardiac auscultation. The murmur grade, a quantitative measure of the murmur intensity, is strongly correlated with the patient's clinical condition. This work aims to estimate each patient's murmur grade (i.e., absent, soft, loud) from multiple auscultation location phonocardiograms (PCGs) of a large population of pediatric patients from a low-resource rural area. Methods: The Mel spectrogram representation of each PCG recording is given to an ensemble of 15 convolutional residual neural networks with channel-wise attention mechanisms to classify each PCG recording. The final murmur grade for each patient is derived based on the proposed decision rule and considering all estimated labels for available recordings. The proposed method is cross-validated on a dataset consisting of 3456 PCG recordings from 1007 patients using a stratified ten-fold cross-validation. Additionally, the method was tested on a hidden test set comprised of 1538 PCG recordings from 442 patients. Results: The overall cross-validation performances for patient-level murmur gradings are 86.3% and 81.6% in terms of the unweighted average of sensitivities and F1-scores, respectively. The sensitivities (and F1-scores) for absent, soft, and loud murmurs are 90.7% (93.6%), 75.8% (66.8%), and 92.3% (84.2%), respectively. On the test set, the algorithm achieves an unweighted average of sensitivities of 80.4% and an F1-score of 75.8%. Conclusions: This study provides a potential approach for algorithmic pre-screening in low-resource settings with relatively high expert screening costs. Significance: The proposed method represents a significant step beyond detection of murmurs, providing characterization of intensity which may provide a enhanced classification of clinical outcomes.
Voting of predictive models for clinical outcomes: consensus of algorithms for the early prediction of sepsis from clinical data and an analysis of the PhysioNet/Computing in Cardiology Challenge 2019
Dec 20, 2020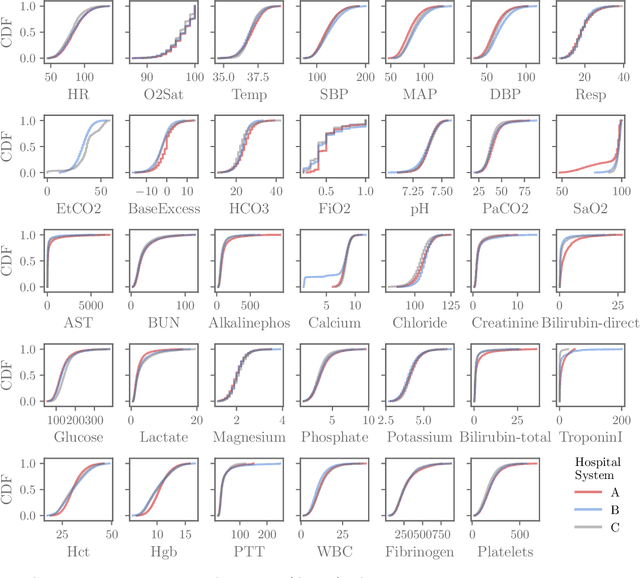



Although there has been significant research in boosting of weak learners, there has been little work in the field of boosting from strong learners. This latter paradigm is a form of weighted voting with learned weights. In this work, we consider the problem of constructing an ensemble algorithm from 70 individual algorithms for the early prediction of sepsis from clinical data. We find that this ensemble algorithm outperforms separate algorithms, especially on a hidden test set on which most algorithms failed to generalize.